Non-Uniform Memory Access (NUMA) è un’architettura di memoria condivisa utilizzata nei sistemi multiprocessing di oggi. Ad ogni CPU viene assegnata la propria memoria locale e può accedere alla memoria da altre CPU nel sistema. L’accesso alla memoria locale offre una bassa latenza-elevate prestazioni di larghezza di banda. Durante l’accesso alla memoria di proprietà dell’altra CPU ha una latenza più elevata e prestazioni di larghezza di banda inferiori. Applicazioni e sistemi operativi moderni come ESXi supportano NUMA per impostazione predefinita, ma per fornire le migliori prestazioni, la configurazione della macchina virtuale dovrebbe essere eseguita tenendo presente l’architettura NUMA. Se progettato in modo errato, si verifica un comportamento irrilevante o un degrado generale delle prestazioni per quella particolare macchina virtuale o nel peggiore dei casi per tutte le macchine virtuali in esecuzione su quell’host ESXi.
Questa serie mira a fornire informazioni sull’architettura della CPU, il sottosistema di memoria e la CPU ESXi e lo scheduler di memoria. Consentendo di creare una piattaforma ad alte prestazioni che pone le basi per i servizi più elevati e un aumento dei rapporti di consolidamento. Prima di arrivare alle moderne architetture di calcolo, è utile rivedere la cronologia delle architetture multiprocessore a memoria condivisa per capire perché oggi utilizziamo i sistemi NUMA.
- L’evoluzione dell’architettura multiprocessore a memoria condivisa negli ultimi decenni
- Introduzione dei protocolli di caching snoop
- Uniform Memory Access Architecture
- Architettura di accesso alla memoria non uniforme
- 1: Organizzazione di accesso alla memoria non uniforme
- 2: Interconnessione punto-punto
- 3: Scalable Cache Coherence
- NUMA abilitato non interleaved = SUMA
- Nehalem &Panoramica della microarchitettura core
L’evoluzione dell’architettura multiprocessore a memoria condivisa negli ultimi decenni
Sembra che un’architettura chiamata Uniform Memory Access sarebbe più adatta quando si progetta una piattaforma coerente a bassa latenza e ad alta larghezza di banda. Tuttavia, le moderne architetture di sistema impediranno di essere veramente uniformi. Per capire la ragione di questo abbiamo bisogno di tornare indietro nella storia per identificare i driver chiave del calcolo parallelo.
Con l’introduzione di database relazionali nei primi anni Settanta la necessità di sistemi in grado di servire più operazioni utente simultanee e la generazione eccessiva di dati divenne mainstream. Nonostante l’impressionante tasso di prestazioni uniprocessore, i sistemi multiprocessore erano meglio equipaggiati per gestire questo carico di lavoro. Al fine di fornire un sistema economico, lo spazio degli indirizzi di memoria condivisa è diventato il fulcro della ricerca. All’inizio, i sistemi che utilizzano uno switch a barra trasversale sono stati sostenuti, tuttavia con questa complessità di progettazione ridimensionata insieme all’aumento dei processori, che ha reso il sistema basato su bus più attraente. I processori in un sistema bus possono accedere all’intero spazio di memoria inviando richieste sul bus, un modo molto economico per utilizzare la memoria disponibile nel modo più ottimale possibile.
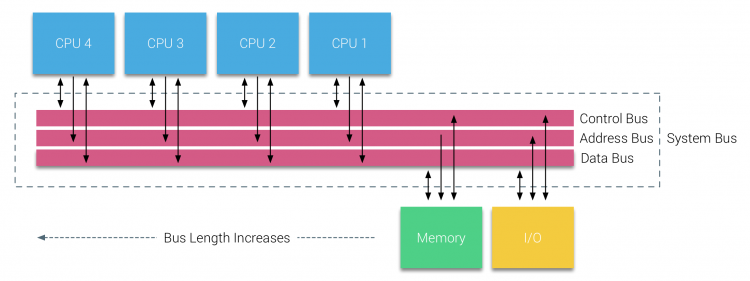
Tuttavia, i sistemi basati su bus hanno i loro problemi di scalabilità. Il problema principale è la quantità limitata di larghezza di banda, questo limita il numero di processori che il bus può ospitare. L’aggiunta di CPU al sistema introduce due principali aree di preoccupazione:
- La larghezza di banda disponibile per nodo diminuisce con l’aggiunta di ogni CPU.
