tässä opetusohjelmassa aiomme selittää, yhden kehittyvän ja näkyvän word-upotustekniikan nimeltä Word2Vec, jota Mikolov et al ehdotti. vuonna 2013. Olemme keränneet näitä sisältöjä eri tutoriaaleista ja lähteistä helpottamaan lukijoita yhteen paikkaan. Toivottavasti siitä on apua.
Word2vec on sellaisten mallien yhdistelmä, joita käytetään edustamaan sanojen hajautettuja representaatioita korpuksessa C. Word2Vec (W2V) on algoritmi, joka hyväksyy tekstin korpuksen syötteeksi ja tuottaa jokaiselle sanalle vektoriesityksen, kuten alla olevassa kaaviossa on esitetty:

on olemassa kaksi makua tämän algoritmin nimittäin: CBOW ja Skip-Gram. Koska joukko lauseita (kutsutaan myös corpus) mallin silmukoita sanoja kunkin lauseen ja joko yrittää käyttää nykyistä sanaa w voidakseen ennustaa sen naapurit (eli sen yhteydessä), tätä lähestymistapaa kutsutaan ”Skip-Gram”, tai se käyttää kutakin näistä yhteyksistä ennustaa nykyisen sanan w, siinä tapauksessa menetelmää kutsutaan ”jatkuva pussi sanoja” (CBOW). Sanojen määrän rajoittamiseksi kussakin asiayhteydessä käytetään parametria nimeltä ”ikkunan koko”.

vektoreita, joita käytämme edustamaan sanoja, kutsutaan neuraalisiksi sanavalinnoiksi, ja representaatiot ovat outoja. Yksi asia kuvaa toista, vaikka nuo kaksi asiaa ovat radikaalisti erilaisia. Kuten Elvis Costello sanoi: ”musiikista kirjoittaminen on kuin tanssisi arkkitehtuurista.”Word2vec” vectorizes ” sanoista, ja näin se tekee luonnollisesta kielestä tietokoneella luettavan — voimme alkaa suorittaa tehokkaita matemaattisia operaatioita sanoille havaitaksemme niiden yhtäläisyydet.
niin, neuraalinen sanavalinta edustaa sanaa, jossa on numeroita. Se on yksinkertainen, mutta epätodennäköinen käännös. Word2vec on samanlainen kuin automaattikooderi, joka koodaa jokaisen sanan vektorissa, mutta sen sijaan, että harjoittelisi tulosanoja vastaan rekonstruktion kautta, kuten rajoitettu Boltzmannin kone tekee, word2vec kouluttaa sanoja muita sanoja vastaan, jotka naapureina ne tulokomponentissa.
se tekee sen kahdella tavalla, joko käyttämällä kontekstia kohdesanan ennustamiseen (menetelmä tunnetaan nimellä jatkuva sanapussi tai CBOW), tai käyttämällä sanaa kohdekontekstin ennustamiseen, jota kutsutaan skip-grammiksi. Käytämme jälkimmäistä menetelmää, koska se tuottaa tarkempia tuloksia suurissa tietokokonaisuuksissa.

kun sanalle annettua ominaisuusvektoria ei voida käyttää ennustamaan tarkasti kyseisen sanan asiayhteyttä, vektorin komponentit oikaistaan. Jokaisen sanan konteksti korpuksessa on opettaja, joka lähettää virhesignaaleja takaisin ominaisuusvektorin säätämiseksi. Asiayhteytensä perusteella samankaltaisiksi arvioitujen sanojen vektorit tönäistään lähemmäs toisiaan säätämällä vektorin lukuja. Tässä opetusohjelma, aiomme keskittyä Skip-Gram malli, joka toisin kuin CBOW pitävät center sana syötteenä kuten yllä olevassa kuvassa ja ennustaa yhteydessä sanoja.
Model overview
ymmärsimme, että meidän on syötettävä jotain outoa neuroverkkoa joillakin sanapareilla, mutta emme voi tehdä sitä vain käyttämällä syötteinä varsinaisia merkkejä, meidän on löydettävä jokin tapa esittää nämä sanat matemaattisesti, jotta verkko voi käsitellä niitä. Yksi tapa tehdä tämä on luoda sanasto kaikista sanoista tekstissämme ja sitten koodata sanamme vektorina, jolla on samat ulottuvuudet sanastossamme. Jokainen ulottuvuus voidaan ajatella sanavarastossamme olevana sanana. Joten meillä on vektori, jossa on kaikki nollat ja 1, joka edustaa vastaavaa sanaa sanastossa. Tätä koodaustekniikkaa kutsutaan one-hot-koodaukseksi. Ottaen huomioon esimerkkimme, jos meillä on sanasto, joka on tehty sanoista ”the”, ”quick”, ”brown”, ”fox”, ”hyppää”, ”yli”, ”the” ”laiska”, ”koira”, sana ”brown” edustaa tätä vektoria: .

