Di Doble Engineering Company in Enterprise Asset Management | giugno 25, 2020
Condividi questo…

Facebook

Pinterest

Twitter

Linkedin
Il mondo dei dati e analytics è in continua evoluzione. Nei suoi giorni più semplici, l’organizzazione tipica dei dati consisteva in alcuni file, database di applicazioni o transazionali, data warehouse e data mart di reporting. Poiché le fonti di dati, i volumi, le velocità di generazione e il processo di raccolta sono cresciuti nel corso degli anni, l’ambiente informatico di oggi deve occuparsi di set di dati estremamente grandi, comunemente chiamati “big data”, che rivelano modelli, tendenze e altro ancora, su cui le organizzazioni possono basare le decisioni.
La maggior parte delle organizzazioni ha oggi molti, se non tutti, dei componenti evidenziati nell’architettura di riferimento veicolata in Figura 1 – applicazioni, sistemi e origini, trasferimento dati, livello dati aziendale, servizi dati, analisi e reporting e elaborazione dati avanzata.
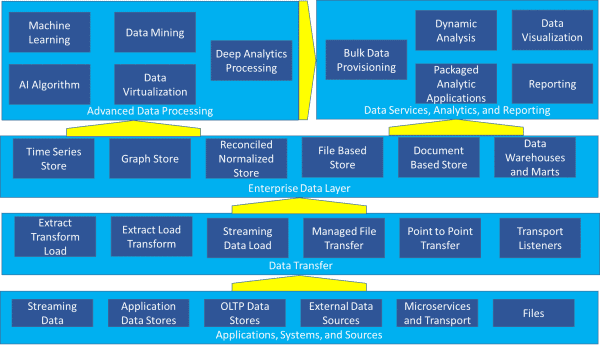
Figura 1-Architettura di riferimento complessa
Con data warehouse e mart rappresentati come uno dei 28 possibili componenti, è difficile capire come si inseriscono nell’immagine a prima vista. Ma la maggior parte delle organizzazioni si occupa attualmente di più di un data warehouse: devono gestire in modo coerente un ambiente complesso come quello raffigurato in Figura 1.
Le architetture Kimball e Inmon offrono entrambi framework per aiutare nello sviluppo di architetture di riferimento complesse.
Aggiornamento rapido sui due approcci
Prima di applicare i pattern Kimball o Inmon, vale la pena rivedere le differenze tra i due approcci. Controlla le rappresentazioni visive di ciascuno in Figura 21 e Figura 32 .
Il lavoro di Kimball e Inmon – i fondatori dei rispettivi modelli – si sono sfidati a vicenda. Mentre entrambi gli approcci sono prevalentemente guidati dal ciclo di sviluppo di un modello di dati, i modelli si basano su un focus unico di un approccio bottom up o top down. Queste tensioni hanno avuto luogo nello sviluppo degli ambienti di archiviazione e analisi dei dati complessivi.
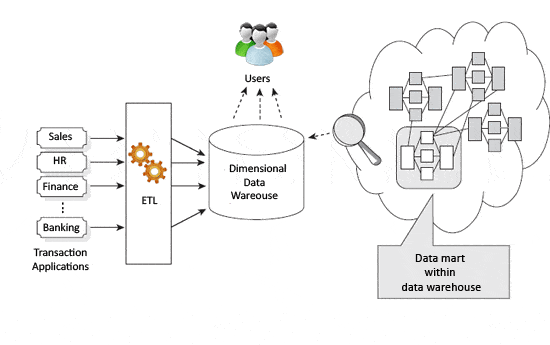
Figura 2-Visual Kimball

Visualizza Figura 3-Visual Inmon View
L’approccio Kimball indica che i data warehouse e i data mart sono guidati da processi aziendali e domande aziendali. L’ovvio pericolo per questo è che i dati utili potrebbero non essere necessariamente classificati o acquisiti poiché non rientrerebbero nel processo aziendale in fase di definizione.
L’approccio Inmon indica la creazione di un data warehouse aziendale con modelli logici progettati per ogni entità attorno a un argomento, ad esempio contatore, fattura e asset. La sfida è che mentre i temi principali possono rappresentare la differenziazione, le entità che li sostengono possono rappresentare punti in comune che possono essere persi.
Ad esempio, la posizione di un contatore rappresentata da una posizione di servizio, l’indirizzo di fatturazione rappresentato nella fattura e la posizione di inventario o di distribuzione di una risorsa possono condividere attributi comuni. Anche in Inmon, esiste il pericolo che la posizione del servizio, l’indirizzo di fatturazione, l’asset, la posizione dell’inventario e la posizione di distribuzione degli asset possano essere rappresentati come cinque oggetti diversi, poiché sono considerati per supportare diversi verticali nell’organizzazione con diversi data mart.
Entrambi gli approcci Inmon e Kimball sono guidati dal ciclo per sviluppare il modello di dati concettuale, quindi implementare i modelli di dati in una forma fisicalizzata. Questo ciclo può supportare approcci di sviluppo più agili, ma si allineerà più strettamente con un approccio di sviluppo a cascata a causa della linearità della ricerca (basata sul processo o sull’argomento aziendale), dello sviluppo del modello concettuale (basato sui dati nel processo o sull’argomento aziendale) e dello sviluppo del modello fisico.
Fare il passo successivo
Un processo agile potrebbe rendere difficile iniettare cicli in questo tipo di attività di sviluppo. La sfida per ogni organizzazione sarà quella di prendere le lezioni apprese dagli approcci Inmon e Kimball e applicarle in un nuovo contesto.
Maggiori dettagli su come applicare i modelli a un ambiente complesso per venire nella seconda parte di questa serie di blog-stay tuned!
Nel frattempo, controlla il nostro recente post sull’implementazione con successo della gestione delle informazioni aziendali (EIM).