In questo tutorial ci accingiamo a spiegare, uno dei parola emergente e prominente embedding tecnica chiamata Word2Vec proposto da Mikolov et al. nel 2013. Abbiamo raccolto questi contenuti da diversi tutorial e fonti per facilitare i lettori in un unico luogo. Spero che aiuti.
Word2vec è una combinazione di modelli utilizzati per rappresentare rappresentazioni distribuite di parole in un corpus C. Word2Vec (W2V) è un algoritmo che accetta corpus di testo come input e output di una rappresentazione vettoriale per ogni parola, come mostrato nello schema seguente:

Ci sono due sapori di questo algoritmo vale a dire: CBOW e Skip-Gram. Dato un insieme di frasi (chiamato anche corpus) il modello si collega alle parole di ogni frase e tenta di usare la parola corrente w per prevedere i suoi vicini (cioè il suo contesto), questo approccio è chiamato “Skip-Gram”, o usa ciascuno di questi contesti per prevedere la parola corrente w, in tal caso il metodo è chiamato “Continuous Bag Of Words” (CBOW). Per limitare il numero di parole in ogni contesto, viene utilizzato un parametro chiamato “dimensione finestra”.

I vettori che usiamo per rappresentare le parole sono chiamati embeddings di parole neurali e le rappresentazioni sono strane. Una cosa ne descrive un’altra, anche se queste due cose sono radicalmente diverse. Come diceva Elvis Costello: “Scrivere di musica è come ballare sull’architettura.”Word2vec” vettorizza ” sulle parole, e così facendo rende il linguaggio naturale leggibile dal computer-possiamo iniziare a eseguire potenti operazioni matematiche sulle parole per rilevare le loro somiglianze.
Quindi, un embedding di parole neurali rappresenta una parola con numeri. È una traduzione semplice, ma improbabile. Word2vec è simile a un autoencoder, che codifica ogni parola in un vettore, ma piuttosto che allenarsi contro le parole di input attraverso la ricostruzione, come fa una macchina Boltzmann limitata, word2vec allena le parole contro altre parole che le circondano nel corpus di input.
Lo fa in uno dei due modi, usando il contesto per prevedere una parola di destinazione (un metodo noto come sacchetto continuo di parole o CBOW), o usando una parola per prevedere un contesto di destinazione, che è chiamato skip-gram. Usiamo quest’ultimo metodo perché produce risultati più accurati su set di dati di grandi dimensioni.

Quando il vettore di funzionalità assegnato a una parola non può essere utilizzato per prevedere con precisione il contesto di quella parola, i componenti del vettore vengono regolati. Il contesto di ogni parola nel corpus è l’insegnante che invia segnali di errore per regolare il vettore di funzionalità. I vettori di parole giudicate simili dal loro contesto sono spinti più vicini regolando i numeri nel vettore. In questo tutorial, ci accingiamo a concentrarsi sul modello Skip-Gram che in contrasto con CBOW considerare parola centrale come input come illustrato nella figura sopra e prevedere le parole di contesto.
Panoramica del modello
Abbiamo capito che dobbiamo alimentare una strana rete neurale con alcune coppie di parole, ma non possiamo semplicemente farlo usando come input i caratteri reali, dobbiamo trovare un modo per rappresentare matematicamente queste parole in modo che la rete possa elaborarle. Un modo per farlo è creare un vocabolario di tutte le parole nel nostro testo e quindi codificare la nostra parola come un vettore delle stesse dimensioni del nostro vocabolario. Ogni dimensione può essere pensata come una parola nel nostro vocabolario. Quindi avremo un vettore con tutti gli zeri e un 1 che rappresenta la parola corrispondente nel vocabolario. Questa tecnica di codifica è chiamata codifica one-hot. Considerando il nostro esempio, se abbiamo un vocabolario composto dalle parole “il”, “veloce”, “marrone”, “volpe”, “salta”, “sopra”, “il” “pigro”, “cane”, la parola “marrone” è rappresentata da questo vettore: .