Skip-gram-malli ottaa sisään tekstin korpuksen ja luo jokaiselle sanalle hot-vektorin. Kuuma vektori on sanan vektoriesitys, jossa vektori on sanaston koko (uniikkisanat yhteensä). Kaikki dimensiot on asetettu arvoon 0 lukuun ottamatta dimensiota, joka edustaa sanaa, jota käytetään syötteenä kyseisenä ajankohtana. Tässä on esimerkki kuuma vektori:

yllä oleva tulo annetaan neuroverkolle, jossa on yksi piilokerros.
esitämme tulosanaa, kuten ”muurahaisia”, yhden kuuman vektorin muodossa. Tällä vektorilla on 10 000 komponenttia (yksi jokaista sanastomme sanaa kohti) ja me asetamme ”1” sanan ”muurahaisia” vastaavaan asentoon ja 0s kaikkiin muihin asemiin. Verkon ulostulo on yksi vektori (myös 10 000 komponenttia), joka sisältää jokaista sanastomme sanaa kohti todennäköisyyden, että satunnaisesti valittu lähisana on tuo sanastosana.
word2vecissä käytetään jonkin sanan hajautettua edustusta. Ota vektori, jolla on useita satoja ulottuvuuksia (vaikkapa 1000). Jokaista sanaa edustaa painojakauma näiden alkuaineiden välillä. Sen sijaan, että vektorissa olevan elementin ja sanan välillä olisi yksi yhteen-kartoitus, sanan edustus jakautuu kaikkiin vektorin alkuaineisiin, ja jokainen vektorin alkuaine vaikuttaa monien sanojen määrittelyyn.
jos merkitsen mitat hypoteettisella sanavektorilla (algoritmissa ei tietenkään ole tällaisia ennalta määrättyjä nimikkeitä), se saattaa näyttää vähän tältä:

tällainen vektori tulee edustamaan jollakin abstraktilla tavalla sanan’ merkitystä’. Ja kuten näemme seuraavaksi, yksinkertaisesti tutkimalla suurta korpusta on mahdollista oppia sanavektoreita, jotka pystyvät vangitsemaan sanojen väliset suhteet yllättävän ilmeikkäällä tavalla. Voimme myös käyttää vektoreita syötteinä neuroverkkoon. Koska tulovektorimme ovat yhden kuumia, tulovektorin kertominen painomatriisilla W1 tarkoittaa yksinkertaisesti rivin valitsemista W1: stä.
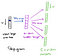

piilokerroksesta ulostulokerrokseen toisen painomatriisin W2 avulla voidaan laskea pisteet jokaiselle sanaston sanalle, ja softmaxin avulla saadaan sanojen posteriorijakauma. Skip-gram-malli on CBOW-mallin vastakohta. Se on konstruoitu siten, että tarkennussana on yksi tulovektori, ja kohdeyhteyssanat ovat nyt lähtötasolla. Aktivointifunktio piilotetulle kerrokselle tarkoittaa yksinkertaisesti sitä, että kopioimme vastaavan rivin painomatriisista W1 (lineaarinen), kuten näimme aiemmin. Klo lähtötaso, nyt tuotamme C monikansalliset jakelut sijaan vain yksi. Koulutuksen tavoitteena on matkia summattu ennustus virhe kaikissa yhteydessä sanoja lähtötason. Esimerkissämme tulo olisi ”oppiminen”, ja toivomme näkevämme (”an”,” tehokas”,” menetelmä”,” for”,” korkea”,” laatu”,” hajautettu”,” vektori”) lähtötasolla.
tässä neuroverkkomme arkkitehtuuri.

