- Cosa sono i collegamenti interni?
- Esempio di codice
- Formato ottimale
- Che cos’è un collegamento interno?
- SEO Best Practice
- Link in Submission-Required Forms
- Collegamenti accessibili solo tramite caselle di ricerca interne
- Collegamenti in Javascript non analizzabile
- Collegamenti in Flash, Java o altri plug-in
- Link che puntano a pagine bloccate dal Tag Meta Robots o Robot.txt
- Link su pagine con centinaia o migliaia di link
- Collegamenti in Frame o I-Frame
- Continua a imparare
Cosa sono i collegamenti interni?
I collegamenti interni sono collegamenti ipertestuali che puntano (destinazione) allo stesso dominio del dominio su cui esiste il collegamento (origine). In parole povere, un link interno è uno che punta a un’altra pagina sullo stesso sito web.
Esempio di codice
<a href="http://www.same-domain.com/" title="Keyword Text">Keyword Text</a>
Formato ottimale
Usa parole chiave descrittive nel testo di ancoraggio che danno un senso dell’argomento o delle parole chiave che la pagina di origine sta cercando di indirizzare.
Che cos’è un collegamento interno?
I collegamenti interni sono collegamenti che vanno da una pagina su un dominio a una pagina diversa sullo stesso dominio. Sono comunemente usati nella navigazione principale.
Questo tipo di collegamenti sono utili per tre motivi:
- Consentono agli utenti di navigare in un sito web.
- Aiutano a stabilire la gerarchia delle informazioni per il sito Web specificato.
- Aiutano a diffondere link equity (ranking power) intorno ai siti web.
SEO Best Practice
I link interni sono molto utili per stabilire l’architettura del sito e diffondere link equity (anche gli URL sono essenziali). Per questo motivo, questa sezione riguarda la costruzione di un’architettura del sito SEO-friendly con collegamenti interni.
Su una singola pagina, i motori di ricerca devono vedere il contenuto per elencare le pagine nei loro massicci indici basati su parole chiave. Hanno anche bisogno di avere accesso a una struttura di collegamento crawlable—una struttura che consente ragni navigare i percorsi di un sito web—al fine di trovare tutte le pagine di un sito web. Centinaia di migliaia di siti fanno l’errore critico di nascondere o seppellire la loro navigazione link principale in modi che i motori di ricerca non possono accedere. Ciò ostacola la loro capacità di ottenere pagine elencate negli indici dei motori di ricerca. Di seguito è riportato un esempio di come questo problema può accadere:
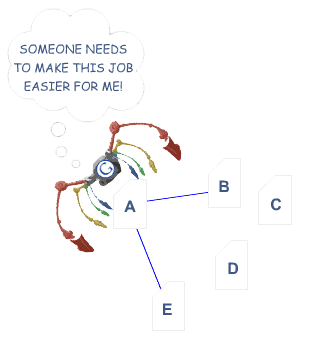
Nell’esempio sopra, il ragno colorato di Google ha raggiunto la pagina ” A “e vede i collegamenti interni alle pagine” B “ed” E. ” Per quanto importanti le pagine C e D possano essere sul sito, il ragno non ha modo di raggiungerle—o addirittura sapere che esistono—perché nessun link diretto e crawlable punta a quelle pagine. Per quanto riguarda Google, queste pagine fondamentalmente non esistono: ottimi contenuti, un buon targeting per parole chiave e un marketing intelligente non fanno alcuna differenza se gli spider non riescono a raggiungere quelle pagine in primo luogo.
La struttura ottimale per un sito web sarebbe simile a una piramide (dove il grande punto in alto è homepage):
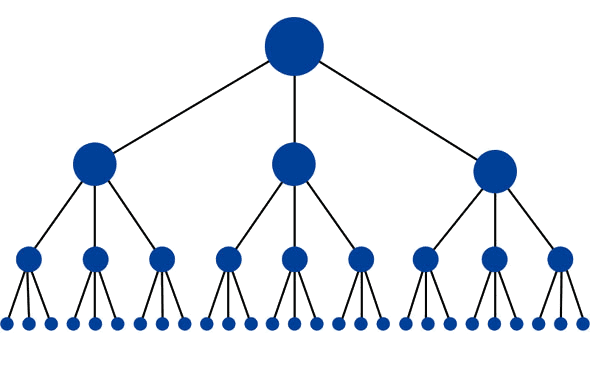
Questa struttura ha la quantità minima di collegamenti possibili tra la home page e una determinata pagina. Questo è utile perché permette link equity (ranking power) di fluire in tutto il sito, aumentando così il potenziale di ranking per ogni pagina. Questa struttura è comune su molti siti web ad alte prestazioni (come Amazon.com) sotto forma di sistemi di categoria e sottocategoria.
Ma come si realizza questo? Il modo migliore per farlo è con collegamenti interni e strutture URL supplementari. Ad esempio, si collegano internamente a una pagina situata in http://www.example.com/mammals… con il testo di ancoraggio ” gatti.”Di seguito è riportato il formato per un collegamento interno formattato correttamente. Immagina che questo collegamento sia sul dominio jonwye.com.

