Il modello di Markov nascosto (HMM) è un modello di Markov statistico in cui si presume che il sistema modellato sia un processo di Markov con stati non osservati (cioè nascosti).
I modelli di Markov nascosti sono particolarmente noti per la loro applicazione nell’apprendimento per rinforzo e nel riconoscimento di pattern temporali come la parola, la scrittura a mano, il riconoscimento dei gesti, il tagging part-of-speech, il seguito della partitura musicale, le scariche parziali e la bioinformatica.
Terminologia in HMM
Il termine nascosto si riferisce al processo di Markov del primo ordine dietro l’osservazione. L’osservazione si riferisce ai dati che conosciamo e possiamo osservare. Il processo di Markov è mostrato dall’interazione tra “Rainy” e “Sunny” nel diagramma sottostante e ciascuno di questi sono STATI NASCOSTI.

Le OSSERVAZIONI sono dati noti e si riferiscono a “Camminare”, “Negozio” e “Pulito” nel diagramma sopra. Nel senso dell’apprendimento automatico, l’osservazione è i nostri dati di allenamento e il numero di stati nascosti è il nostro iper parametro per il nostro modello. La valutazione del modello sarà discussa in seguito.

T = non hai ancora alcuna osservazione, N = 2, M = 3, Q = {“Rainy”, “Sunny”}, V = {“Walk”, “Shop”, “Clean”}
Le probabilità di transizione di stato sono le frecce che puntano a ogni stato nascosto. Matrice di probabilità di osservazione sono le frecce blu e rosse che indicano ogni osservazioni da ogni stato nascosto. La matrice è riga stocastica che significa che le righe aggiungono fino a 1.


La matrice spiega che la probabilità è da andare a uno stato ad un altro, o andando da uno stato ad un’osservazione.
La distribuzione dello stato iniziale fa andare il modello partendo da uno stato nascosto.
Il modello completo con probabilità di transizione di stato note, matrice di probabilità di osservazione e distribuzione dello stato iniziale è contrassegnato come,
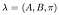
Come possiamo costruire il modello sopra in Python?
Nel caso precedente, le emissioni sono discrete {“Walk”,” Shop”,”Clean”}. MultinomialHMM dalla libreria hmmlearn viene utilizzato per il modello di cui sopra. GaussianHMM e GMMHMM sono altri modelli nella libreria.
Ora con l’HMM quali sono alcuni problemi chiave da risolvere?
- Problema 1, dato un modello noto qual è la probabilità che la sequenza O accada?
- Problema 2, dato un modello e una sequenza noti O, qual è la sequenza di stato nascosta ottimale? Questo sarà utile se vogliamo sapere se il tempo è “Piovoso”o” Soleggiato ”
- Problema 3, Data la sequenza O e il numero di stati nascosti, qual è il modello ottimale che massimizza la probabilità di O?
Problema 1 in Python
La probabilità che la prima osservazione sia “a piedi” è uguale alla moltiplicazione della distribuzione dello stato iniziale e della matrice di probabilità di emissione. 0,6 x 0,1 + 0,4 x 0,6 = 0,30 (30%). La probabilità del registro viene fornita dalla chiamata .Punteggio.
Problema 2 in Python

Dato il modello e l’osservazione {“Negozio”, “Pulire”, “Piedi”}, meteo, con più probabilità, {“Piovoso”, “Piovoso”, “Sunny”} con ~1.5% di probabilità.
Dato il modello noto e l’osservazione {“Pulito”, “Pulito”, “Pulito”}, il tempo era molto probabile {“Piovoso”, “Piovoso”, “Piovoso”} con ~3,6% di probabilità.
Intuitivamente, quando si verifica “Camminare”, il tempo molto probabilmente non sarà”Piovoso”.
Problema 3 in Python
riconoscimento Vocale con File Audio: Prevedere queste parole

l’Ampiezza può essere utilizzato come OSSERVAZIONE per HMM, ma la caratteristica di ingegneria ci darà più prestazioni.

Funzione stft e peakfind genera funzionalità per il segnale audio.
L’esempio sopra è stato preso da qui. Kyle Kastner ha costruito la classe HMM che prende in array 3d, sto usando hmmlearn che consente solo array 2d. Questo è il motivo per cui sto riducendo le funzionalità generate da Kyle Kastner come X_test.media (asse = 2).
Passare attraverso questa modellazione ha richiesto molto tempo per capire. Ho avuto l’impressione che la variabile target debba essere l’osservazione. Questo è vero per le serie temporali. La classificazione viene eseguita costruendo HMM per ogni classe e confrontando l’output calcolando il logprob per il tuo input.
Soluzione matematica al problema 1: algoritmo di inoltro

Alpha pass è la probabilità di osservazione e sequenza di STATO dato modello.
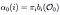
Passaggio alfa al tempo (t) = 0, distribuzione dello stato iniziale a i e da lì alla prima osservazione O0.
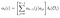
Passaggio alfa al tempo (t) = t, somma dell’ultimo passaggio alfa a ogni stato nascosto moltiplicato per l’emissione in Ot.
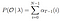
Soluzione matematica al problema 2: Indietro Algoritmo


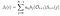

Dato modello e di osservazione, la probabilità di essere in stato di qi, al tempo t,.
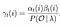
Soluzione Matematica del Problema 3: Avanti-Indietro Algoritmo


Probabilità di stato di qi di qj, al tempo t, con un dato modello di osservazione e di
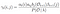
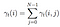
Somma di tutte le probabilità di transizione tra i e j.
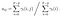
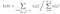
di Transizione e di emissione di matrice probabilità sono stimati con di-gamma.
Itera se la probabilità per P(O|modello) aumenta