Par: Ahmad Yaseen | Mise à jour: 2018-03-30 | Commentaires (3) | Connexes: Plus > Optimisation des requêtes

Webinaire gratuit MSSQLTips : Indexation des performances : Stratégies de requête pour maximiser vos Index SQL Server
Peu de choses influencent autant la vitesse et les performances des instructions SQL dans SQL Server que les index. Cette session vous aidera à comprendre les bases de la performance des requêtes par rapport aux index de votre base de données de production. Nous vous apprendrons comment déterminer si vous utilisez de bonnes stratégies d’indexation et l’impact direct de votre stratégie d’indexation sur les requêtes.
Problème
Je sais que SQL Server peut exécuter des requêtes en parallèle, mais comment puis-je savoir qu’une requête utilise un plan d’exécution parallèle et comment puis-je obtenir des informations sur le nombre de CPU utilisés lorsqu’une requête s’exécute en parallèle ? Consultez cette astuce pour savoir comment.
Solution
Le concept de parallélisme provient de la division d’une grande tâche en tâches plus petites, où chaque petite tâche est assignée à une personne spécifique, ou à un processeur dans le cas d’une requête SQLServer, pour accomplir une partie de la tâche principale. Enfin, les résultats partiels obtenus de chaque petite tâche seront combinés en un seul résultat final. Vous pouvez imaginer à quel point cela peut être fait plus rapidement et le gain de performance que vous pouvez obtenir en exécutant plusieurs tâches série en même temps en parallèle, par rapport à l’exécution d’une grande tâche en série!
Avant de passer en revue le tip, il est utile de comprendre un certain nombre de termes techniques liés au concept de parallélisme dans SQL Server:
- Le planificateur est le processeur physique ou logique quiest responsable de la planification de l’exécution des threads SQL Server.
- Le Worker est le thread lié à un planificateur pour effectuer une tâche spécifique.
- Le degré de parallélisme est le nombre de travailleurs, ou le nombre de processeurs, qui sont affectés au plan parallèle pour accomplir la tâche de travailleur.
- Le degré maximal de parallélisme (MAXDOP) est une option de niveau serveur, base de données ou requête utilisée pour limiter le nombre de processeurs que le plan parallèle peut utiliser. La valeur par défaut de MAXDOP est 0, dans laquelle le moteur de serveur SQL peut utiliser tous les processeurs disponibles, jusqu’à 64, dans la parallélexécution de la requête. La définition de l’option MAXDOP sur 1 empêchera l’utilisation de plus d’un processeur pour exécuter la requête, ce qui signifie que le moteur SQL Server utilisera un serialplan pour exécuter la requête. L’option MAXDOP peut prendre une valeur allant jusqu’à 32767, où le moteur SQL Server utilisera tous les processeurs de serveur disponibles dans l’exécution du plan parallèle si la valeur MAXDOP dépasse le nombre de processeurs disponibles sur le serveur. Si le serveur SQL est installé sur un seul serveur de traitement, la valeur de MAXDOP sera ignorée.
- La tâche est un petit travail qui est assigné à un travailleur spécifique.
- Le contexte d’exécution est la limite dans laquelle chaque singletask s’exécute à l’intérieur.
- Le fournisseur de pages parallèles fait partie du moteur SQL ServerStorage qui distribue les ensembles de données demandés par la requête dans les travailleurs participants.
- L’échange est le composant qui connectera les différents contextes d’exécution impliqués dans le plan parallèle de requête ensemble, pour obtenir le résultat final.
La décision d’utiliser un plan parallèle pour exécuter ou non la requête dépend de plusieurs facteurs. Par exemple, SQL Server doit être installé sur un serveur multi-processeurs, le nombre de threads requis doit être disponible pour être satisfait, l’option de degré maximal de parallélisme n’est pas définie sur 1 et le coût de la requête dépasse le seuil de coût précédemment configuré pour Parallelismvalue.
Le but de cette astuce, est de récupérer les informations des threads de requête parallèles à partir du plan d’exécution réel de la requête. Pour forcer le moteur SQL Server à exécuter la requête soumise à l’aide d’un plan parallèle, nous allons définir le Seuil de coût pour la valeur de parallélisme à 0, pour nous assurer que dans tous les cas, le coût de la requête dépassera le Seuil de coût pour la valeur de parallélisme et nous conserverons l’option de Degré maximal de parallélisme avec sa valeur par défaut 0, pour permettre au Moteur SQL Server d’utiliser tous les processeurs disponibles lors de l’exécution de notre requête, soit 4 processeurs dans mymachine utilisés pour cette démo.