Nell’illustrazione precedente, il tag” a ” indica l’inizio di un collegamento. I tag di collegamento possono contenere immagini, testo o altri oggetti, che forniscono un’area “cliccabile” nella pagina che gli utenti possono coinvolgere per spostarsi in un’altra pagina. Questo è il concetto originale di Internet: “collegamenti ipertestuali.”La posizione di riferimento del link indica al browser-e ai motori di ricerca—dove punta il link. In questo esempio, viene fatto riferimento all’URL http://www.jonwye.com. Successivamente, la parte visibile del link per i visitatori, chiamata “anchor text” nel mondo SEO, descrive la pagina a cui punta il link. In questo esempio, la pagina a cui punta riguarda le cinture personalizzate realizzate da un uomo di nome Jon Wye, quindi il link utilizza il testo di ancoraggio “Cinture personalizzate di Jon Wye.”Il tag </a> chiude il collegamento, in modo che agli elementi successivi nella pagina non venga applicato l’attributo link.
Questo è il formato più semplice di un collegamento—ed è eminentemente comprensibile per i motori di ricerca. Gli spider dei motori di ricerca sanno che dovrebbero aggiungere questo link al grafico dei link del motore del web, usarlo per calcolare variabili indipendenti dalla query (come MozRank) e seguirlo per indicizzare il contenuto della pagina di riferimento.
Di seguito sono riportati alcuni motivi comuni per cui le pagine potrebbero non essere raggiungibili e quindi non essere indicizzate.
Link in Submission-Required Forms
I moduli possono includere elementi di base come un menu a discesa o elementi complessi come un sondaggio completo. In entrambi i casi, gli spider di ricerca non tenteranno di” inviare ” moduli e quindi, qualsiasi contenuto o link che sarebbe accessibile tramite un modulo sono invisibili ai motori.
Collegamenti accessibili solo tramite caselle di ricerca interne
Gli spider non tenteranno di eseguire ricerche per trovare contenuti e, pertanto, si stima che milioni di pagine siano nascoste dietro pareti interne della casella di ricerca completamente inaccessibili.
Collegamenti in Javascript non analizzabile
I collegamenti creati utilizzando Javascript possono essere non tracciabili o svalutati in peso a seconda della loro implementazione. Per questo motivo, si consiglia di utilizzare collegamenti HTML standard al posto dei collegamenti basati su Javascript su qualsiasi pagina in cui il traffico di riferimento del motore di ricerca è importante.
Collegamenti in Flash, Java o altri plug-in
Qualsiasi collegamento incorporato all’interno di Flash, applet Java e altri plug-in è solitamente inaccessibile ai motori di ricerca.
Link che puntano a pagine bloccate dal Tag Meta Robots o Robot.txt
Il tag Meta Robots e i robot.il file txt consente al proprietario di un sito di limitare l’accesso di spider a una pagina.
Link su pagine con centinaia o migliaia di link
I motori di ricerca hanno tutti un limite di scansione approssimativa di 150 link per pagina prima che possano smettere di spidering pagine aggiuntive collegate alla dalla pagina originale. Questo limite è un po ‘ flessibile, e pagine particolarmente importanti possono avere verso l’alto di 200 o anche 250 link seguiti, ma in pratica generale, è saggio limitare il numero di link su una determinata pagina a 150 o rischiare di perdere la possibilità di avere pagine aggiuntive strisciato.
Collegamenti in Frame o I-Frame
Tecnicamente, i collegamenti in entrambi i frame e I-Frame sono crawlable, ma entrambi presentano problemi strutturali per i motori in termini di organizzazione e di seguito. Solo gli utenti avanzati con una buona conoscenza tecnica di come i motori di ricerca indicizzano e seguono i collegamenti nei frame dovrebbero utilizzare questi elementi in combinazione con il collegamento interno.
Evitando queste insidie, un webmaster può avere collegamenti HTML puliti e spiderabili che consentiranno agli spider un facile accesso alle loro pagine di contenuto. I collegamenti possono avere attributi aggiuntivi applicati a loro, ma i motori ignorano quasi tutti questi, con l’importante eccezione del tag rel="nofollow".
Vuoi avere una rapida occhiata all’indicizzazione del tuo sito? Usa uno strumento come Moz Pro, Link Explorer o Screaming Frog per eseguire una scansione del sito. Quindi, confronta il numero di pagine visualizzate dalla scansione con il numero di pagine elencate quando esegui un sito:cerca su Google.
Rel = “nofollow” può essere utilizzato con la seguente sintassi:
<pre><a href=”/” rel=”nofollow”>nofollow questo link</a></pre>
In questo esempio, aggiungendo il rel="nofollow" attributo del tag link, il webmaster è raccontare i motori di ricerca che non vogliono questo link per essere interpretato come un normale, succo di passaggio, “editoriale di voto.”Nofollow è nato come un metodo per aiutare a fermare il commento automatico del blog, il guestbook e lo spam di link injection, ma si è trasformato nel tempo in un modo per dire ai motori di scontare qualsiasi valore di link che normalmente sarebbe passato. I collegamenti contrassegnati con nofollow sono interpretati in modo leggermente diverso da ciascuno dei motori.
Continua a imparare
- Testo di ancoraggio
- Link Equity
- Linee guida per i webmaster Le linee guida ufficiali di Google per i webmaster.
- Link di testo e PageRank Ex capo del team Webspam di Google, Matt Cutts’, pensieri sui collegamenti ipertestuali in relazione a SEO e Google.