La regressione a tratti è un tipo speciale di regressione lineare che si verifica quando una singola linea non è sufficiente per modellare un set di dati. La regressione a tratti rompe il dominio in potenzialmente molti “segmenti” e si adatta a una linea separata attraverso ciascuno di essi. Ad esempio, nei grafici seguenti, una singola riga non è in grado di modellare i dati e una regressione a tratti con tre linee:
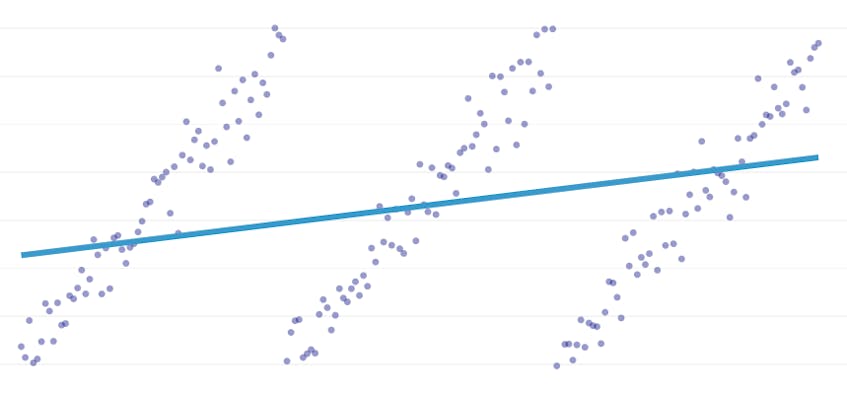
Questo post presenta l’approccio di Datadog per automatizzare la regressione a tratti sui dati delle serie temporali.
Obiettivi
La regressione a tratti può significare cose leggermente diverse in contesti diversi, quindi prendiamo un minuto per chiarire cosa esattamente stiamo cercando di ottenere con il nostro algoritmo di regressione a tratti.
Rilevamento automatico del punto di interruzione. Nella letteratura statistica classica, la regressione a tratti è spesso suggerita durante il lavoro di analisi della regressione manuale, dove è ovvio ad occhio nudo dove una tendenza lineare lascia il posto a un’altra. In tal caso, un essere umano può specificare il punto di interruzione tra segmenti a tratti, dividere il set di dati ed eseguire una regressione lineare su ciascun segmento in modo indipendente. Nei nostri casi d’uso, vogliamo fare centinaia di regressioni al secondo e non è fattibile che un umano specifichi tutti i punti di interruzione. Invece, abbiamo il requisito che il nostro algoritmo di regressione a tratti identifichi i propri punti di interruzione.
Rilevamento automatico del conteggio dei segmenti. Se dovessimo sapere che un set di dati ha esattamente due segmenti, potremmo facilmente guardare ciascuna delle possibili coppie di segmenti. Tuttavia, in pratica, quando viene data una serie temporale arbitraria, non c’è motivo di credere che ci debba essere più di un segmento o meno di 3 o 4 o 5. Il nostro algoritmo deve scegliere un numero appropriato di segmenti senza che sia specificato dall’utente.
Nessun requisito di continuità. Alcuni metodi per regressioni a tratti generano segmenti connessi, in cui il punto finale di ogni segmento è il punto iniziale del segmento successivo. Non imponiamo tale requisito al nostro algoritmo.
Sfide
La sfida più ovvia per implementare una regressione a tratti con rilevamento automatico dei punti di interruzione è la grande dimensione dello spazio di ricerca della soluzione; una ricerca a forza bruta di tutti i segmenti possibili è proibitivamente costosa. Il numero di modi in cui una serie temporale può essere suddivisa in segmenti è esponenziale nella lunghezza della serie temporale. Mentre la programmazione dinamica può essere utilizzata per attraversare questo spazio di ricerca in modo molto più efficiente di un’implementazione ingenua di forza bruta, è ancora troppo lenta nella pratica. Sarà necessaria un’euristica avida per scartare rapidamente ampie aree dello spazio di ricerca.
Una sfida più sottile è che abbiamo bisogno di un modo per confrontare la qualità di una soluzione con un’altra. Per la nostra versione del problema, con numeri e posizioni di segmenti sconosciuti, dobbiamo confrontare le potenziali soluzioni con diversi numeri di segmenti e diversi punti di interruzione. Ci troviamo a cercare di bilanciare due obiettivi in competizione:
- Ridurre al minimo gli errori. Cioè, rendere la linea di regressione di ogni segmento vicino ai punti dati osservati.
