in deze tutorial gaan we uitleggen, een van de opkomende en prominente woord inbedding techniek genaamd Word2Vec voorgesteld door Mikolov et al. in 2013. We hebben deze inhoud uit verschillende tutorials en bronnen verzameld om lezers op één plek te faciliteren. Ik hoop dat het helpt.
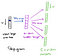
Word2vec is een combinatie van modellen die worden gebruikt om gedistribueerde representaties van woorden in een corpus voor te stellen. Word2Vec (W2V) is een algoritme dat tekstcorpus als invoer accepteert en een vectorrepresentatie voor elk woord uitvoert, zoals weergegeven in het onderstaande diagram.:

er zijn twee smaken van dit algoritme namelijk: CBOW en Skip-Gram. Gegeven een set zinnen (ook wel corpus genoemd) het model loops op de woorden van elke zin en ofwel probeert het huidige woord w te gebruiken om zijn buren (dat wil zeggen, de context) te voorspellen, deze benadering wordt “Skip-Gram” genoemd, of het gebruikt elk van deze contexten om het huidige woord w te voorspellen, in dat geval wordt de methode “continue Zak van woorden” (CBOW) genoemd. Om het aantal woorden in elke context te beperken, wordt een parameter genaamd “venstergrootte” gebruikt.

de vectoren die we gebruiken om woorden voor te stellen worden neurale woordinbeddingen genoemd, en representaties zijn vreemd. Het ene beschrijft het andere, ook al zijn die twee dingen radicaal anders. Zoals Elvis Costello zei: “schrijven over muziek is als dansen over architectuur.”Word2vec” vectorizes ” over woorden, en door dit te doen maakt natuurlijke taal computer-leesbaar — we kunnen beginnen met het uitvoeren van krachtige wiskundige bewerkingen op woorden om hun overeenkomsten te detecteren.
dus, een neuraal woord inbedding vertegenwoordigt een woord met getallen. Het is een eenvoudige, maar onwaarschijnlijke vertaling. Word2vec is vergelijkbaar met een autoencoder, die elk woord codeert in een vector, maar in plaats van te trainen tegen de invoerwoorden door middel van reconstructie, zoals een beperkte Boltzmann-machine doet, traint word2vec woorden tegen andere woorden die ze in het invoercorpus buren.
het doet dit op een van de twee manieren, hetzij met behulp van context om een doelwoord te voorspellen (een methode bekend als continue bag of words, of CBOW), of met behulp van een woord om een doelcontext te voorspellen, die skip-gram wordt genoemd. We gebruiken de laatste methode omdat het nauwkeurigere resultaten oplevert op grote datasets.

wanneer de functievector die aan een woord is toegewezen niet kan worden gebruikt om de context van dat woord nauwkeurig te voorspellen, worden de componenten van de vector aangepast. De context van elk woord in het corpus is de leraar die foutsignalen terugstuurt om de functievector aan te passen. De vectoren van woorden die door hun context gelijk worden beoordeeld, worden dichter bij elkaar gebracht door de getallen in de vector aan te passen. In deze tutorial, gaan we ons richten op Skip-Gram model dat in tegenstelling tot CBOW center woord beschouwen als input zoals weergegeven in figuur hierboven en voorspellen context woorden.
modeloverzicht
we begrepen dat we een vreemd neuraal netwerk moeten voeden met een paar woorden, maar we kunnen dat niet gewoon doen door de werkelijke karakters als invoer te gebruiken, we moeten een manier vinden om deze woorden wiskundig weer te geven zodat het netwerk ze kan verwerken. Een manier om dit te doen is om een woordenschat van alle woorden in onze tekst te creëren en dan ons woord te coderen als een vector van dezelfde dimensies van onze woordenschat. Elke dimensie kan worden beschouwd als een woord in onze woordenschat. Dus we hebben een vector met alle nullen en een 1 die het overeenkomstige woord in de woordenschat vertegenwoordigt. Deze codering techniek heet one-hot codering. Gezien ons voorbeeld, als we een woordenschat hebben die bestaat uit de woorden “de”, “snel”, “bruin”, “vos”, “springt”, “over”, “de” “lui”, “hond”, wordt het woord “bruin” weergegeven door deze vector: .