- La lunghezza del bus aumenta quando si aggiungono più processori, aumentando così la latenza.
La crescita delle prestazioni della CPU e in particolare il divario di velocità tra il processore e le prestazioni della memoria era, e in realtà è ancora, devastante per i multiprocessori. Poiché il divario di memoria tra processore e memoria era destinato ad aumentare, un grande sforzo è andato nello sviluppo di strategie efficaci per gestire i sistemi di memoria. Una di queste strategie è stata l’aggiunta di cache di memoria, che ha introdotto una moltitudine di sfide. Risolvere queste sfide è ancora l’obiettivo principale di oggi per i team di progettazione della CPU, molte ricerche sono fatte su strutture di caching e algoritmi sofisticati per evitare errori di cache.
Introduzione dei protocolli di caching snoop
Collegare una cache a ciascuna CPU aumenta le prestazioni in molti modi. Avvicinare la memoria alla CPU riduce il tempo medio di accesso alla memoria e allo stesso tempo riduce il carico di larghezza di banda sul bus di memoria. La sfida con l’aggiunta di cache a ciascuna CPU in un’architettura di memoria condivisa è che consente l’esistenza di più copie di un blocco di memoria. Questo è chiamato il problema della coerenza della cache. Per risolvere questo problema, sono stati inventati protocolli di caching snoop tentando di creare un modello che fornisse i dati corretti senza cercare di consumare tutta la larghezza di banda sul bus. Il protocollo più popolare, write invalidate, cancella tutte le altre copie dei dati prima di scrivere la cache locale. Qualsiasi lettura successiva di questi dati da parte di altri processori rileverà una mancanza di cache nella loro cache locale e verrà gestita dalla cache di un’altra CPU contenente i dati modificati più di recente. Questo modello ha risparmiato molta larghezza di banda del bus e ha permesso l’emergere di sistemi di accesso alla memoria uniformi nei primi anni 1990. I moderni protocolli di coerenza della cache sono trattati in modo più dettagliato dalla parte 3.
Uniform Memory Access Architecture
I processori di multiprocessori basati su Bus che sperimentano lo stesso tempo di accesso uniforme a qualsiasi modulo di memoria nel sistema sono spesso indicati come Uniform Memory Access (UMA) systems o Symmetric Multi-Processors (SMPS).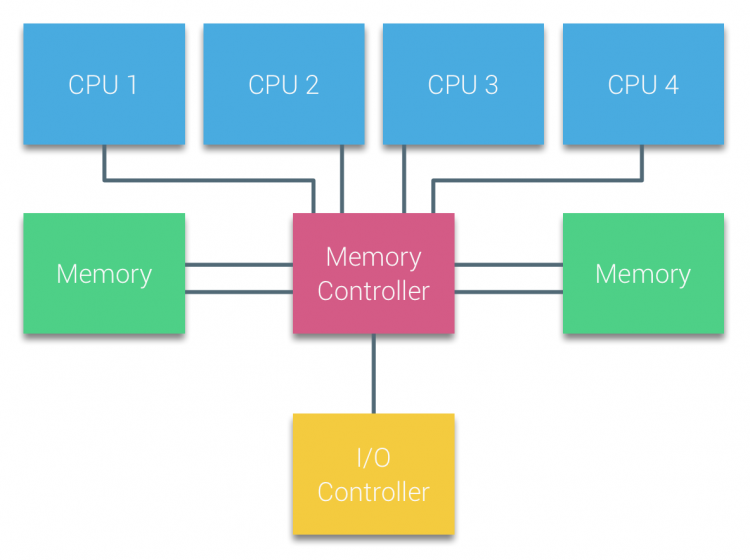
Con i sistemi UMA, le CPU sono collegate tramite un bus di sistema (Front-Side Bus) al Northbridge. Il Northbridge contiene il controller di memoria e tutte le comunicazioni da e verso la memoria devono passare attraverso il Northbridge. Il controller I/O, responsabile della gestione dell’I/O su tutti i dispositivi, è collegato al Northbridge. Pertanto, ogni I / O deve passare attraverso il Northbridge per raggiungere la CPU.