- Usa il minor numero di segmenti che modellano bene i dati. Potremmo sempre ottenere zero errori creando un singolo segmento per ogni punto (o anche un segmento per ogni due punti). Tuttavia, ciò sconfiggerebbe l’intero punto di fare una regressione; non impareremmo nulla sulla relazione generale tra un timestamp e il suo valore metrico associato, e non potremmo facilmente utilizzare il risultato per interpolazione o estrapolazione.
La nostra soluzione
Usiamo il seguente algoritmo greedy per il problema di regressione a tratti:
- Fai una regressione a tratti con n/2 segmenti, dove n è il numero di osservazioni nelle serie temporali. La linea di regressione in ogni segmento è adatta usando la regressione ordinaria dei minimi quadrati (OLS). Questa regressione iniziale a tratti avrà quasi nessun errore, ma sovraccaricherà gravemente il set di dati.
- Iterativamente, fino a quando non esiste un solo segmento:
- Per tutte le coppie di segmenti vicini, valutare l’aumento dell’errore totale che risulterebbe se i due segmenti fossero combinati, le loro due linee di regressione sostituite da una singola linea di regressione.
- Unisci insieme la coppia di segmenti che comporterebbe il più piccolo aumento di errore.
- Se l’esecuzione di questa unione soddisfa i nostri criteri di arresto (definiti di seguito), allora potremmo essere andati troppo oltre, unendo due segmenti che dovrebbero rimanere separati. In questo caso, ricordare lo stato dei segmenti prima dell’unione di questa iterazione.
- Se nessuna unione ha portato a ricordare lo stato dei segmenti in (2c) sopra, la soluzione migliore è un segmento di grandi dimensioni. In caso contrario, l’ultimo stato del segmento da ricordare in (2c) è la soluzione migliore.
Criteri di arresto
Consideriamo un’unione come un potenziale punto di arresto se aumenta la somma totale degli errori al quadrato di più di qualsiasi unione precedente. Per evitare di fermarsi troppo presto nei casi in cui dovrebbe esserci un solo segmento, non considereremo un’unione come un potenziale punto di arresto a meno che non determini un aumento dell’errore totale inferiore al 3% dell’errore totale di una regressione con un segmento. (Il 3% è una soglia arbitraria, ma abbiamo trovato che funziona bene nella pratica.) Di seguito sono riportati un paio di esempi per dimostrare perché questo criterio di arresto funziona.
Per prima cosa, diamo un’occhiata a un set di dati generato aggiungendo rumore normalmente distribuito ai punti lungo una singola linea. L’algoritmo si adatta correttamente a un singolo segmento attraverso questo set di dati.
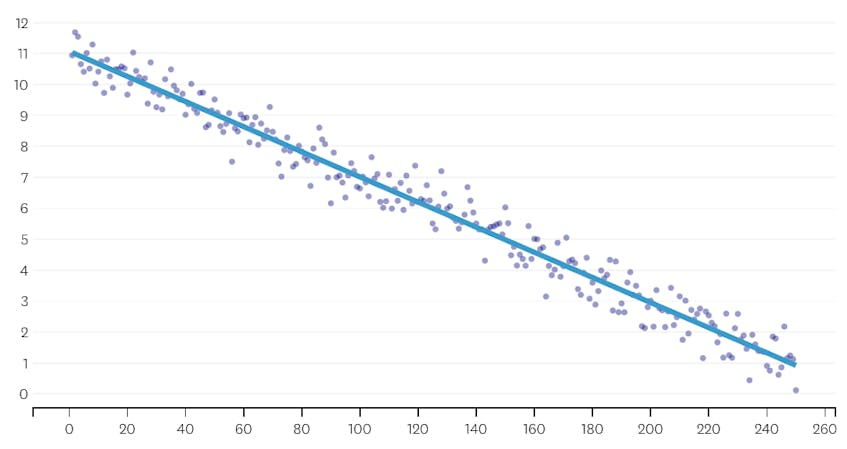
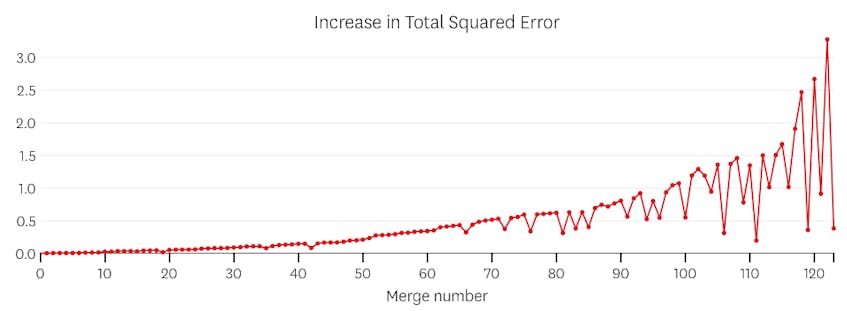
In questo caso, nessuna unione aumenta mai la somma totale degli errori quadrati di oltre il 3%. Pertanto, nessuna unione è considerata un punto di arresto adeguato e utilizziamo lo stato finale dopo che tutte le unioni sono state eseguite. Nella trama sottostante, vediamo che le fusioni successive tendono a introdurre più errori rispetto a quelle precedenti (il che ha senso perché hanno un impatto su più punti), ma l’aumento dell’errore aumenta solo gradualmente man mano che più segmenti vengono uniti.