het Skip-gram model neemt een corpus van tekst in en creëert een hot-vector voor elk woord. Een hete vector is een vectorrepresentatie van een woord waarbij de vector de grootte van de woordenschat is (totaal unieke woorden). Alle dimensies zijn ingesteld op 0, behalve de dimensie die het woord vertegenwoordigt dat op dat moment als input wordt gebruikt. Hier is een voorbeeld van een hete vector:

de bovenstaande invoer wordt gegeven aan een neuraal netwerk met een enkele verborgen laag.
we gaan een invoerwoord zoals “ants” representeren als een één-hete vector. Deze vector zal 10.000 componenten hebben (één voor elk woord in onze woordenschat) en we zullen een “1” plaatsen in de positie die overeenkomt met het woord “mieren”, en 0s in alle andere posities. De output van het netwerk is een enkele vector (ook met 10.000 componenten) die, voor elk woord in onze woordenschat, de kans bevat dat een willekeurig gekozen woord in de buurt dat woordenschat woord is.
in word2vec wordt een gedistribueerde weergave van een woord gebruikt. Neem een vector met enkele honderden dimensies (zeg 1000). Elk woord wordt vertegenwoordigd door een verdeling van gewichten over die elementen. Dus in plaats van een één-op-één afbeelding tussen een element in de vector en een woord, wordt de representatie van een woord verspreid over alle elementen in de vector, en elk element in de vector draagt bij aan de definitie van veel woorden.
als ik de dimensies in een hypothetische woordvector label (er zijn natuurlijk geen dergelijke vooraf toegewezen labels in het algoritme), kan het er ongeveer zo uitzien:

zo ’n vector komt op een abstracte manier de’ Betekenis ‘ van een woord weer te geven. En zoals we hierna zullen zien, eenvoudig door het onderzoeken van een groot corpus is het mogelijk om woordvectoren te leren die in staat zijn om de relaties tussen woorden op een verrassend expressieve manier vast te leggen. We kunnen de vectoren ook gebruiken als input voor een neuraal netwerk. Aangezien onze invoervectoren één-heet zijn, komt het vermenigvuldigen van een invoervector met de gewichtsmatrix W1 neer op het simpelweg selecteren van een rij uit W1.

van de verborgen laag tot de uitvoerlaag kan de tweede gewichtsmatrix W2 worden gebruikt om een score te berekenen voor elk woord in de woordenschat, en softmax kan worden gebruikt om de posterieure verdeling van woorden te verkrijgen. Het skip-gram model is het tegenovergestelde van het CBOW model. Het is geconstrueerd met het scherpstelwoord als de enkele invoervector, en de doelcontextwoorden bevinden zich nu op de uitvoerlaag. De activeringsfunctie voor de verborgen laag komt simpelweg neer op het kopiëren van de corresponderende rij van de gewichten matrix W1 (lineair) zoals we eerder zagen. Op de uitvoerlaag geven we nu C multinomiale distributies uit in plaats van slechts één. Het trainingsdoel is het nabootsen van de samengevatte voorspellingsfout in alle contextwoorden in de uitvoerlaag. In ons voorbeeld zou de input “learning” zijn, en we hopen te zien (“an”, “efficient”, “method”, “for”, “high”, “quality”, “distributed”, “vector”) op de uitvoerlaag.
hier is de architectuur van ons neurale netwerk.

in ons voorbeeld gaan we zeggen dat we woordvectoren leren met 300 functies. Dus de verborgen laag wordt vertegenwoordigd door een gewichtsmatrix met 10.000 rijen (één voor elk woord in onze woordenschat) en 300 kolommen (één voor elk verborgen neuron). 300 functies is wat Google gebruikt in hun gepubliceerde model getraind op de Google news dataset (u kunt het downloaden vanaf hier). Het aantal functies is een” hyper parameter ” die je zou moeten afstemmen op uw toepassing (dat wil zeggen, Probeer verschillende waarden en zie wat levert de beste resultaten).
als je naar de rijen van deze gewichtsmatrix kijkt, dan zijn dit onze woordvectoren!

dus het einddoel van dit alles is eigenlijk alleen maar om deze verborgen laag gewicht matrix te leren-de output laag die we gewoon gooien als we klaar zijn! De 1 x 300 woord vector voor “mieren” wordt dan gevoed aan de uitvoerlaag. De uitvoerlaag is een softmax regressie classifier. Specifiek, heeft elk outputneuron een gewichtsvector die het tegen de woordvector van de verborgen laag vermenigvuldigt, dan past het de functie exp(x) op het resultaat toe. Tot slot, om de uitgangen te laten optellen tot 1, delen we dit resultaat door de som van de resultaten van alle 10.000 outputknooppunten. Hier is een illustratie van het berekenen van de output van de output neuron voor het woord “auto”.