Più bus e canali di memoria vengono utilizzati per raddoppiare la larghezza di banda disponibile e ridurre il collo di bottiglia del Northbridge. Per aumentare ulteriormente la larghezza di banda della memoria alcuni sistemi hanno collegato controller di memoria esterni al Northbridge, migliorando la larghezza di banda e il supporto di più memoria. Tuttavia, a causa della larghezza di banda interna del Northbridge e della natura di trasmissione dei primi protocolli di cache snoopy, UMA è stato considerato avere una scalabilità limitata. Con l’uso odierno di dispositivi flash ad alta velocità, spingendo centinaia di migliaia di IO al secondo, avevano assolutamente ragione che questa architettura non sarebbe stata ridimensionata per i carichi di lavoro futuri.
Architettura di accesso alla memoria non uniforme
Per migliorare la scalabilità e le prestazioni vengono apportate tre modifiche critiche all’architettura multiprocessore a memoria condivisa;
- Organizzazione di accesso alla memoria non uniforme
- Topologia di interconnessione punto-punto
- Soluzioni scalabili di coerenza della cache
1: Organizzazione di accesso alla memoria non uniforme
NUMA si allontana da un pool centralizzato di memoria e introduce proprietà topologiche. Classificando le basi di posizione della memoria sulla lunghezza del percorso del segnale dal processore alla memoria, è possibile evitare i colli di bottiglia di latenza e larghezza di banda. Questo viene fatto ridisegnando l’intero sistema di processore e chipset. Le architetture NUMA hanno guadagnato popolarità alla fine degli anni ‘ 90 quando è stato utilizzato su supercomputer SGI come il Cray Origin 2000. NUMA ha contribuito a identificare la posizione della memoria, in questo caso di questi sistemi, hanno dovuto chiedersi quale regione di memoria in cui chassis teneva i bit di memoria.
Nella prima metà del decennio del millennio, AMD portò NUMA nel panorama aziendale dove i sistemi XT regnavano supremi. Nel 2003 è stata introdotta la famiglia AMD Opteron, con controller di memoria integrati con ogni CPU che possiede banchi di memoria designati. Ogni CPU ha ora il proprio spazio di indirizzo di memoria. Un sistema operativo ottimizzato per NUMA come ESXi consente al carico di lavoro di consumare memoria da entrambi gli spazi degli indirizzi di memoria ottimizzando l’accesso alla memoria locale. Usiamo un esempio di un sistema a due CPU per chiarire la distinzione tra accesso alla memoria locale e remoto all’interno di un singolo sistema.
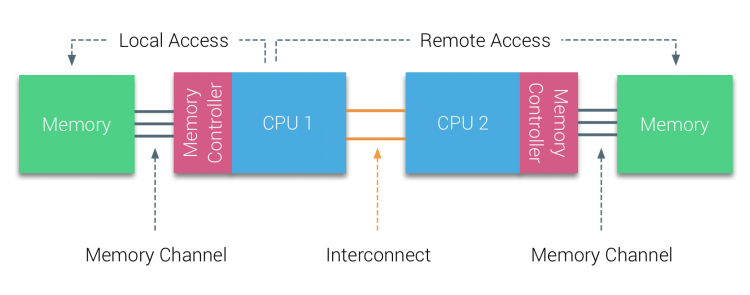
La memoria collegata al controller di memoria della CPU1 è considerata memoria locale. La memoria collegata a un altro socket CPU (CPU2) è considerata straniera o remota per CPU1. L’accesso alla memoria remota ha un sovraccarico di latenza aggiuntivo per l’accesso alla memoria locale, in quanto deve attraversare un’interconnessione (collegamento punto-punto) e connettersi al controller di memoria remoto. Come risultato delle diverse posizioni di memoria, questo sistema sperimenta un tempo di accesso alla memoria “non uniforme”.