Il modello Skip-gram prende in un corpus di testo e crea un hot-vector per ogni parola. Un vettore caldo è una rappresentazione vettoriale di una parola in cui il vettore è la dimensione del vocabolario (parole uniche totali). Tutte le dimensioni sono impostate su 0 tranne la dimensione che rappresenta la parola utilizzata come input in quel momento. Ecco un esempio di un vettore caldo:

L’input di cui sopra è dato a una rete neurale con un singolo livello nascosto.
Rappresenteremo una parola di input come “ants” come vettore one-hot. Questo vettore avrà 10.000 componenti (uno per ogni parola nel nostro vocabolario) e posizioneremo un “1” nella posizione corrispondente alla parola “formiche” e 0s in tutte le altre posizioni. L’output della rete è un singolo vettore (anche con 10.000 componenti) contenente, per ogni parola nel nostro vocabolario, la probabilità che una parola vicina selezionata casualmente sia quella parola del vocabolario.
In word2vec, viene utilizzata una rappresentazione distribuita di una parola. Prendi un vettore con diverse centinaia di dimensioni (diciamo 1000). Ogni parola è rappresentata da una distribuzione di pesi tra questi elementi. Quindi, invece di una mappatura uno-a-uno tra un elemento nel vettore e una parola, la rappresentazione di una parola viene distribuita su tutti gli elementi nel vettore e ogni elemento nel vettore contribuisce alla definizione di molte parole.
Se ho etichettare le dimensioni in un ipotetico vettore di parola (non ci sono pre-assegnate etichette nell’algoritmo di corso), potrebbe sembrare un po ‘come questo:

Tale vettore viene a rappresentare in qualche modo astratto il “significato” di una parola. E come vedremo dopo, semplicemente esaminando un corpus di grandi dimensioni è possibile imparare vettori di parole che sono in grado di catturare le relazioni tra le parole in modo sorprendentemente espressivo. Possiamo anche usare i vettori come input per una rete neurale. Poiché i nostri vettori di input sono one-hot, moltiplicare un vettore di input per la matrice di peso W1 equivale a selezionare semplicemente una riga da W1.
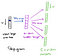

Dal nascosti del livello di output, la seconda matrice peso W2 può essere utilizzato per calcolare un punteggio per ogni parola nel vocabolario, e softmax può essere utilizzato per ottenere la distribuzione a posteriori di parole. Il modello skip-gram è l’opposto del modello CBOW. È costruito con la parola focus come singolo vettore di input e le parole di contesto di destinazione sono ora al livello di output. La funzione di attivazione per il livello nascosto equivale semplicemente a copiare la riga corrispondente dalla matrice pesi W1 (lineare) come abbiamo visto prima. Al livello di output, ora emettiamo C distribuzioni multinomiali invece di una sola. L’obiettivo della formazione è quello di mimimizzare l’errore di previsione sommata in tutte le parole di contesto nel livello di output. Nel nostro esempio, l’input sarebbe “learning”e speriamo di vedere (“an”,” efficient”,” method”,” for”,” high”,” quality”,” distributed”,” vector”) al livello di output.
Ecco l’architettura della nostra rete neurale.

Per il nostro esempio, stiamo andando a dire che stiamo imparando vettori di parole con 300 caratteristiche. Quindi il livello nascosto sarà rappresentato da una matrice di peso con 10.000 righe (una per ogni parola nel nostro vocabolario) e 300 colonne (una per ogni neurone nascosto). 300 caratteristiche è ciò che Google ha utilizzato nel loro modello pubblicato addestrato sul set di dati di Google News (è possibile scaricarlo da qui). Il numero di funzionalità è un “parametro iper” che dovresti semplicemente sintonizzare sulla tua applicazione (cioè provare valori diversi e vedere cosa produce i migliori risultati).
Se guardi le righe di questa matrice di peso, questi sono quelli che saranno i nostri vettori di parole!

Quindi l’obiettivo finale di tutto questo è solo quello di imparare questa matrice di peso del livello nascosto – il livello di output che lanceremo quando avremo finito! Il vettore di parole 1 x 300 per” formiche ” viene quindi alimentato al livello di output. Il livello di output è un classificatore di regressione softmax. In particolare, ogni neurone di output ha un vettore di peso che moltiplica contro il vettore di parole dal livello nascosto, quindi applica la funzione exp(x) al risultato. Infine, per ottenere gli output per sommare fino a 1, dividiamo questo risultato per la somma dei risultati di tutti i 10.000 nodi di output. Ecco un’illustrazione del calcolo dell’output del neurone di uscita per la parola “auto”.