In secondo luogo, diamo un’occhiata a un esempio in cui ci sono sette segmenti distinti nel set di dati.
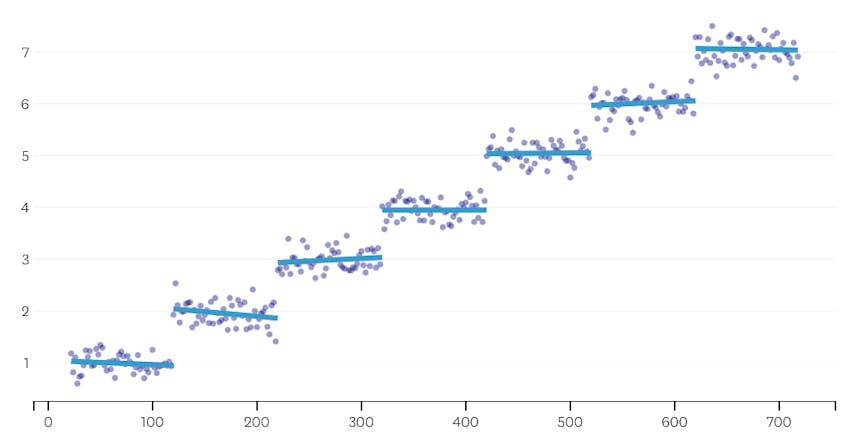
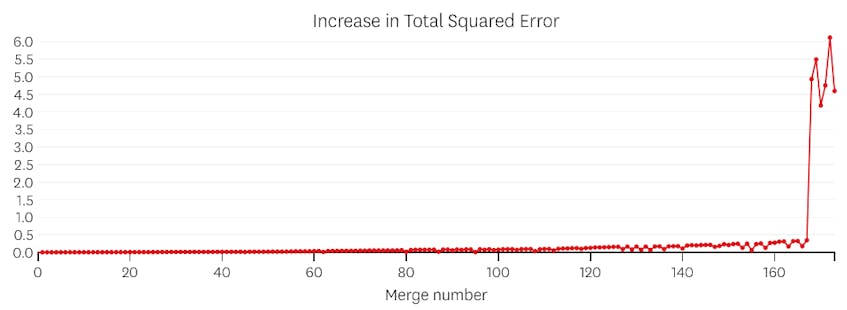
In questo caso, quando guardiamo la trama degli errori introdotti da ogni unione, vediamo che le ultime sei unioni hanno introdotto molto più errore di qualsiasi fusione precedente. Pertanto, il nostro algoritmo ha ricordato lo stato dei segmenti da prima della fusione 6th-to-last e lo ha utilizzato come soluzione finale.
Il codice
Nel repository Datadog/piecewise Github, troverai la nostra implementazione Python dell’algoritmo. La funzione piecewise() è dove avviene il sollevamento pesante; dato un insieme di dati, restituirà i coefficienti di posizione e regressione per ciascuno dei segmenti montati.
Anche incluso nel gist è plot_data_with_regression() — una funzione wrapper per la stampa facile e veloce. Un rapido esempio di come questo potrebbe essere utilizzato:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)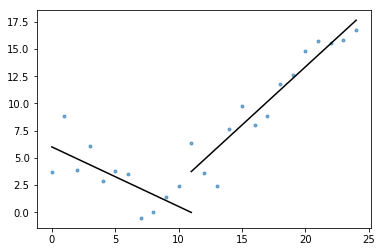
Mentre questa implementazione utilizza la regressione lineare OLS, lo stesso framework può essere adattato per risolvere problemi correlati. Sostituendo l’errore quadrato con l’errore assoluto o la perdita di Huber, la regressione può essere resa robusta. Oppure, una funzione step può essere adattata assegnando a ciascun segmento un valore costante uguale alla media delle osservazioni nel suo dominio.