Le seuil de coût pour la valeur de parallélisme peut être défini à l’aide de SQL Server ManagementStudio, en se connectant à l’instance SQL Server, en cliquant avec le bouton droit sur le nom d’instance et en choisissant l’option Propriétés. À partir de la page Avancée de la fenêtre des propriétés du serveur, faites défiler jusqu’à la section Parallélisme, à partir de laquelle vous pouvez remplacer la valeur par défaut de l’option Seuil de coût pour le parallélisme, qui est 5, ou le degré maximum de parallélisme si nécessaire, comme indiqué dans la capture d’écran ci-dessous:
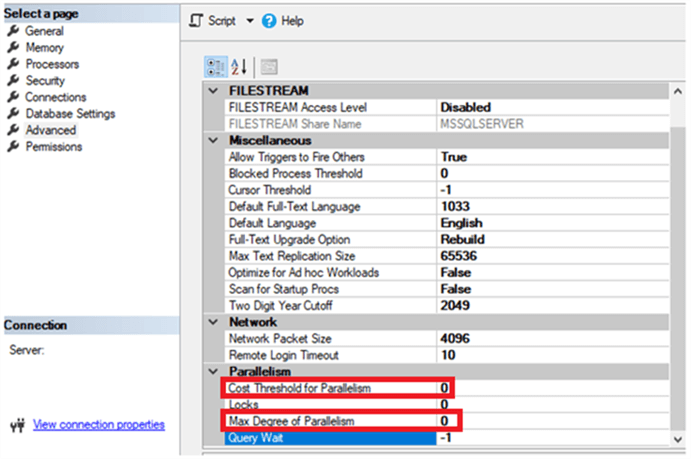
Vous pouvez également remplacer la valeur par défaut du seuil de coût pour le parallélisme en utilisant sp_configure. Pour pouvoir modifier le seuil de coût de la valeur de parallélisme, vous devez utiliser sp_configure pour activer d’abord l’option Afficher avancé, comme indiqué dans le script ci-dessous:
EXEC sp_configure 'show advanced options', 1;RECONFIGURE;GOEXEC sp_configure 'cost threshold for parallelism', 0;RECONFIGURE;GOEXEC sp_configure 'show advanced options', 0;RECONFIGURE;
Démonstration du plan d’exécution parallèle
Le serveur est maintenant configuré pour la démonstration. Créons une nouvelle table à l’aide de l’instruction Create TABLE T-SQL comme indiqué ci-dessous:
USE MSSQLTipsDemoGOCREATE TABLE ParallelDemo( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName NVARCHAR (200), LastName NVARCHAR (200), PhoneNumber VARCHAR(50), BirthDate DATETIME, Address NVARCHAR(MAX) )
Une fois la table créée, nous remplirons la table avec 100 000 enregistrements à l’aide des instructions Insert INTO ci-dessous:
INSERT INTO ParallelDemo VALUES ('John','Horold','+96255889955','1987-01-08','Jordan - Amman - Mecca Street - Building 77')GO 50000 INSERT INTO ParallelDemo VALUES ('Michel','Anglo','+96255776655','1985-06-02','Jordan - Amman - Mecca Street - Building 74')GO 50000
Maintenant, nous voulons activer le « Inclure le plan d’exécution réel », puis lancer la requête de sélection ci-dessous:
SELECT , , , , , FROM .. WHERE Address LIKE '%AMM%' ORDER BY BirthDate desc
Une fois l’exécution terminée, nous pouvons vérifier le plan d’exécution généré à partir de l’exécution de la requête, vous verrez que le moteur SQL Server décide d’utiliser un parallelplan pour exécuter la requête, en raison du fait que le coût de cette requête dépasse le seuil de coût pour la valeur de parallélisme.
Nous pouvons voir ci-dessous que le plan d’exécution est un plan parallèle, à cause du Parallélismeopérateur et aussi des cercles jaunes avec deux flèches sous chaque opérateur qui s’exécutaitavec le parallélisme.