Se due parole diverse hanno “contesti” molto simili (cioè, quali parole potrebbero apparire intorno a loro), allora il nostro modello deve produrre risultati molto simili per queste due parole. E un modo per la rete di produrre previsioni di contesto simili per queste due parole è se i vettori di parole sono simili. Quindi, se due parole hanno contesti simili, allora la nostra rete è motivata a imparare vettori di parole simili per queste due parole! Ta pa!
Ogni dimensione dell’input passa attraverso ogni nodo del livello nascosto. La dimensione viene moltiplicata per il peso che la porta al livello nascosto. Poiché l’input è un vettore caldo, solo uno dei nodi di input avrà un valore diverso da zero (vale a dire il valore di 1). Ciò significa che per una parola verranno attivati solo i pesi associati al nodo di input con valore 1, come mostrato nell’immagine sopra.
Poiché l’input in questo caso è un vettore caldo, solo uno dei nodi di input avrà un valore diverso da zero. Ciò significa che solo i pesi connessi a quel nodo di input verranno attivati nei nodi nascosti. Un esempio di pesi che verranno presi in considerazione è rappresentato sotto per la seconda parola nel vocabolario:
La rappresentazione grafica vettoriale della seconda parola nel vocabolario (come mostrato nella rete neurale sopra) sarà come indicato di seguito, una volta attivato il livello nascosto:
Quei pesi cominciare come valori casuali. La rete viene quindi addestrata per regolare i pesi per rappresentare le parole di input. Questo è dove il livello di output diventa importante. Ora che siamo nel livello nascosto con una rappresentazione vettoriale della parola, abbiamo bisogno di un modo per determinare quanto bene abbiamo predetto che una parola si adatta a un particolare contesto. Il contesto della parola è un insieme di parole all’interno di una finestra, come mostrato di seguito:

L’immagine sopra mostra che il contesto per venerdì include parole come “gatto” e “è”. Lo scopo della rete neurale è quello di prevedere che “Venerdì” rientra in questo contesto.
Attiviamo il livello di output moltiplicando il vettore che abbiamo passato attraverso il livello nascosto (che era il vettore caldo di input * weights che entrava nel nodo nascosto) con una rappresentazione vettoriale della parola di contesto (che è il vettore caldo per la parola di contesto * weights che entrava nel nodo di output). Lo stato del livello di output per la prima parola di contesto può essere visualizzato di seguito:

La moltiplicazione di cui sopra è fatto per ogni parola al contesto coppia di parole. Calcoliamo quindi la probabilità che una parola appartenga a un insieme di parole di contesto utilizzando i valori risultanti dai livelli hidden e output. Infine, applichiamo la discesa del gradiente stocastico per modificare i valori dei pesi al fine di ottenere un valore più desiderabile per la probabilità calcolata.
Nella discesa del gradiente dobbiamo calcolare il gradiente della funzione ottimizzata nel punto che rappresenta il peso che stiamo cambiando. Il gradiente viene quindi utilizzato per scegliere la direzione in cui fare un passo per spostarsi verso l’ottimale locale, come mostrato nell’esempio di minimizzazione seguente.
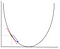
Il peso verrà modificato facendo un passo nella direzione del punto ottimale (nell’esempio precedente, il punto più basso nel grafico). Il nuovo valore viene calcolato sottraendo dal valore di peso corrente la funzione derivata nel punto del peso scalato dal tasso di apprendimento. Il prossimo passo è usare Backpropagation, per regolare i pesi tra più livelli. L’errore calcolato alla fine del livello di output viene passato dal livello di output al livello nascosto applicando la regola della catena. La discesa del gradiente viene utilizzata per aggiornare i pesi tra questi due livelli. L’errore viene quindi regolato su ogni livello e inviato ulteriormente. Ecco un diagramma per rappresentare backpropagation:

Comprensione utilizzando esempio
Word2vec utilizza un singolo strato nascosto, completamente collegato rete neurale come mostrato di seguito. I neuroni nello strato nascosto sono tutti neuroni lineari. Il livello di input è impostato per avere tanti neuroni quanti sono le parole nel vocabolario per l’allenamento. La dimensione del livello nascosto è impostata sulla dimensionalità dei vettori di parole risultanti. La dimensione del livello di output è uguale al livello di input. Pertanto, se il vocabolario per l’apprendimento dei vettori di parole è costituito da V parole e N per essere la dimensione dei vettori di parole, l’input per le connessioni di livello nascoste può essere rappresentato da una matrice WI di dimensione VxN con ogni riga che rappresenta una parola di vocabolario. Allo stesso modo, le connessioni dal livello nascosto al livello di output possono essere descritte da matrix WO di dimensione NxV. In questo caso, ogni colonna di WO matrix rappresenta una parola dal vocabolario dato.

L’input alla rete è codificato usando la rappresentazione “1-out of-V”, il che significa che solo una riga di input è impostata su uno e il resto delle linee di input è impostato su zero.
Supponiamo di avere un corpus di addestramento con le seguenti frasi:
“il cane ha visto un gatto”, “il cane ha inseguito il gatto”, “il gatto si è arrampicato su un albero”
Il vocabolario del corpus ha otto parole. Una volta ordinato in ordine alfabetico, ogni parola può essere referenziata dal suo indice. Per questo esempio, la nostra rete neurale avrà otto neuroni di input e otto neuroni di output. Supponiamo che decidiamo di utilizzare tre neuroni nel livello nascosto. Ciò significa che WI e WO saranno matrici 8×3 e 3×8, rispettivamente. Prima dell’inizio dell’allenamento, queste matrici vengono inizializzate su piccoli valori casuali come è usuale nell’allenamento della rete neurale. Solo per l’illustrazione, supponiamo che WI e WO siano inizializzati ai seguenti valori:

Supponiamo che vogliamo che la rete per imparare relazione tra le parole “gatto ” e”salito”. Cioè, la rete dovrebbe mostrare un’alta probabilità di “scalata” quando ” cat ” viene immesso nella rete. In word embedding terminologia, la parola “gatto “è indicato come la parola contesto e la parola” scalato ” è indicato come la parola di destinazione. In questo caso, il vettore di input X sarà t. Si noti che solo il secondo componente del vettore è 1. Questo perché la parola di input è ” cat ” che tiene la posizione numero due nell’elenco ordinato delle parole del corpus. Dato che la parola di destinazione è “salito”, l’obiettivo vettore sarà simile a t. L’ingresso del vettore che rappresenta “il gatto”, l’uscita al livello nascosto neuroni, può essere calcolato come:
Ht = XtWI =
non ci dovrebbe sorprendere che il vettore H di neuroni nascosti uscite imita i pesi della seconda fila di WI matrice a causa di 1-fuori-di-Vrepresentation. Quindi la funzione delle connessioni input to hidden layer è fondamentalmente quella di copiare il vettore di parole di input sul livello nascosto. Svolgere un simile manipolazioni, nascosti a livello di output, il vettore di attivazione per l’uscita strato di neuroni può essere scritto come
HtWO =
Dal momento che l’obiettivo è produrre probabilità per le parole nello strato di output, Pr(wordk|wordcontext) per k = 1, V, per riflettere la loro parola successiva relazione con il contesto parola all’ingresso, abbiamo bisogno che la somma dei neuroni e delle uscite del livello di output per aggiungere uno. Word2vec raggiunge questo risultato convertendo i valori di attivazione dei neuroni del livello di output in probabilità utilizzando la funzione softmax. Così, l’uscita del k-esimo neurone è calcolato con la seguente espressione in cui attivazione(n) rappresenta il valore di attivazione dell’n-esimo livello di output del neurone:
Così, le probabilità di otto parole nel corpus sono:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
La probabilità in grassetto è per il target scelto parola “scalato”. Dato il vettore di destinazione t, il vettore di errore per il livello di output è facilmente calcolato sottraendo il vettore di probabilità dal vettore di destinazione. Una volta noto l’errore, i pesi nelle matrici WO e WI possono essere aggiornati utilizzando backpropagation. Pertanto, la formazione può procedere presentando una coppia di parole contesto-target diversa dal corpus. È così che Word2vec impara le relazioni tra le parole e nel processo sviluppa rappresentazioni vettoriali per le parole nel corpus.
L’idea alla base di word2vec è quella di rappresentare le parole con un vettore di numeri reali di dimensione d. Quindi la seconda matrice è la rappresentazione di quelle parole. La linea i-esima di questa matrice è la rappresentazione vettoriale della parola i-esima. Diciamo che nel tuo esempio hai 5 parole:, quindi il primo vettore significa che stai considerando la parola ” Cavallo “e quindi la rappresentazione di” Cavallo ” è . Allo stesso modo, è la rappresentazione della parola “Leone”.