esimerkiksi, aiomme sanoa, että olemme oppimisen sana vektorit 300 ominaisuuksia. Piilotettua kerrosta edustaa siis painomatriisi, jossa on 10 000 riviä (yksi jokaista sanastomme sanaa kohti) ja 300 saraketta (yksi jokaista Piilotettua hermosolua kohti). 300 ominaisuudet on mitä Google käytti julkaistussa mallissaan koulutettu Google news dataset (voit ladata sen täältä). Ominaisuuksien määrä on ”hyper-parametri”, joka sinun pitäisi vain virittää sovellukseesi (eli kokeilla erilaisia arvoja ja katsoa, mikä tuottaa parhaat tulokset).
jos tarkastellaan tämän painomatriisin rivejä, niin nämä ovat meidän sanavektorimme!

joten päätavoite kaikki tämä on oikeastaan vain oppia tämä piilotettu kerros paino matriisi-lähtö kerros me vain heittää, kun olemme valmiita! 1 x 300 sanan vektori ”muurahaisia” sitten syötetään lähtö kerros. Ulostulokerros on softmax-regressioluokitin. Erityisesti jokaisella lähtöhermolla on painovektori, jonka se moninkertaistaa piilokerroksen sanavektoria vastaan, jolloin tulokselle sovelletaan funktiota exp(x). Lopuksi, jotta saadaan tuotokset yhteen 1, jaamme tämän tuloksen Kaikkien 10 000 lähdön solmujen tulosten summalla. Tässä on esimerkki lähtöneuronin tuotoksen laskemisesta sanalle ”auto”.

jos kahdella eri sanalla on hyvin samanlaiset ”asiayhteydet” (eli mitä sanoja niiden ympärillä todennäköisesti esiintyy), mallimme on tuotettava hyvin samanlaiset tulokset näille kahdelle sanalle. Ja yksi tapa tuottaa samanlaisia kontekstiennusteita näille kahdelle sanalle on, jos sanavektorit ovat samanlaisia. Joten, jos kahdella sanalla on samanlaiset asiayhteydet, niin verkostomme on motivoitunut oppimaan samanlaisia sanavektoreita näille kahdelle sanalle! Tadaa!
jokainen tulon ulottuvuus kulkee piilokerroksen jokaisen solmun läpi. Ulottuvuus kerrotaan painolla, joka johtaa sen piilokerrokseen. Koska tulo on kuuma vektori, vain yhdellä syötön solmuista on ei-nolla-arvo (eli arvo 1). Tämä tarkoittaa, että sanan kohdalla aktivoidaan vain syöttösolmuun liittyvät painot, joiden arvo on 1, kuten yllä olevassa kuvassa on esitetty.
koska tulo on tässä tapauksessa kuuma vektori, vain yhdellä tulon solmuista on ei-nolla-arvo. Tämä tarkoittaa, että vain kyseiseen syöttösolmuun liitetyt painot aktivoituvat piilotetuissa solmuissa. Esimerkki huomioon otettavista painoista on esitetty alla sanaston toisen sanan osalta:
sanaston toisen sanan vektoriesitys (esitetty yllä olevassa neuroverkossa) näyttää seuraavasti, kun se on aktivoitu piilokerroksessa:
painot alkavat satunnaisarvoina. Verkko on sitten koulutettu, jotta voidaan säätää painot edustamaan syöttösanoja. Tämä on, jos lähtö kerros tulee tärkeä. Nyt kun olemme piilotettu kerros vektoriesitys sana tarvitsemme tapa määrittää, kuinka hyvin olemme ennustaneet, että sana sopii tiettyyn kontekstiin. Asiayhteys sana on joukko sanoja sisällä ikkunan ympärillä, kuten alla:

yllä olevasta kuvasta näkyy, että perjantain asiayhteydessä on muun muassa sanat ”kissa” ja ”on”. Neuroverkon tavoitteena on ennustaa, että” perjantai ” osuu tähän yhteyteen.
aktivoimme lähtökerroksen kertomalla vektorin, jonka ohitimme piilotetun kerroksen läpi (joka oli tulovektori * piilosolmuun tulevat painot) konteksti-sanan vektoriesityksellä (joka on konteksti-sanan kuuma vektori * lähtösolmuun tulevat painot). Ensimmäisen kontekstisanan tulostustason tila voidaan visualisoida alla:

yllä oleva kertolasku tehdään jokaiselle sanalle kontekstiin sanapari. Tämän jälkeen lasketaan todennäköisyys, että sana kuuluu kontekstisanojen joukkoon käyttäen Piilo-ja lähtökerroksista johtuvia arvoja. Lopuksi käytämme stokastista gradienttia laskeutumista painojen arvojen muuttamiseksi, jotta saadaan lasketulle todennäköisyydelle toivottavampi arvo.
gradienttilaskennassa on laskettava optimoitavan funktion gradientti siinä pisteessä, joka edustaa muuttuvaa painoa. Tämän jälkeen gradientin avulla valitaan suunta, jossa siirrytään kohti paikallista optimia, kuten alla olevassa minimointiesimerkissä osoitetaan.
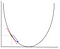
painoa muutetaan tekemällä askel optimipisteen suuntaan (yllä olevassa esimerkissä kuvaajan alin kohta). Uusi arvo lasketaan vähentämällä nykyisestä painoarvosta oppimistahdin skaalaaman painon pisteessä oleva johdettu funktio. Seuraava askel on käyttämällä Backpropagation, säätää painot välillä useita kerroksia. Tulostuskerroksen lopussa laskettu virhe johdetaan takaisin lähtökerroksesta piilotetulle tasolle soveltamalla Ketjusääntöä. Gradientin laskeutumista käytetään näiden kahden kerroksen välisten painojen päivittämiseen. Virhe säädetään sitten jokaisessa kerroksessa ja lähetetään takaisin edelleen. Tässä on kaavio esittää backpropagation:

ymmärtäminen käyttämällä esimerkkiä
Word2vec käyttää yhtä Piilotettua kerrosta, täysin yhdistettyä neuroverkkoa kuten alla on esitetty. Piilokerroksen neuronit ovat kaikki lineaarisia neuroneja. Tulokerroksessa on niin monta hermosolua kuin sanastossa on sanoja harjoitteluun. Piilokerroksen koko asetetaan tuloksena olevien sanavektorien dimensionaalisuuteen. Ulostulokerroksen koko on sama kuin tulokerroksen. Jos siis sanavektorien oppimisen sanasto koostuu V-sanoista ja N on sanavektorien ulottuvuus, piilokerroinyhteyksien tulo voidaan esittää matriisilla WI, jonka koko on VXN ja jokainen rivi edustaa sanastosanaa. Samoin yhteydet piilokerroksesta ulostulokerrokseen voidaan kuvata matriisin wo koko NxV avulla. Tällöin jokainen wo-matriisin sarake edustaa tiettyä sanaa annetusta sanastosta.

verkkoon tuleva tulo koodataan” 1-out of-V ” – esityksellä, mikä tarkoittaa, että vain yksi tulorivi asetetaan yhteen ja loput tulorivit nollaan.
oletetaan, että meillä on koulutuskorpus, jossa on seuraavat lauseet:
”koira näki kissan”, ”koira jahtasi kissaa”, ”kissa kiipesi puuhun”
korpuksen sanastossa on kahdeksan sanaa. Kun sana on järjestetty aakkosjärjestykseen, siihen voidaan viitata sen hakemiston avulla. Tässä esimerkissä neuroverkostossamme on kahdeksan tulohermosolua ja kahdeksan lähtöhermosolua. Oletetaan, että päätämme käyttää kolmea neuronia piilokerroksessa. Tämä tarkoittaa, että WI ja WO ovat vastaavasti 8×3 ja 3×8 matriisia. Ennen harjoittelun aloittamista nämä matriisit alustetaan pieniksi satunnaisarvoiksi, kuten neuroverkkokoulutuksessa on tapana. Kuvituksen vuoksi oletetaan, että WI ja WO alustetaan seuraaviin arvoihin:

Oletetaan, että haluamme verkon oppivan sanojen ”kissa” ja ”kiipesi”välisen suhteen. Toisin sanoen verkon pitäisi näyttää suurella todennäköisyydellä ”kiipesi”, kun” kissa ” syötetään verkkoon. Sanasisällöissä sanaa ” kissa ”kutsutaan kontekstisanaksi ja sanaa” kiipesi ” kohdesanaksi. Tällöin tulovektori X on t. huomaa, että vain vektorin toinen komponentti on 1. Tämä johtuu siitä, että syötesana on ”kissa”, joka pitää kakkossijaa lajiteltujen korpus-sanojen luettelossa. Koska kohdesana on ”kiivetty”, kohdevektori näyttää t: ltä. kun tulovektori edustaa” cat”: tä, piilokerroksen neuronien ulostulo voidaan laskea seuraavasti:
ht = Xtwi =
ei pitäisi olla yllättävää, että piilotetun neuronin ulostulovektori H jäljittelee WI-matriisin toisen rivin painoja 1-out-of-Vesentaation vuoksi. Joten tulon tehtävä piilokerroksiyhteyksiin on periaatteessa kopioida tulosanan vektori piilokerrokseen. Samantapaisia manipulointeja varten hidden to output layer, aktivointivektori output layer neuronien voidaan kirjoittaa
HtWO =
koska, tavoitteena on tuottaa todennäköisyydet sanojen lähtö kerros, Pr(wordk|wordcontext) varten k = 1, V, heijastaa niiden seuraavan sanan suhde konteksti sana input, tarvitsemme summa neuronin lähdöt output layer lisätä yksi. Word2vec saavuttaa tämän muuntamalla lähtökerroksen neuronien aktivaatioarvot todennäköisyyksiksi softmax-funktion avulla. Näin k-th-hermosolun ulostulo lasketaan seuraavalla lausekkeella, jossa aktivaatio (n) kuvaa n – th-ulostulokerroksen neuronin aktivaatioarvoa:
näin kahdeksan sanan todennäköisyydet korpuksessa ovat:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
lihavoitu todennäköisyys on valitulle kohdesanalle ”kiipesi”. Kun otetaan huomioon kohdevektori t, lähtökerroksen virhevektori lasketaan helposti vähentämällä todennäköisyysvektori kohdevektorista. Kun virhe on tiedossa, painot matriisit WO ja WI voidaan päivittää backpropagation. Näin koulutus voi edetä esittämällä korpuksesta eri konteksti-kohde-sanaparin. Näin Word2vec oppii sanojen välisiä suhteita ja samalla kehittää vektoriesityksiä sanoille korpuksessa.
word2vecin ideana on esittää sanoja d-ulottuvuuden reaalilukujen vektorilla. Siksi toinen matriisi on näiden sanojen esitys. Tämän matriisin i-th-rivi on i-th-sanan vektoriesitys. Sanotaan , että esimerkissä sinulla on 5 sanaa:, sitten ensimmäinen vektori tarkoittaa harkitset sanaa ”hevonen” ja niin edustus ”hevonen” on . Samoin on sanan ”leijona”edustus.