als twee verschillende woorden zeer vergelijkbare “contexten” hebben (dat wil zeggen, welke woorden er waarschijnlijk om hen heen zullen verschijnen), dan moet ons model zeer vergelijkbare resultaten voor deze twee woorden produceren. Een manier voor het netwerk om vergelijkbare contextvoorspellingen uit te voeren voor deze twee woorden is als de woordvectoren vergelijkbaar zijn. Dus, als twee woorden vergelijkbare contexten hebben, dan is ons netwerk gemotiveerd om soortgelijke woordvectoren voor deze twee woorden te leren! Ta da!
elke dimensie van de invoer gaat door elk knooppunt van de verborgen laag. De dimensie wordt vermenigvuldigd met het gewicht dat het naar de verborgen laag leidt. Omdat de invoer een hete vector is, zal slechts één van de invoerknooppunten een niet-nulwaarde hebben (namelijk de waarde 1). Dit betekent dat Voor een woord alleen de gewichten geassocieerd met de invoerknooppunt met waarde 1 worden geactiveerd, zoals weergegeven in de afbeelding hierboven.
omdat de invoer in dit geval een hete vector is, zal slechts één van de invoerknooppunten een niet-nulwaarde hebben. Dit betekent dat alleen de gewichten verbonden met dat invoerknooppunt worden geactiveerd in de verborgen knooppunten. Een voorbeeld van de gewichten die in aanmerking worden genomen is hieronder afgebeeld voor het tweede woord in de woordenschat:
de vectorweergave van het tweede woord in de woordenschat (weergegeven in het neurale netwerk hierboven) ziet er als volgt uit, eenmaal geactiveerd in de verborgen laag:
die gewichten beginnen als willekeurige waarden. Het netwerk wordt vervolgens getraind om de gewichten aan te passen om de invoerwoorden weer te geven. Dit is waar de uitvoerlaag belangrijk wordt. Nu we ons in de verborgen laag bevinden met een vectorweergave van het woord, hebben we een manier nodig om te bepalen hoe goed we hebben voorspeld dat een woord in een bepaalde context past. De context van het woord is een verzameling woorden in een venster eromheen, zoals hieronder getoond:

de bovenstaande afbeelding laat zien dat de context voor vrijdag woorden als “kat” en “is”bevat. Het doel van het neurale netwerk is om te voorspellen dat “vrijdag” binnen deze context valt.
we activeren de uitvoerlaag door de vector te vermenigvuldigen die we door de verborgen laag passeerden (dat was de invoer hete vector * gewichten die verborgen knoop invoerden) met een vectorrepresentatie van het contextwoord (dat is de hete vector voor het contextwoord * gewichten die het uitvoerknooppunt invoeren). De status van de uitvoerlaag voor het eerste contextwoord kan hieronder worden weergegeven:

de bovenstaande vermenigvuldiging wordt gedaan voor elk woord naar context woordpaar. We berekenen dan de kans dat een woord hoort bij een set context woorden met behulp van de waarden die voortvloeien uit de verborgen en output lagen. Ten slotte passen we stochastische gradiëntafdaling toe om de waarden van de gewichten te veranderen om een meer wenselijke waarde voor de berekende waarschijnlijkheid te krijgen.
bij gradiëntafdaling moeten we de gradiënt berekenen van de functie die wordt geoptimaliseerd op het punt dat het gewicht weergeeft dat we veranderen. De gradiënt wordt vervolgens gebruikt om de richting te kiezen waarin een stap wordt gezet om naar het lokale optimum te gaan, zoals weergegeven in het minimaliseringsvoorbeeld hieronder.
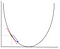
het gewicht zal worden veranderd door een stap in de richting van het optimale punt (in het bovenstaande voorbeeld, het laagste punt in de grafiek). De nieuwe waarde wordt berekend door van de huidige gewichtswaarde de afgeleide functie af te trekken op het punt van het gewicht geschaald door de leersnelheid. De volgende stap is het gebruik van Backpropagation, om de gewichten tussen meerdere lagen aan te passen. De fout die wordt berekend aan het einde van de uitvoerlaag wordt teruggestuurd van de uitvoerlaag naar de verborgen laag door de kettingregel toe te passen. Gradiëntafdaling wordt gebruikt om de gewichten tussen deze twee lagen bij te werken. De fout wordt vervolgens op elke laag aangepast en verder teruggestuurd. Hier is een diagram om backpropagation weer te geven:

het gebruik van voorbeeld
Word2vec maakt gebruik van een enkel verborgen laag, volledig verbonden neuraal netwerk zoals hieronder weergegeven. De neuronen in de verborgen laag zijn allemaal lineaire neuronen. De invoerlaag is ingesteld om zoveel neuronen te hebben als er woorden in de woordenschat voor training zijn. De verborgen laaggrootte is ingesteld op de dimensionaliteit van de resulterende woordvectoren. De grootte van de uitvoerlaag is gelijk aan de invoerlaag. Dus, als de woordenschat voor het leren van woordvectoren bestaat uit V woorden en N om de dimensie van woordvectoren te zijn, kan de invoer naar verborgen laagverbindingen worden vertegenwoordigd door matrix WI van grootte VxN met elke rij die een woordenschat woord vertegenwoordigt. Op dezelfde manier kunnen de verbindingen van verborgen laag naar uitvoerlaag worden beschreven door matrix WO van grootte NxV. In dit geval vertegenwoordigt elke kolom van de WO matrix een woord uit de gegeven woordenschat.

de invoer in het netwerk wordt gecodeerd met behulp van” 1-out of-V ” representatie wat betekent dat slechts één invoerlijn op één is ingesteld en de rest van de invoerlijnen op nul zijn ingesteld.
stel dat we een trainingscorpus hebben met de volgende zinnen:
“de hond zag een kat”,” de hond achtervolgde de kat”,”de kat klom in een boom”
het corpus-vocabulaire bestaat uit acht woorden. Eenmaal alfabetisch geordend, kan elk woord worden verwezen door de index. In dit voorbeeld zal ons neurale netwerk acht ingangsneuronen en acht outputneuronen hebben. Laten we aannemen dat we besluiten om drie neuronen in de verborgen laag te gebruiken. Dit betekent dat WI en WO respectievelijk 8×3 en 3×8 matrices zullen zijn. Voordat de training begint, worden deze matrices geïnitialiseerd tot kleine willekeurige waarden zoals gebruikelijk is in neurale netwerk training. Ter illustratie, laten we aannemen dat WI en WO geïnitialiseerd worden naar de volgende waarden:

stel dat we willen dat het netwerk de relatie tussen de woorden “kat” en “klom”te leren. Dat wil zeggen, het netwerk moet een grote kans op “Climb” tonen wanneer ” cat ” wordt ingevoerd in het netwerk. In woordinbedding terminologie, het woord “kat” wordt aangeduid als de context woord en het woord “klom” wordt aangeduid als het doel woord. In dit geval zal de invoervector X t zijn. merk op dat alleen de tweede component van de vector 1 is. Dit komt omdat het invoerwoord “cat” is die nummer twee positie in gesorteerde lijst van corpus woorden houdt. Gezien het feit dat het doelwoord “beklommen” is, zal de doelvector eruit zien als t. met de invoervector die “cat” vertegenwoordigt, kan de uitvoer op de verborgen laag neuronen worden berekend als:
Ht = XtWI =
het zal ons niet verbazen dat de vector H van verborgen neuronuitgangen de gewichten van de tweede rij van de WI-matrix nabootst vanwege 1-out-of-Vrepresentatie. Dus de functie van de ingang naar verborgen laagverbindingen is in principe om de invoerwoordvector naar verborgen laag te kopiëren. Het uitvoeren van soortgelijke manipulaties voor verborgen naar output laag, de activatievector voor output layer neuronen kan worden geschreven als
HtWO =
aangezien, het doel is produceren waarschijnlijkheden voor woorden in de output laag, Pr(wordk|wordcontext) voor k = 1, V, om hun volgende woord relatie met de context woord bij invoer weer te geven, hebben we de som van neuron outputs in de output laag om toe te voegen aan een. Word2vec bereikt dit door activeringswaarden van outputneuronen om te zetten in waarschijnlijkheden met behulp van de softmax-functie. Dus de uitgang van de k-de neuron wordt berekend door de volgende expressie waar activering(n) vertegenwoordigt de activatie waarde van de n-de output-laag neuron:
Zo, de kansen voor acht woorden in het corpus zijn:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
De kans in het vet is voor de gekozen doelgroep woord “beklommen”. Gegeven de doelvector t, wordt de foutvector voor de outputlaag gemakkelijk berekend door de waarschijnlijkheidsvector van de doelvector af te trekken. Zodra de fout bekend is, kunnen de gewichten in de matrices WO en WI worden bijgewerkt met behulp van backpropagation. Zo kan de training doorgaan door het presenteren van verschillende context-doel woorden paar van het corpus. Dit is hoe Word2vec relaties tussen woorden leert en in het proces vectorrepresentaties ontwikkelt voor woorden in het corpus.
het idee achter word2vec is om woorden weer te geven door een vector van reële getallen van dimensie d. Daarom is de tweede matrix de representatie van die woorden. De i-de lijn van deze matrix is de vectorweergave van het i-de woord. Laten we zeggen dat je in je Voorbeeld 5 woorden hebt : , dan betekent de eerste vector dat je het woord “paard” overweegt en dus is de representatie van “paard”. Op dezelfde manier is de representatie van het woord “Leeuw”.