A mia conoscenza, non ci sono “significato umano” specificamente per ciascuno dei numeri in queste rappresentazioni. Un numero non rappresenta se la parola è un verbo o no, un aggettivo o no… Sono solo i pesi che cambi per risolvere il tuo problema di ottimizzazione per imparare la rappresentazione delle tue parole.
Un diagramma visivo migliore elaborazione word2vec moltiplicazione di matrici processo è rappresentato nella figura seguente:

La prima matrice rappresenta il vettore d’ingresso in una calda formato. La seconda matrice rappresenta i pesi sinaptici dai neuroni dello strato di input ai neuroni dello strato nascosto. Soprattutto notare l’angolo in alto a sinistra dove la matrice del livello di input viene moltiplicata con la matrice del peso. Ora guarda in alto a destra. Questa moltiplicazione matrice InputLayer dot-producted con pesi Trasposizione è solo un modo pratico per rappresentare la rete neurale in alto a destra.
La prima parte, rappresenta la parola di input come un vettore caldo e l’altra matrice rappresenta il peso per la connessione di ciascuno dei neuroni del livello di input ai neuroni del livello nascosto. Mentre Word2Vec si allena, backpropaga (usando la discesa del gradiente) in questi pesi e li cambia per dare migliori rappresentazioni delle parole come vettori. Una volta completato l’allenamento, usi solo questa matrice di peso, prendi per dire “cane” e moltiplicalo con la matrice di peso migliorata per ottenere la rappresentazione vettoriale di “cane” in una dimensione = no di neuroni di livello nascosti. Nel diagramma, il numero di neuroni di livello nascosti è 3.
In poche parole, il modello Skip-gram inverte l’uso di parole target e di contesto. In questo caso, la parola di destinazione viene alimentata all’ingresso, il livello nascosto rimane lo stesso e il livello di output della rete neurale viene replicato più volte per ospitare il numero scelto di parole di contesto. Prendendo l’esempio di “cat” e “tree” come parole di contesto e “climbed” come parola target, il vettore di input nel modello skim-gram sarebbe t, mentre i due livelli di output avrebbero rispettivamente t e t come vettori target. Al posto di produrre un vettore di probabilità, due di questi vettori sarebbero prodotti per l’esempio corrente. Il vettore di errore per ogni livello di output viene prodotto nel modo descritto sopra. Tuttavia, i vettori di errore di tutti i livelli di output vengono sommati per regolare i pesi tramite backpropagation. Ciò assicura che la matrice di peso WO per ogni livello di uscita rimanga identica per tutto l’allenamento.
Abbiamo bisogno di alcune modifiche aggiuntive al modello di base skip-gram che sono importanti per rendere fattibile l’allenamento. Eseguire la discesa del gradiente su una rete neurale così grande sarà lento. E a peggiorare le cose, hai bisogno di un’enorme quantità di dati di allenamento per sintonizzare molti pesi ed evitare il montaggio eccessivo. milioni di pesi volte miliardi di campioni di formazione significa che la formazione di questo modello sta per essere una bestia. Per questo, gli autori hanno proposto due tecniche chiamate sottocampionamento e campionamento negativo in cui vengono rimosse parole insignificanti e viene aggiornato solo un campione specifico di pesi.
Mikolov et al. utilizzare anche un semplice approccio di sottocampionamento per contrastare lo squilibrio tra parole rare e frequenti nel set di allenamento (ad esempio, “in”, “the” e “a” forniscono meno valore di informazioni rispetto alle parole rare). Ogni parola nel set di allenamento viene scartata con probabilità P (wi) dove