tietääkseni ei ole mitään” inhimillistä merkitystä ” nimenomaan jokaiselle näiden esitysten numeroille. Yksi numero ei esitä, onko sana verbi vai ei, adjektiivi vai ei … se on vain painot, jotka muutat ratkaista optimointiongelmasi oppia edustus sanasi.
seuraavassa kuviossa on esitetty parhaiten laadittu visuaalinen kaavio word2vec-matriisin kertolaskusta:

ensimmäinen matriisi edustaa tulovektoria yhdessä hot-muodossa. Toinen matriisi edustaa synaptisia painoja tulokerroksen neuroneista piilokerroksen neuroneihin. Huomaa erityisesti vasen yläkulma, jossa Tulokerrosmatriisi kerrotaan Painomatriisilla. Katso oikeaa yläosaa. Tämä matriisi kertolasku InputLayer dot-tuotettu painoilla Transpose on vain kätevä tapa edustaa neuroverkko oikeassa yläkulmassa.
ensimmäinen osa esittää tulosanan yhtenä kuumana vektorina ja toinen matriisi kuvaa kunkin tulokerroksen neuronin ja piilokerroksen neuronien välisen yhteyden painoa. Kuten Word2Vec kouluttaa, se backpropagates (käyttäen kaltevuus laskeutuminen) näihin painoihin ja muuttaa niitä antaa parempia esityksiä sanoja vektoreina. Kun koulutus on suoritettu, käytät vain tätä paino matriisi, ottaa sanoa ”koira” ja moninkertaistaa sen parannettu paino matriisi saada vektoriesitys ”koira” ulottuvuus = ei piilotettu kerros neuronien. Kaaviossa piilokerroksen neuronien määrä on 3.
pähkinänkuoressa Skip-gram-malli kumoaa kohde-ja kontekstisanojen käytön. Tällöin kohdesana syötetään tulon kohdalle, piilokerros pysyy samana ja neuroverkon ulostulokerros monistetaan useita kertoja, jotta valittu määrä kontekstisanoja mahtuu mukaan. Kun otetaan esimerkiksi” kissa ”ja” puu ”asiayhteyssanoina ja” kiipesi ” kohdesanana, skim-gramman mallissa tulovektori olisi t, kun taas kahdessa lähtökerroksessa kohdevektoreina olisi t ja t vastaavasti. Yhden todennäköisyysvektorin sijasta nykyesimerkille tuotettaisiin kaksi tällaista vektoria. Virhevektori kullekin tulostuskerrokselle tuotetaan edellä kuvatulla tavalla. Kuitenkin, virhe vektorit kaikista lähtö kerrokset summataan säätää painot kautta backpropagation. Tämä varmistaa, että paino matriisi wo kunkin lähtö kerros pysyy identtisenä koko koulutuksen.
perusjumppamalliin tarvitaan muutamia lisämuutoksia, jotka ovat tärkeitä koulutuksen mahdollistamiseksi. Gradientin laskeutuminen noin suureen neuroverkkoon on hidasta. Ja mikä pahinta, tarvitset valtavan määrän harjoitustietoa virittääksesi noin monta painoa ja välttääksesi ylisovituksen. miljoonia painoja kertaa miljardeja treeninäytteitä tarkoittaa, että tämän mallin treenaamisesta tulee peto. Tätä varten kirjoittajat ovat ehdottaneet kahta tekniikkaa, joita kutsutaan osanäytteeksi ja negatiiviseksi näytteenotoksi, jossa merkityksettömät sanat poistetaan ja vain tietty painonäyte päivitetään.
Mikolov ym. käytä myös yksinkertaista osanäytteenottotapaa korjataksesi epätasa-arvoa harvojen ja usein esiintyvien sanojen välillä koulutussarjassa (esimerkiksi ”in”, ”the” Ja ”a” tarjoavat vähemmän informaatioarvoa kuin harvinaiset sanat). Jokainen sana harjoitussarjassa hylätään todennäköisyydellä P (wi), jossa