Le plan d’exécution n’est pas seulement un graphique, il contient des informations précieuses quidécrit le processus d’exécution de la requête soumise. Pour afficher ces informations, cliquez avec le bouton droit sur le nœud de SÉLECTION dans le plan d’exécution et choisissezl’option Propriétés. Dans la fenêtre Propriétés, vous pouvez voir le nombre de processeurs utilisés pour traiter la requête soumise à partir de l’attribut Degré de parallélisme, sous la section Divers comme indiqué ci-dessous:
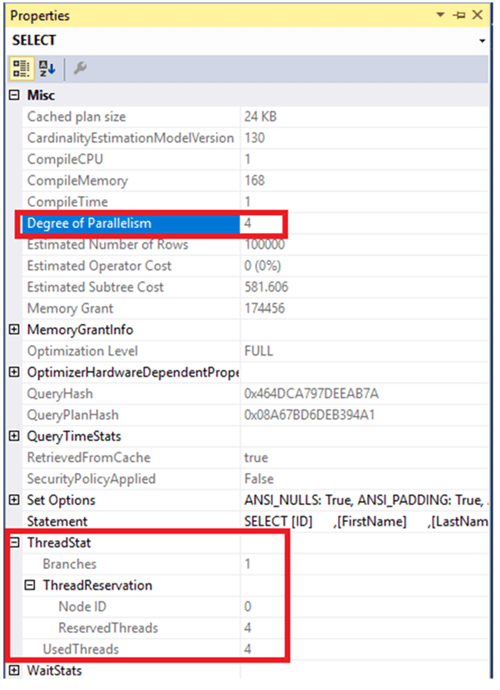
Dans cette même fenêtre, les informations sur les threads de requête parallèles sont également affichées dans la section ThreadStat. Dans cette section, vous pouvez vérifier l’attribut Branches de requête parallèles, qui affiche le nombre de chemins d’exécution simultanés dans le plan d’exécution de la requête, l’ID de nœud NUMA, le nombre de threads parallèles réservés au NUMAnode spécifié sous l’attribut ReservedThreads et le nombre de threads utilisés lors de l’exécution de la requête, sous l’attribut UsedThreads.
Dans la fenêtre Propriétés, vous pouvez déduire que le moteur SQL Server a utilisé 4processeurs pour exécuter la requête. De plus, le plan d’exécution de la requête a un chemin d’exécution, dans lequel 4 threads sont réservés et utilisés pour exécuter la requête soumise à l’aide d’un plan parallèle.
Les mêmes informations peuvent également être dérivées du plan d’exécution XML, en consultant la section ThreadStat, comme indiqué ci-dessous:

Vous pouvez également approfondir pour vérifier les E / S et les ressources CPU consommées par eachthread. Cliquez avec le bouton droit sur le nœud d’analyse d’index en cluster dans le plan d’exécution et choisissez Propriétés. Dans la fenêtre des propriétés affichées, vous pouvez étendre le nœud de statistiques d’E / S réel pour vérifier le nombre d’opérations de lecture logiques et physiques effectuées par chaque thread lors de l’exécution de la requête. De plus, vous pouvez également vérifier le nombre de lignes récupérées à partir de chaque thread, le temps CPU consommé par chaque thread et enfin le temps d’exécution écoulé par chaque thread pour accomplir sa tâche, comme indiqué ci-dessous:
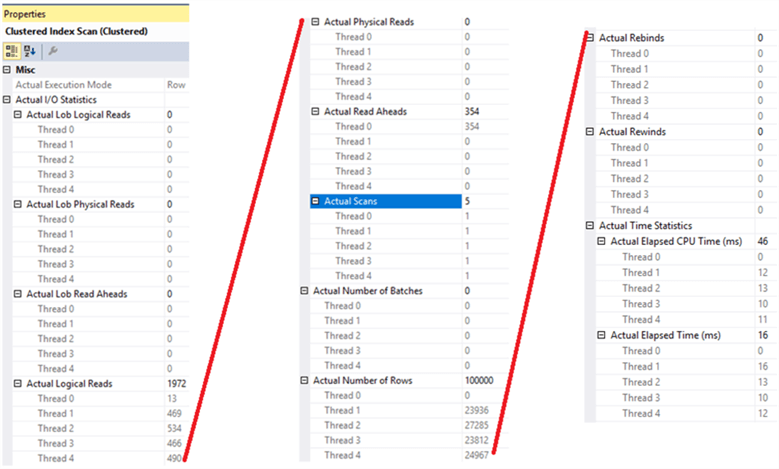
Les résultats correspondent à la fenêtre SÉLECTIONNER les propriétés du nœud, où il y a4 threads de travail qui ont participé à l’exécution des tâches de requête et un coordinatorthread qui coordonne entre les threads de travail.