voor zover ik weet, is er geen “menselijke betekenis” specifiek voor elk van de nummers in deze voorstellingen. Een getal vertegenwoordigt niet als het woord een werkwoord is of niet, een bijvoeglijk naamwoord of niet… het is gewoon de gewichten die u verandert om uw optimalisatie probleem op te lossen om de representatie van uw woorden te leren.
een visueel diagram dat het beste wordt uitgewerkt in word2vec-matrixvermenigvuldigingsproces wordt weergegeven in de volgende figuur:

de eerste matrix vertegenwoordigt de invoervector in één hot formaat. De tweede matrix vertegenwoordigt de synaptische gewichten van de inputlaag neuronen aan de verborgen laag neuronen. Let vooral op de linker bovenhoek waar de Input Layer matrix wordt vermenigvuldigd met de Gewichtsmatrix. Kijk nu naar de rechterbovenhoek. Deze matrix vermenigvuldiging InputLayer dot-producted met gewichten transponeren is gewoon een handige manier om het neurale netwerk aan de rechterbovenhoek weer te geven.
het eerste deel, vertegenwoordigt het invoerwoord als een één hete vector en de andere matrix vertegenwoordigt het gewicht voor de verbinding van elk van de inputlaag neuronen met de verborgen laag neuronen. Als Word2Vec treinen, het backpropagates (met behulp van gradiënt afdaling) in deze gewichten en verandert ze om een betere weergave van woorden als vectoren te geven. Zodra de training is voltooid, gebruik je alleen deze gewichtsmatrix, neem voor Zeg ‘ hond ‘en vermenigvuldig het met de verbeterde gewichtsmatrix om de vectorweergave van’ hond ‘ in een dimensie = Nee Van verborgen laag neuronen te krijgen. In het diagram is het aantal verborgen laagneuronen 3.
In een notendop keert het skip-gram-model het gebruik van doel-en contextwoorden om. In dit geval wordt het doelwoord ingevoerd bij de invoer, blijft de verborgen laag hetzelfde en wordt de uitvoerlaag van het neurale netwerk meerdere keren gerepliceerd om het gekozen aantal contextwoorden op te nemen. Door het voorbeeld van “cat” en “tree” als contextwoorden en “climb” als doelwoord te nemen, zou de invoervector in het skim-gram model t zijn, terwijl de twee uitvoerlagen respectievelijk T en t als doelvectoren zouden hebben. In plaats van het produceren van een vector van waarschijnlijkheden, twee dergelijke vectoren zou worden geproduceerd voor het huidige voorbeeld. De foutvector voor elke uitvoerlaag wordt geproduceerd op de manier zoals hierboven besproken. De foutvectoren van alle uitvoerlagen worden echter samengevat om de gewichten aan te passen via backpropagation. Dit zorgt ervoor dat de gewichtsmatrix WO voor elke uitgangslaag tijdens de training identiek blijft.
er zijn weinig extra aanpassingen nodig aan het basismodel voor skip-gram die belangrijk zijn om het mogelijk te maken om te trainen. Een gradiëntafdaling op zo ‘ n groot neuraal netwerk zal langzaam zijn. En om het nog erger te maken, heb je een enorme hoeveelheid trainingsgegevens nodig om zoveel gewichten af te stemmen en te veel passen te voorkomen. miljoenen gewichten maal miljarden trainingsstalen betekent dat het trainen van dit model een beest wordt. Hiervoor hebben de auteurs twee technieken voorgesteld die subsampling en negatieve sampling worden genoemd, waarbij onbeduidende woorden worden verwijderd en alleen een specifieke steekproef van gewichten wordt bijgewerkt.
Mikolov et al. gebruik ook een eenvoudige subsamplingbenadering om de onbalans tussen zeldzame en frequente woorden in de trainingsset tegen te gaan (bijvoorbeeld “in”, “de” en “a” bieden minder informatiewaarde dan zeldzame woorden). Elk woord in de trainingsset wordt weggegooid met waarschijnlijkheid P (wi) waarbij

