내부 링크 란 무엇입니까?
내부 링크는 링크가 있는 도메인(소스)과 동일한 도메인(대상)을 가리키는 하이퍼링크입니다. 평신도 기간안에,내부 연결은 동일한 웹사이트에 다른 페이지에 가르키는 것 이다.
코드 샘플
<a href="http://www.same-domain.com/" title="Keyword Text">Keyword Text</a>
최적의 형식
앵커 텍스트에서 소스 페이지가 타겟팅하려는 주제 또는 키워드의 감각을 제공하는 설명 키워드를 사용합니다.
내부 링크 란 무엇입니까?
내부 링크는 도메인의 한 페이지에서 동일한 도메인의 다른 페이지로 이동하는 링크입니다. 그들은 일반적으로 기본 탐색에 사용됩니다.
이러한 유형의 링크는 세 가지 이유로 유용합니다:
- 사용자가 웹 사이트를 탐색 할 수 있습니다.
- 그들은 주어진 웹 사이트에 대한 정보 계층 구조를 설정하는 데 도움이됩니다.
- 그들은 웹 사이트 주위에 링크 주식(순위 전력)을 확산 도움이됩니다.
검색 엔진 최적화 모범 사례
내부 링크는 사이트 아키텍처를 설정하고 링크 자산을 확산하는 데 가장 유용합니다. 이러한 이유로,이 섹션은 내부 링크와 검색 엔진 최적화 친화적 인 사이트 아키텍처를 구축에 관한 것입니다.
개별 페이지에서 검색 엔진은 방대한 키워드 기반 인덱스에 페이지를 나열하기 위해 콘텐츠를 볼 필요가 있습니다. 그들은 또한 크롤링할 수 있는 링크 구조—거미 웹사이트—웹사이트의 모든 페이지를 찾기 위해 경로 탐색할 수 있는 구조에 액세스할 필요가. 수천 수백 위치는 수색 엔진이 접근할 수 없는 방법에 있는 그들의 주요 연결 항법을 숨기거나 매장하기의 긴요한 실수한다. 이것은 수색 엔진 색인에서 목록으로 만들어진 페이지를 얻는 그들의 기능을 방해한다. 다음은 이 문제가 어떻게 발생할 수 있는지에 대한 설명입니다:
또는 그들이 존재 알고——직접,크롤링 링크가 해당 페이지를 가리 키지 않기 때문에 위의 예에서,구글의 다채로운 거미 페이지에 도달했습니다”에이”및 페이지에 대한 내부 링크를 본다”비”과”이자형.”그러나 중요한 페이지 씨와 디 사이트에있을 수 있습니다,거미는 그들에 도달 할 수있는 방법이 없습니다. 지금까지 구글에 관한 한,이 페이지는 기본적으로 존재하지 않는–훌륭한 콘텐츠,좋은 키워드 타겟팅,스마트 마케팅은 거미가 처음에 해당 페이지에 도달 할 수없는 경우 전혀 차이가 없습니다.
웹 사이트의 최적 구조는 피라미드(상단의 큰 점이 홈페이지)와 비슷합니다):
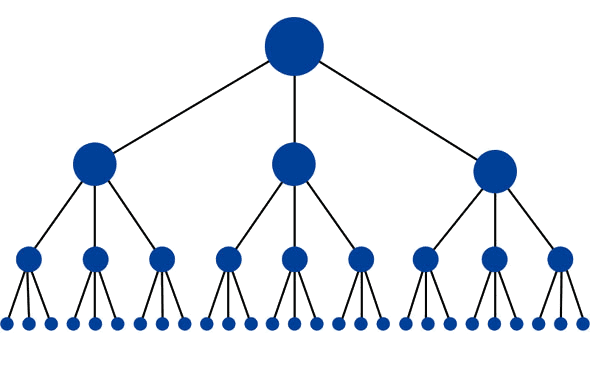
이 구조는 홈페이지와 특정 페이지 사이에 가능한 최소 링크 양을 가지고 있습니다. 이 링크 주식(순위 전력)따라서 각 페이지에 대한 순위 잠재력을 증가,전체 사이트에 걸쳐 흐를 수 있기 때문에 도움이됩니다. 이 구조는 많은 고성능 웹 사이트에서 일반적입니다(예:Amazon.com)범주 및 하위 범주 시스템의 형태.
그러나 이것은 어떻게 이루어 집니까? 이 작업을 수행하는 가장 좋은 방법은 내부 링크 및 보조 링크 구조를 사용하는 것입니다. 예를 들어 내부적으로http://www.example.com/mammals에 있는 페이지로 연결됩니다… 앵커 텍스트”고양이.”아래는 올바르게 포맷 된 내부 링크의 형식입니다. 이 링크가 도메인에 있다고 상상해보십시오 jonwye.com.

위의 그림에서””태그는 링크의 시작을 나타냅니다. 링크 태그에는 이미지,텍스트 또는 기타 객체가 포함될 수 있으며,이 모든 객체는 사용자가 다른 페이지로 이동하기 위해 참여할 수있는 페이지에서”클릭 가능한”영역을 제공합니다. 이 인터넷의 원래 개념이다:”하이퍼 링크.”링크 추천 위치는 브라우저 및 검색 엔진에 링크가 가리키는 위치를 알려줍니다. 이 예제에서는http://www.jonwye.com이 참조됩니다. 다음,검색 엔진 최적화 세계에서”앵커 텍스트”라는 방문자에 대 한 링크의 표시 부분 링크를 가리키는 페이지를 설명 합니다. 이 예에서,지적 페이지는 존 와이라는 사람에 의해 만들어진 사용자 정의 벨트에 관한 것입니다,그래서 링크는 앵커 텍스트”존 와이의 사용자 정의 설계 벨트를 사용.”</a>태그는 링크를 닫으므로 나중에 페이지의 요소에 링크 속성이 적용되지 않습니다.