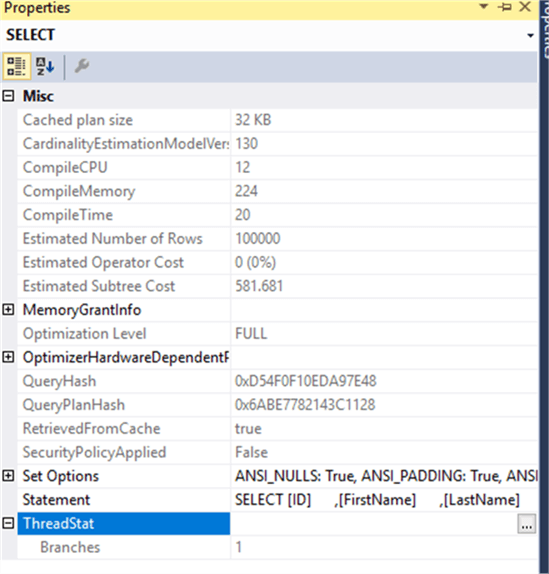
Tenez compte du fait que les informations précédentes ne peuvent être extraites que du Plan d’exécution réel généré après l’exécution de la requête. Si vous essayez de rechercher ces informations dans le Plan d’exécution estimé, sans exécuter la requête, aucune information ne sera affichée car la requête doit s’exécuter afin de spécifier le nombre de processeurs qui seront affectés à la requête à partir des processeurs disponibles pendant l’exécution de la requête, comme indiqué ci-dessous pour le Plan d’exécution estimé.
Obtenir Plus d’informations sur le parallélisme SQL Server
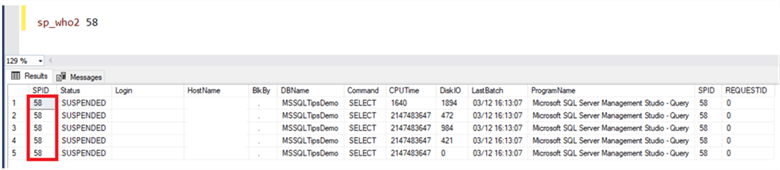
Pendant l’exécution de la requête, vous pouvez simplement exécuter la commande sp_who2 avec l’ID querysession pour obtenir des informations sur les threads utilisés pour exécuter submittedquery pendant l’exécution de la requête, comme indiqué ci-dessous:
Dans le plan d’exécution, chaque opérateur de ce plan avait un numéro qui lui était assigné et un planificateur utilisé pour l’exécuter. Ces informations peuvent être récupérées en parcourant le système.vue du catalogue système dm_os_tasks et la joindre aux vues du catalogue système sys.dm_os_workerset sys.dm_exec_query_profiles, comme dans le script T-SQL ci-dessous:
SELECT OSTSK.scheduler_id, qp.node_id, qp.physical_operator_nameFROM sys.dm_os_tasks OSTSKLEFT JOIN sys.dm_os_workers OSWRK on OSTSK.worker_address=OSWRK.worker_addressLEFT JOIN sys.dm_exec_query_profiles qp on OSWRK.task_address=qp.task_addressWHERE OSTSK.session_id=58ORDER BY scheduler_id, node_id;
Exécution du script précédent lors de l’exécution de l’instruction SELECT avec le plan ActualExecution activé, le résultat nous montrera que les trois opérateurs de plan: Trier, Filtrer et Analyser l’index en cluster avec l’ID de chaque opérateur affiché à côté. Ceci est exécuté quatre fois, en utilisant les quatre planificateurs. L’opérateur de parallélisme avec ID égal à 0 sera exécuté une fois par le quatrième planificateur pour connecter tous les contextes d’exécution ensemble dans la dernière étape, comme indiqué ci-dessous:
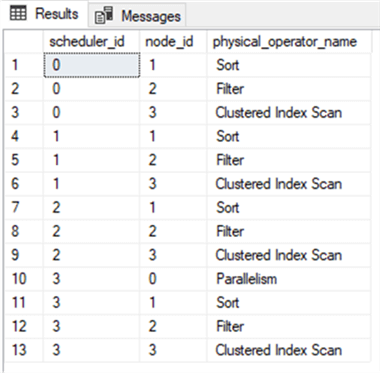
Ci-dessous, j’ai ajouté les valeurs de nœud qui correspondent aux résultats de la requête ci-dessusavec le plan d’exécution pour aider à illustrer davantage.

Étapes suivantes
- Consultez les ressources suivantes :
- Spécification du degré maximal de parallélisme dans SQL Server pour une requête.
- Quel paramètre MAXDOP doit être utilisé pour SQL Server.
- Comment forcer un plan d’exécution parallèle dans SQL Server 2016.
- SQL Server 2016 DBCC CHECKDB avec MAXDOP
Dernière Mise à Jour: 2018-03-30


À propos de l’auteur
 Ahmad Yaseen est un DBA de SQL Server avec un baccalauréat en génie informatique ainsi qu’une expérience de développement .NET.
Ahmad Yaseen est un DBA de SQL Server avec un baccalauréat en génie informatique ainsi qu’une expérience de développement .NET.Voir tous mes conseils
Ressources connexes
- Plus de conseils pour les développeurs de bases de données…