2: Interconnessione punto-punto
AMD ha introdotto il loro HyperTransport di connessione punto-punto con la microarchitettura AMD Opteron. Intel si è allontanata dalla loro architettura a doppio bus indipendente nel 2007 introducendo l’architettura QuickPath nella progettazione della famiglia di processori Nehalem.
L’architettura Nehalem è stato un cambiamento significativo del design all’interno della microarchitettura Intel ed è considerata la prima vera generazione della serie Intel Core. L’attuale architettura Broadwell è la 4a generazione del marchio Intel Core (Intel Xeon E5 v4), l’ultimo paragrafo contiene ulteriori informazioni sulle generazioni di microarchitettura. All’interno dell’architettura QuickPath, i controller di memoria si spostavano sulla CPU e introducevano il quickpath point-to-point Interconnect (QPI) come collegamenti dati tra le CPU del sistema.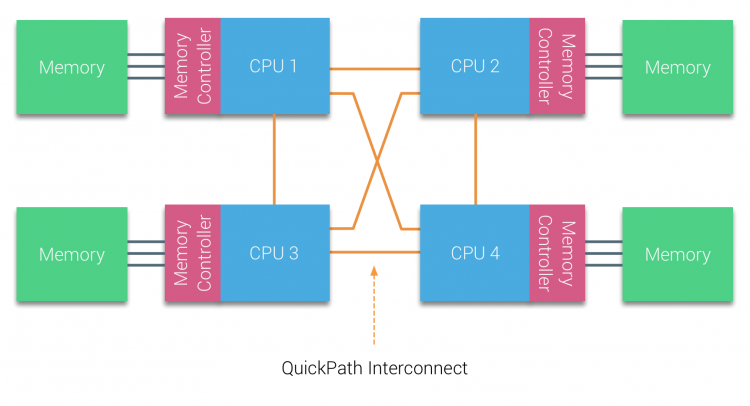
La microarchitettura Nehalem non solo ha sostituito il legacy front-side bus, ma ha riorganizzato l’intero sottosistema in un design modulare per CPU server. Questo design modulare è stato introdotto come “Uncore” e crea una libreria di blocchi di costruzione per la memorizzazione nella cache e le velocità di interconnessione. La rimozione del bus frontale migliora i problemi di scalabilità della larghezza di banda, ma la comunicazione intra e inter – processore deve essere risolta quando si tratta di enormi quantità di capacità di memoria e larghezza di banda. Sia il controller di memoria integrato che le interconnessioni QuickPath fanno parte dell’Uncore e sono registri specifici del modello (MSR) ). Si collegano a un MSR che fornisce la comunicazione intra-e inter-processore. La modularità dell’Uncore consente anche a Intel di offrire diverse velocità QPI, al momento della scrittura della microarchitettura Intel Broadwell-EP (2016) offre 6,4 Giga-trasferimenti al secondo (GT/s), 8,0 GT/s e 9,6 GT/s. Rispettivamente fornendo una larghezza di banda massima teorica di 25,6 GB/s, 32 GB/s e 38,4 GB/s tra le CPU. Per mettere questo in prospettiva, l’ultimo usato front-side bus fornito 1.6 GT/s o 12.8 GB/s di larghezza di banda della piattaforma. Quando si introduce Sandy Bridge Intel rinominato Uncore in System Agent, tuttavia il termine Uncore è ancora utilizzato nella documentazione corrente. Puoi trovare maggiori informazioni su QuickPath e Uncore nella parte 2.