이 링크의 가장 기본적인 형식입니다-그리고 그것은 검색 엔진에 저명하게 이해할 수있다. 검색 엔진 거미는 웹의 엔진 연결 도표에 이 연결을 추가해야 하고,질문 독립적인 가변을 산출하기 위하여 그것을 이용해야 한ㄴ다는 것을 알고 있다(모즈랭크같이),참조한 페이지의 내용을 색인을 붙이기 위하여 따르십시오.
다음은 페이지에 연결할 수 없으므로 색인이 생성되지 않는 몇 가지 일반적인 이유입니다.
제출 필수 양식의 링크
양식에는 드롭 다운 메뉴와 같은 기본 요소 또는 본격적인 설문 조사처럼 복잡한 요소가 포함될 수 있습니다. 어느 경우든,수색 거미는 모양을”복종시킨것을”시도하지 않으며 이렇게,모양을 통해 접근가능할텐데 연결 또는 어떤 내용은 엔진에 보이지 않는다.
내부 검색 상자를 통해서만 액세스할 수 있는 링크
스파이더는 콘텐츠를 찾기 위해 검색을 수행하지 않으므로 완전히 액세스할 수 없는 내부 검색 상자 벽 뒤에 수백만 페이지가 숨겨져 있는 것으로 추정됩니다.
구문 분석할 수 없는 자바스크립트의 링크
자바스크립트를 사용하여 구축된 링크는 구현에 따라 크롤링할 수 없거나 가중치가 평가절하될 수 있습니다. 이러한 이유로,검색 엔진 트래픽을 참조 하는 모든 페이지에 자바 스크립트 기반 링크 대신 사용 해야 하는 것이 좋습니다 중요 하다.
플래시,자바 또는 기타 플러그인의 링크
플래시,자바 애플릿 및 기타 플러그인에 포함된 모든 링크는 일반적으로 검색 엔진에 액세스할 수 없습니다.
메타 로봇 태그 또는 로봇에 의해 차단 된 페이지를 가리키는 링크.메타 로봇 태그와 로봇.사이트 소유자가 페이지에 스파이더 액세스를 제한 할 수 있습니다.
수백 또는 수천 개의 링크가 있는 페이지의 링크
검색 엔진은 모두 페이지당 150 개의 링크의 러프 크롤링 제한을 가지므로 원본 페이지에서 링크된 추가 페이지를 스파이더링하는 것을 중지할 수 있습니다. 이 제한은 다소 유연 하 고 특히 중요 한 페이지 200 또는 심지어 250 링크 다음,위쪽으로 할 수 있습니다 하지만 일반적인 연습에서 그것은 150 또는 추가 페이지를 크롤 링 하는 능력을 잃고 위험 어떤 주어진된 페이지에 링크의 수를 제한 하는 것이 현명.
프레임 또는 아이프레임의 링크
기술적으로,프레임과 아이프레임의 링크는 크롤링할 수 있지만,둘 다 조직과 다음 측면에서 엔진에 대한 구조적 문제를 제시한다. 검색 엔진이 프레임의 링크를 인덱싱하고 팔로우하는 방법에 대한 기술적 이해가 좋은 고급 사용자 만 내부 링크와 함께 이러한 요소를 사용해야합니다.
이러한 함정을 방지 하 여 웹 마 스 터는 깨끗 하 고,거미 콘텐츠 페이지에 쉽게 액세스할 수 있습니다. 링크에는 추가 속성이 적용될 수 있지만 엔진은rel="nofollow"태그를 제외하고 거의 모든 속성을 무시합니다.
사이트의 색인을 빠르게 엿볼 수 원하십니까? 모즈 프로,링크 탐색기,또는 사이트 크롤링을 실행하는 개구리 비명 같은 도구를 사용합니다. 그런 다음 크롤링이 설정된 페이지 수를 사이트를 실행할 때 나열된 페이지 수와 비교합니다.
다음 구문과 함께”따르지 않음”을 사용할 수 있습니다:
<미리><a href=”/”rel=”nofollow”>nofollow 이 링크를</a></전>
이 예제에서,추가하여rel="nofollow"속성에 링크를 태그나 웹마스터는 말 검색 엔진은 그들이 원하지 않는 이에 대한 링크를 해석할 수 있으로 정상적인,주스 전달,”편집다.”팔로우 금지는 자동화 된 블로그 댓글,방명록 및 링크 삽입 스팸을 중지하는 데 도움이되는 방법으로 제공되었지만 시간이 지남에 따라 일반적으로 전달되는 링크 값을 할인하도록 엔진을 말하는 방식으로 변모했습니다. 따르지 태그 링크는 엔진의 각각에 의해 약간 다르게 해석됩니다.
학습 유지
- 앵커 텍스트
- 링크 자본
- 웹 마스터 가이드 라인 웹 마스터에 대한 구글의 공식 가이드 라인.
- 텍스트 링크 및 페이지 랭크 구글의 웹스팸 팀장,맷 커츠’,검색 엔진 최적화와 구글에 대한 하이퍼 링크에 대한 생각.