By Doble Engineering Company in Enterprise Asset Management / June 25, 2020
Deel dit…

Facebook

Pinterest

Twitter

Linkedin
de wereld van data en analytics evolueert voortdurend. In zijn eenvoudigere dagen, typische data organisatie bestond uit een aantal bestanden, applicatie of transactionele databases, data warehouses, en rapportage data marts. Aangezien gegevensbronnen, volumes, generatiesnelheden en het verzamelproces in de loop der jaren zijn gegroeid, moet de huidige computeromgeving te maken hebben met extreem grote datasets – meestal aangeduid als ‘big data’ – die patronen, trends en meer onthullen, waarop organisaties beslissingen kunnen baseren.
de meeste organisaties hebben tegenwoordig veel, zo niet alle, van de componenten die in de referentiearchitectuur worden belicht in Figuur 1 – toepassingen, systemen en bronnen, gegevensoverdracht, enterprise data layer, data services, analytics, and reporting, en geavanceerde gegevensverwerking.
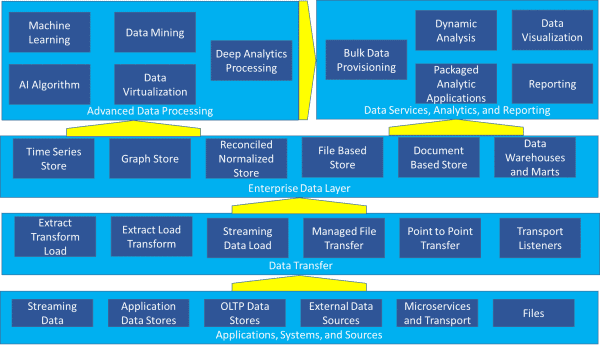
figuur 1-complexe referentiearchitectuur
met data warehouse en marts als een van de 28 mogelijke componenten, is het moeilijk te begrijpen hoe ze op het eerste gezicht in het beeld passen. Maar de meeste organisaties zijn momenteel bezig met meer dan een datawarehouse – ze moeten coherent beheren van een complexe omgeving zoals afgebeeld in Figuur 1.
Kimball en Inmon architecturen bieden beide kaders om te helpen bij de ontwikkeling van complexe referentiearchitectuur.
snel opfrissen op de twee benaderingen
voordat de Kimball-of Inmon-patronen worden toegepast, is het de moeite waard de verschillen tussen de twee benaderingen te bekijken. Bekijk de visuele representaties van elk in Figuur 21 en figuur 32 .
het werk van Kimball en Inmon – de oprichters van de respectieve modellen – daagde elkaar uit. Terwijl beide benaderingen voornamelijk worden gedreven door de ontwikkelingscyclus van een datamodel, zijn de modellen gebaseerd op een single-minded focus van ofwel een bottom-up, of een top-down benadering. Deze spanningen speelden zich af in de ontwikkeling van de Algemene gegevensopslag-en analytics-omgevingen.
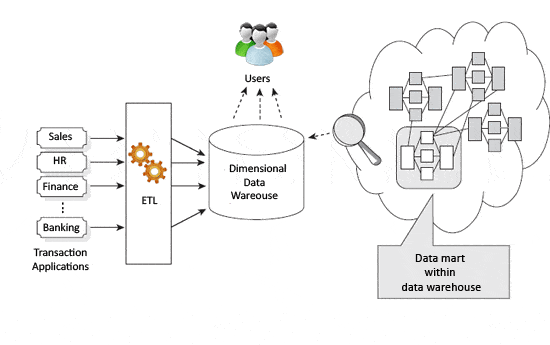
Figuur 2-visuele Kimball

Figuur 3-Visual Inmon View
de Kimball-benadering geeft aan dat datawarehouses en datamart ‘ s worden gedreven door bedrijfsprocessen en zakelijke vragen. Het voor de hand liggende gevaar voor dit is nuttige gegevens niet noodzakelijkerwijs worden gecategoriseerd of gevangen, omdat het niet zou passen binnen het bedrijfsproces wordt gedefinieerd.
de Inmon-benadering geeft de oprichting aan van een enterprise data warehouse met logische modellen die ontworpen zijn voor elke entiteit rond een onderwerp, zoals meter, factuur en activa. De uitdaging is dat de hoofdthema ‘ s differentiatie kunnen vertegenwoordigen, maar dat de entiteiten die ze ondersteunen overeenkomsten kunnen vertegenwoordigen die verloren kunnen gaan.
bijvoorbeeld de locatie van een meter zoals weergegeven door een servicelocatie, het factuuradres zoals weergegeven in de factuur en de inventarislocatie of implementatielocatie van een actief kunnen alle gemeenschappelijke kenmerken delen. Zelfs onder Inmon bestaat het gevaar dat de servicelocatie, factuuradres, asset, inventarislocatie en assetlocatie worden weergegeven als vijf verschillende objecten, omdat ze worden beschouwd als verschillende verticals in de organisatie met verschillende datamartsondersteuning.
zowel de Inmon-als Kimball-benadering wordt door de cyclus aangestuurd om het conceptuele datamodel te ontwikkelen en vervolgens de datamodellen in een fysicaliseerde vorm te implementeren. Deze cyclus kan meer flexibele ontwikkelingsbenaderingen ondersteunen, maar zal het meest nauw aansluiten bij een waterval type ontwikkelingsbenaderingen vanwege de lineariteit van het onderzoek (gebaseerd op het proces of bedrijfsthema), de ontwikkeling van het conceptuele model (gebaseerd op de data in het proces of het bedrijfsthema) en de ontwikkeling van het fysieke model.
de volgende stap zetten
een flexibel proces kan het moeilijk maken om cycli in dit type ontwikkelingsactiviteit te injecteren. De uitdaging voor elke organisatie zal zijn om de lessen uit de Inmon en Kimball benaderingen te nemen en toe te passen in een nieuwe context.
meer details over hoe de patronen toe te passen op een complexe omgeving te komen in deel twee van deze blog serie – stay tuned!
bekijk ondertussen onze recente post over het succesvol implementeren van enterprise information management (EIM).