3: Scalable Cache Coherence
Ogni core aveva un percorso privato per la cache L3. Ogni percorso consisteva di mille fili e puoi immaginare che questo non si scalasse bene se vuoi diminuire il processo di produzione nanometrico aumentando anche i core che vogliono accedere alla cache. Per essere in grado di scalare, l’architettura Sandy Bridge ha spostato la cache L3 dall’Uncore e ha introdotto l’interconnessione scalabile ring on-die. Ciò ha permesso a Intel di partizionare e distribuire la cache L3 in parti uguali. Ciò fornisce maggiore larghezza di banda e associatività. Ogni fetta è di 2,5 MB e una fetta è associata a ciascun core. L’anello consente a ciascun nucleo di accedere anche a ogni altra fetta. Nella foto sotto è la configurazione die di una CPU Xeon Low Core Count (LCC) della microarchitettura Broadwell (v4) (2016).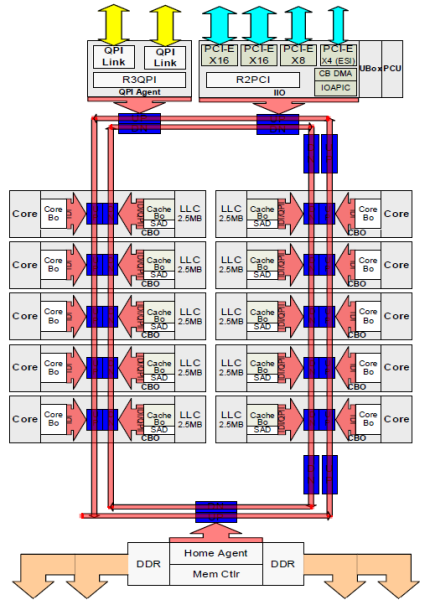
Questa architettura di caching richiede un protocollo snooping che incorpora sia la cache locale distribuita che gli altri processori nel sistema per garantire la coerenza della cache. Con l’aggiunta di più core nel sistema, la quantità di traffico di snoop cresce, poiché ogni core ha il proprio flusso costante di mancate cache. Ciò influisce sul consumo dei collegamenti QPI e delle cache di ultimo livello, che richiedono uno sviluppo continuo nei protocolli di coerenza di snoop. Una visione approfondita del Uncore, scalabile anello on-Die Interconnessione e l’importanza del caching protocolli snoop sulle prestazioni NUMA sarà incluso nella parte 3.
NUMA abilitato non interleaved = SUMA
La memoria fisica è distribuita sulla scheda madre, tuttavia, il sistema può fornire un singolo spazio di indirizzi di memoria interleaving la memoria tra i due nodi NUMA. Questo è chiamato Node-interleaving (l’impostazione è trattata nella parte 2). Quando l’interleaving dei nodi è abilitato, il sistema diventa un’architettura di memoria sufficientemente uniforme (SUMA). Invece di trasmettere le informazioni sulla topologia e la natura dei processori e della memoria nel sistema al sistema operativo, il sistema suddivide l’intero intervallo di memoria in regioni indirizzabili 4KB e le mappa in modo round robin da ciascun nodo. Ciò fornisce una struttura di memoria “interleaved” in cui lo spazio degli indirizzi di memoria è distribuito tra i nodi. Quando ESXi assegna la memoria alla macchina virtuale alloca la memoria fisica situata da due nodi diversi quando la CPU fisica situata nel nodo 0 deve recuperare la memoria dal nodo 1, la memoria attraverserà i collegamenti QPI.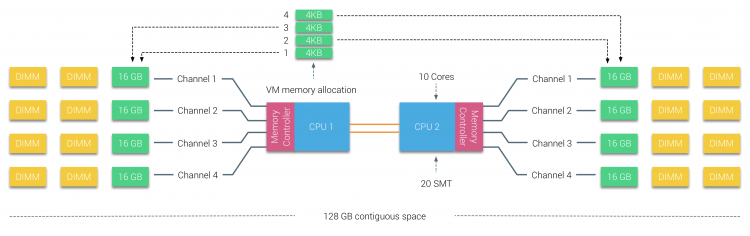
La cosa interessante è che il sistema SUMA fornisce un tempo di accesso alla memoria uniforme. Solo non il più ottimale e dipende fortemente dai livelli di contesa nell’architettura QPI. Intel Memory Latency Checker è stato utilizzato per dimostrare le differenze tra la configurazione NUMA e SUMA sullo stesso sistema.