f (wi) on sanan wi taajuus ja t on valittu kynnys, tyypillisesti noin 10-5.
Toteutustiedot
Word2vec on toteutettu useilla eri kielillä, mutta tässä keskitytään erityisesti Javaan ts., DeepLearning4j, darks-learning ja python . Dl4j: ssä on toteutettu erilaisia neuroverkkoalgoritmeja, koodi on saatavilla GitHubissa.
sen toteuttamiseksi dl4j: ssä käydään läpi muutamia vaiheita, jotka annetaan seuraavasti:
a) Word2Vec Setup
Luo uusi projekti Intellijissä Mavenin avulla. Määritä sitten Ominaisuudet ja riippuvuudet POM: ssä.XML-tiedosto projektisi juurihakemistossa.
b) kuormitustiedot
luo ja nimeä nyt uusi luokka Jaavalla. Sen jälkeen otat raa ’ at lauseet omaasi .txt-tiedosto, läpäistä ne iteraattorilla, ja alistaa ne jonkinlaiseen esikäsittelyyn, kuten muuntamalla kaikki sanat pieniksi kirjaimiksi.
String filePath = new ClassPathResource (”raw_sentences.txt”).getFile ().getAbsolutePath ();
log.info (”kuormitus & Vectorize lauseita….”);
// Nauhavalkoinen väli ennen ja jälkeen kunkin rivin
SentenceIterator iter = new BasicLineIterator (filePath);
jos haluat ladata tekstitiedoston esimerkissämme annettujen lauseiden lisäksi, teet näin:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) tietojen Tokenisointi
Word2vec on syötettävä sanoja kokonaisten lauseiden sijaan, joten seuraava askel on tietojen tokenisointi. Tekstin tokenisoiminen tarkoittaa sitä, että se hajotetaan atomiyksiköikseen, jolloin syntyy uusi token joka kerta, kun osuu esimerkiksi valkoiseen tilaan.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) mallin Harjoittelu
nyt kun tieto on valmis, voit määrittää sana2vec-hermoverkon ja syötteen poletteihin.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
tämä kokoonpano hyväksyy useita hyperparametrejä. Muutama vaatii jonkin selityksen:
- batchSize on käsiteltävien sanojen määrä kerrallaan.
- minWordFrequency on vähimmäismäärä, kuinka monta kertaa sanan täytyy esiintyä korpuksessa. Täällä, jos se näkyy alle 5 kertaa, se ei ole oppinut. Sanojen täytyy esiintyä useissa yhteyksissä oppiakseen hyödyllisiä ominaisuuksia niistä. Hyvin isoissa korporaatioissa on kohtuullista nostaa minimiä.
- useAdaGrad-Adagrad luo jokaiselle ominaisuudelle erilaisen gradientin. Tässä Emme ole siitä huolissamme.
- kerroskoko määrittää sanavektorin ominaisuuksien määrän. Tämä on yhtä suuri määrä ulottuvuuksia featurespace. 500 piirteen edustamat sanat muuttuvat pisteiksi 500-ulotteisessa avaruudessa.
- learningRate on kertoimien jokaisen päivityksen askelkoko, sillä sanat on sijoitettu uudelleen ominaisuusavaruuteen.
- minLearningRate on oppimistason lattia. Oppimistahti hidastuu, kun opeteltavien sanojen määrä vähenee. Jos oppimistahti kutistuu liikaa, verkon oppiminen ei ole enää tehokasta. Tämä pitää kertoimet liikkeessä.
- iterate kertoo netille, millä datajoukolla se harjoittelee.
- tokenizer syöttää sille nykyisen erän sanat.
- vec.fit () kertoo asetetun verkon aloittavan harjoittelun.
e) mallin arviointi käyttäen Word2vec
seuraava vaihe on arvioida ominaisuusvektorien laatu.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
rivi vec.similarity("word1","word2") Palauttaa kahden syötettävän sanan kosinin samankaltaisuuden. Mitä lähempänä lukua 1 on, sitä samankaltaisemmaksi verkko mieltää nämä sanat (katso yllä oleva Ruotsi-Norja-esimerkki). Esimerkiksi:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
kun vec.wordsNearest("word1", numWordsNearest), ruudulle painetuista sanoista voi päätellä, onko verkko ryhmittynyt semanttisesti samanlaisiin sanoihin. Voit asettaa haluamasi lähimpien sanojen määrän wordsNearest-parametrin toisella parametrilla. Esimerkiksi:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec Java-kielellä http://deeplearning4j.org/word2vec.html
7) Word2Vec ja Doc2Vec Python genismissä http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html