f (wi) is de frequentie van het woord wi en t is een gekozen drempel, meestal rond 10-5.
implementatiedetails
Word2vec is geïmplementeerd in verschillende talen, maar hier zullen we ons vooral richten op Java, d.w.z., DeepLearning4j, darks-learning en python . Verschillende neurale net algoritmen zijn geïmplementeerd in DL4j, code is beschikbaar op GitHub.
om het in DL4j te implementeren, zullen we enkele stappen doorlopen die als volgt worden gegeven:
a) Word2Vec Setup
Maak een nieuw project aan in IntelliJ met behulp van Maven. Specificeer vervolgens Eigenschappen en afhankelijkheden in de POM.xml-bestand in de hoofdmap van uw project.
b) Laad gegevens
maak en geef een nieuwe klasse een naam in Java. Daarna neem je de ruwe zinnen in je .txt bestand, doorkruis ze met je iterator, en onderwerpen ze aan een soort van pre-processing, zoals het omzetten van alle woorden in kleine letters.
String filePath = new ClassPathResource (“raw_sentences.txt”).getFile ().getAbsolutePath ();
log.info (“Load & vectorize zinnen….”);
// witruimte voor en na strippen voor elke regel
SentenceIterator iter = new BasicLineIterator (filePath);
als u een tekstbestand naast de zinnen in ons voorbeeld wilt laden, zou u dit doen:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) tokeniseren van de gegevens
Word2vec moet worden gevoed met woorden in plaats van hele zinnen, dus de volgende stap is het tokeniseren van de gegevens. Tokenize een tekst is om het op te splitsen in zijn atomaire eenheden, het creëren van een nieuw token elke keer dat u een witruimte, bijvoorbeeld.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) Training van het Model
nu de gegevens klaar zijn, kunt u het word2vec neural net configureren en de tokens invoeren.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
Deze configuratie accepteert meerdere hyperparameters. Een paar vereisen enige uitleg:
- batchSize is de hoeveelheid woorden die u tegelijkertijd verwerkt.
- minwordfrequentie is het minimum aantal keren dat een woord in het corpus moet voorkomen. Hier, als het minder dan 5 keer lijkt, is het niet geleerd. Woorden moeten in meerdere contexten verschijnen om nuttige functies over hen te leren. Bij zeer grote corpora is het redelijk om het minimum te verhogen.
- useAdaGrad-Adagrad maakt een ander verloop voor elke functie. Daar gaat het ons hier niet om.
- laaggrootte specificeert het aantal functies in de word-vector. Dit is gelijk aan het aantal dimensies in de featurespace. Woorden vertegenwoordigd door 500 functies worden punten in een 500-dimensionale ruimte.
- learningRate is de stapgrootte voor elke update van de coëfficiënten, omdat woorden worden verplaatst in de functieruimte.
- het minlearningpercentage is de ondergrens van het leerpercentage. Leersnelheid vervalt naarmate het aantal woorden waarop je traint afneemt. Als de leersnelheid te veel krimpt, is het leren van het net niet langer efficiënt. Dit houdt de coëfficiënten in beweging.
- iteraat vertelt het net op welke batch van de dataset het traint.
- tokenizer geeft het de woorden van de huidige partij.
- vec.fit() vertelt het geconfigureerde net om te beginnen met trainen.
e) het model evalueren met Word2vec
de volgende stap is het evalueren van de kwaliteit van uw functievectoren.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
de regel vec.similarity("word1","word2") geeft de cosinus overeenkomst van de twee woorden die u invoert. Hoe dichter het bij 1 is, hoe meer het net deze woorden waarneemt (zie Het Zweden-Noorwegen voorbeeld hierboven). Bijvoorbeeld:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
met vec.wordsNearest("word1", numWordsNearest) kunt u zien of het net semantisch vergelijkbare woorden heeft geclusterd. U kunt het aantal dichtstbijzijnde woorden die u wilt instellen met de tweede parameter van wordsNearest. Bijvoorbeeld:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec in Java in http://deeplearning4j.org/word2vec.html
7) Word2Vec en Doc2Vec in Python in genism http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html