Questo test misura le latenze inattive (in nanosecondi) da ogni socket all’altro socket nel sistema. La latenza riportata del nodo di memoria 0 dal Socket 0 è l’accesso alla memoria locale, l’accesso alla memoria dal socket 0 del nodo di memoria 1 è l’accesso alla memoria remota nel sistema configurato come NUMA.
| NUMA | Nodo di Memoria 0 | Nodo di Memoria 1 | – | SUMA | Nodo di Memoria 0 | Nodo di Memoria 1 |
| Presa 0 | 75.7 | 132.0 | – | Socket 0 | 105.5 | 106.4 |
| Presa 1 | 131.9 | 75.8 | – | Presa 1 | 106.0 | 104.6 |
Come previsto l’interleaving è influenzato dalla costante di attraversare il QPI link. Il test della memoria inattiva è lo scenario migliore, un test più interessante sta misurando le latenze caricate. Sarebbe stato un cattivo investimento se i server ESXi sono al minimo, per questo si può supporre che un sistema ESXi sta elaborando i dati. La misurazione delle latenze caricate fornisce una migliore comprensione di come il sistema funzionerà sotto carico normale. Durante il test i ritardi di iniezione del carico vengono automaticamente modificati ogni 2 secondi e sia la larghezza di banda che la latenza corrispondente vengono misurati a quel livello. Questo test utilizza il traffico di lettura al 100%.I risultati dei test NUMA a sinistra, i risultati dei test SUMA a destra.
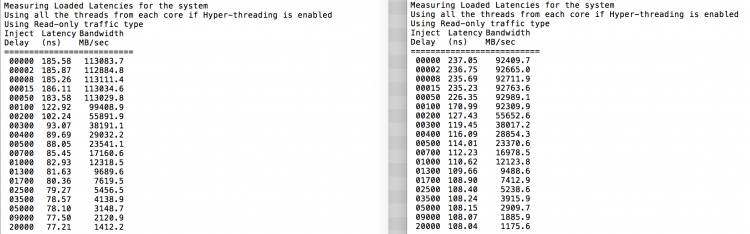
La larghezza di banda riportata per il sistema SUMA è inferiore pur mantenendo una latenza maggiore rispetto al sistema configurato come NUMA. Pertanto, l’attenzione dovrebbe essere focalizzata sull’ottimizzazione delle dimensioni della VM per sfruttare le caratteristiche NUMA del sistema.
Nehalem &Panoramica della microarchitettura core
Con l’introduzione della microarchitettura Nehalem nel 2008, Intel si è allontanata dall’architettura Netburst. La microarchitettura Nehalem ha introdotto i clienti Intel a NUMA. Nel corso degli anni Intel ha introdotto nuove microarchitetture e ottimizzazioni, secondo il suo famoso modello Tick-Tock. Con ogni Tick, l’ottimizzazione avviene, riducendo la tecnologia di processo e con ogni Tock viene introdotta una nuova microarchitettura. Anche se Intel fornisce un modello di branding coerente dal 2012, le persone tendono a nomi in codice dell’architettura Intel per discutere le generazioni di tick e tock della CPU. Anche le linee di base EVC elencano questi nomi in codice Intel interni, sia i nomi di branding che i nomi in codice dell’architettura verranno utilizzati in questa serie:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDDR3-2133 | Tock | 22nm |
| Broadwell | E5-26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4xDDR3-2400 | Selezionare | 14 nm |
Fino a quel punto, Parte 2: Architettura di Sistema
Il 2016 NUMA Immersione Profonda Serie:
Parte 0: Introduzione NUMA Immersione Profonda Serie
Parte 1: UMA a NUMA
Parte 2: Architettura di Sistema
Parte 3: Coerenza Cache
Parte 4: Memoria di Ottimizzazione
Parte 5: ESXi VMkernel NUMA Costrutti