도블레 엔지니어링 회사 기업 자산 관리|6 월 25, 2020
이 공유…

페이스 북

대표자

트위터

링크드 인 this Linkedin
데이터 및 분석의 세계는 끊임없이 진화하고 있습니다. 더 간단한 날에는 일반적인 데이터 조직이 일부 파일,응용 프로그램 또는 트랜잭션 데이터베이스,데이터웨어 하우스 및보고 데이터 마트로 구성되었습니다. 데이터 소스,볼륨,생성 속도 및 수집 프로세스가 수년에 걸쳐 성장함에 따라 오늘날의 컴퓨팅 환경은 조직이 의사 결정을 기반으로 할 수있는 패턴,추세 등을 나타내는 매우 큰 데이터 세트(일반적으로’빅 데이터’라고 함)를 처리해야합니다.
오늘날 대부분의 조직에는 그림 1 에 나와 있는 참조 아키텍처에서 애플리케이션,시스템 및 소스,데이터 전송,엔터프라이즈 데이터 계층,데이터 서비스,분석 및 보고,고급 데이터 처리 등의 구성 요소가 강조되어 있는 경우가 많습니다.
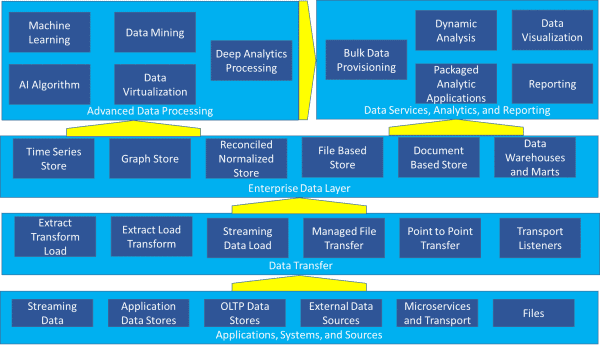
그림 1-복잡한 레퍼런스 아키텍처
데이터 웨어하우스와 마트가 28 가지 가능한 구성 요소 중 하나로 표현되어 있기 때문에 언뜻 보면 어떻게 그림에 적합한지 이해하기 어렵습니다. 그러나 대부분의 조직은 현재 데이터 웨어하우스 이상의 것에 관심을 갖고 있으며,그림 1 과 같은 복잡한 환경을 통합적으로 관리해야 합니다.
킴볼과 인몬 아키텍처는 모두 복잡한 레퍼런스 아키텍처의 개발을 돕기 위한 프레임워크를 제공한다.
두 가지 접근법에 대한 빠른 재교육
킴볼 또는 인몬 패턴을 적용하기 전에 두 접근법 간의 차이점을 검토 할 가치가 있습니다. 그림 21 과 그림 32 에서 각각의 시각적 표현을 확인하십시오.
각 모델의 창시자 인 킴볼과 인몬의 작업은 서로에게 도전했다. 두 가지 접근 방식은 주로 데이터 모델의 개발 주기에 의해 주도되지만 모델은 상향식 또는 하향식 접근 방식의 단일 초점을 기반으로합니다. 이러한 긴장은 전체 데이터 저장 및 분석 환경의 개발에서 발생했습니다.
그림 2-비주얼 킴볼

킴볼 접근 방식은 데이터 웨어하우스 및 데이터 마트가 비즈니스 프로세스 및 비즈니스 질문에 의해 구동됨을 나타냅니다. 이에 대한 명백한 위험은 정의되는 비즈니스 프로세스에 적합하지 않기 때문에 유용한 데이터가 반드시 분류되거나 캡처되지 않을 수 있다는 것입니다.
문제는 주요 주제가 차별화를 나타낼 수 있지만,이를 지원하는 엔티티는 손실 될 수있는 공통점을 나타낼 수 있다는 것입니다.
예를 들어,서비스 위치로 표시되는 미터의 위치,송장에 표시되는 청구 주소 및 자산의 재고 위치 또는 배치 위치는 모두 공통 속성을 공유할 수 있습니다. 서비스 위치,청구지 주소,자산,재고 위치 및 자산 배포 위치가 서로 다른 데이터 마트를 사용하는 조직의 서로 다른 범주를 지원하는 것으로 간주되므로 5 개의 서로 다른 개체로 나타낼 수 있는 위험이 있습니다.
인몬과 킴볼 접근법은 개념적 데이터 모델을 개발한 다음 물리화된 형태로 데이터 모델을 구현하기 위한 주기에 의해 구동된다. 이 사이클은보다 민첩한 개발 접근 방식을 지원할 수 있지만 연구의 선형성(프로세스 또는 엔터프라이즈 주제 기반),개념적 모델 개발(프로세스 또는 엔터프라이즈 주제 데이터 기반)및 물리적 모델 개발로 인해 개발 접근 방식의 폭포 유형과 가장 밀접하게 일치합니다.
다음 단계
민첩한 프로세스를 수행하면 이러한 유형의 개발 활동에 사이클을 주입하기가 어려울 수 있습니다. 모든 조직의 과제는 인몬과 킴볼 접근법에서 배운 교훈을 받아 새로운 맥락에서 적용하는 것입니다.
이 블로그 시리즈의 두 번째 부분에 와서 복잡한 환경에 패턴을 적용하는 방법에 대한 자세한 내용은-계속 지켜봐 주시기 바랍니다!
한편,엔터프라이즈 정보 관리를 성공적으로 구현하는 최근의 게시물을 확인하십시오.