f (wi) è la frequenza della parola wi e t è una soglia scelta, in genere intorno a 10-5.
Dettagli di implementazione
Word2vec è stato implementato in varie lingue, ma qui ci concentreremo soprattutto su Java, ad esempio, DeepLearning4j, darks-apprendimento e python . Vari algoritmi di rete neurale sono stati implementati in DL4j, il codice è disponibile su GitHub.
Per implementarlo in DL4j, eseguiremo alcuni passaggi come segue:
a) Installazione di Word2Vec
Crea un nuovo progetto in IntelliJ usando Maven. Quindi specificare proprietà e dipendenze nel POM.file xml nella directory principale del progetto.
b) Carica dati
Ora crea e assegna un nome a una nuova classe in Java. Dopo di che, si prende le frasi prime nella vostra .file txt, attraversali con il tuo iteratore e sottoponili a una sorta di pre-elaborazione, come la conversione di tutte le parole in minuscolo.
String filePath = nuova ClassPathResource (“raw_sentences.txt”).Scarica file ().getAbsolutePath ();
log.info (“Carica & Vettorializza frasi….”);
// Striscia lo spazio bianco prima e dopo per ogni riga
SentenceIterator iter = new BasicLineIterator (filePath);
Se vuoi caricare un file di testo oltre alle frasi fornite nel nostro esempio, lo faresti:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) Tokenizzare i dati
Word2vec deve essere alimentato parole piuttosto che frasi intere, quindi il passo successivo è quello di tokenizzare i dati. Per tokenizzare un testo è suddividerlo nelle sue unità atomiche, creando un nuovo token ogni volta che si colpisce uno spazio bianco, ad esempio.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) Addestramento del modello
Ora che i dati sono pronti, è possibile configurare la rete neurale Word2vec e inserire i token.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
Questa configurazione accetta diversi iperparametri. Alcuni richiedono qualche spiegazione:
- batchSize è la quantità di parole elaborate alla volta.
- minWordFrequency è il numero minimo di volte in cui una parola deve apparire nel corpus. Qui, se appare meno di 5 volte, non viene appreso. Le parole devono apparire in più contesti per imparare funzioni utili su di loro. In corpora molto grandi, è ragionevole aumentare il minimo.
- useAdaGrad-Adagrad crea un gradiente diverso per ogni caratteristica. Qui non ci occupiamo di questo.
- layerSize specifica il numero di funzioni nel vettore word. Questo è uguale al numero di dimensioni nelle caratteristichespazio. Le parole rappresentate da 500 caratteristiche diventano punti in uno spazio di 500 dimensioni.
- learningRate è la dimensione del passo per ogni aggiornamento dei coefficienti, poiché le parole vengono riposizionate nello spazio delle funzionalità.
- minLearningRate è il pavimento sul tasso di apprendimento. Il tasso di apprendimento decade quando il numero di parole su cui ti alleni diminuisce. Se il tasso di apprendimento si riduce troppo, l’apprendimento della rete non è più efficiente. Questo mantiene i coefficienti in movimento.
- iterate indica alla rete su quale batch del set di dati si sta allenando.
- tokenizer lo alimenta con le parole del batch corrente.
- vce.fit () indica alla rete configurata di iniziare l’allenamento.
e) Valutare il modello, utilizzando Word2vec
Il passo successivo è valutare la qualità dei vettori di funzionalità.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
La riga vec.similarity("word1","word2") restituirà la somiglianza del coseno delle due parole immesse. Più è vicino a 1, più la rete percepisce quelle parole come simili (vedi l’esempio Svezia-Norvegia sopra). Biru:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
Con vec.wordsNearest("word1", numWordsNearest), le parole stampate sullo schermo consentono di osservare se la rete ha raggruppato parole semanticamente simili. È possibile impostare il numero di parole più vicine che si desidera con il secondo parametro di wordsNearest. Per esempio:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec in Java in http://deeplearning4j.org/word2vec.html
7) Word2Vec e Doc2Vec in Python genism http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html