- Wat zijn interne links?
- Code Sample
- optimaal formaat
- Wat is een interne Link?
- SEO Best Practice
- Links in Indieningsvereiste formulieren
- Links die alleen toegankelijk zijn via interne zoekvakken
- Links in On-Parseable Javascript
- Links in Flash, Java of andere Plug-ins
- Links naar pagina ‘ s die geblokkeerd zijn door de meta Robots Tag of Robots.txt
- Links op pagina ’s met honderden of duizenden Links
- koppelingen in Frames of I-Frames
- blijf leren
Wat zijn interne links?
interne koppelingen zijn hyperlinks die wijzen op (doel) hetzelfde domein als het domein waarop de koppeling bestaat (bron). In lekentaal, een interne link is er een die verwijst naar een andere pagina op dezelfde website.
Code Sample
<a href="http://www.same-domain.com/" title="Keyword Text">Keyword Text</a>
optimaal formaat
gebruik beschrijvende trefwoorden in ankertekst die een idee geven van het onderwerp of de trefwoorden waarop de bronpagina zich probeert te richten.
Wat is een interne Link?
interne links zijn links die van een pagina op een domein naar een andere pagina op hetzelfde domein gaan. Ze worden vaak gebruikt in de belangrijkste navigatie.
dit soort links zijn om drie redenen nuttig:
- ze stellen gebruikers in staat om een website te navigeren.
- zij helpen informatiehiërarchie voor de gegeven website tot stand te brengen.
- ze helpen om equity (Ranking power) over websites te spreiden.
SEO Best Practice
interne links zijn het nuttigst voor het opzetten van sitearchitectuur en het verspreiden van link equity (URL ‘ s zijn ook essentieel). Om deze reden, dit gedeelte gaat over het bouwen van een SEO-vriendelijke site architectuur met interne links.
op een afzonderlijke pagina moeten zoekmachines de inhoud zien om pagina ‘ s in hun enorme op trefwoorden gebaseerde indices op te nemen. Ze moeten ook toegang hebben tot een crawleable link structuur—een structuur waarmee spiders bladeren door de paden van een website—om alle pagina ‘ s op een website te vinden. Honderdduizenden sites maken de kritieke fout van het verbergen of begraven van hun belangrijkste link navigatie op manieren die zoekmachines niet kunnen toegang. Dit belemmert hun mogelijkheid om pagina’ s in de indexen van de zoekmachines te krijgen. Hieronder is een illustratie van hoe dit probleem kan gebeuren:
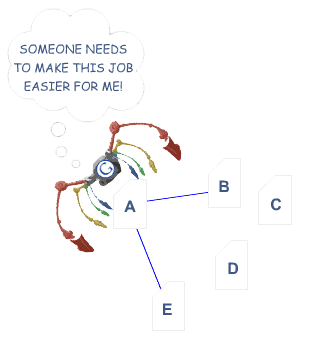
in het bovenstaande voorbeeld heeft Google ‘ s kleurrijke spider pagina “A” bereikt en ziet interne links naar pagina ‘ s “B” en “E.” hoe belangrijk pagina ’s C en D ook zijn voor de site, de spider heeft geen manier om ze te bereiken—of zelfs weten dat ze bestaan—omdat er geen directe, crawlerbare links naar die pagina’ s wijzen. Voor zover Google betreft, deze pagina ’s in principe niet bestaan–grote inhoud, goede keyword targeting, en slimme marketing maken geen verschil helemaal niet als de spinnen niet kunnen bereiken die pagina’ s in de eerste plaats.
de optimale structuur voor een website zou lijken op een piramide (waar de grote punt bovenaan de homepage is):
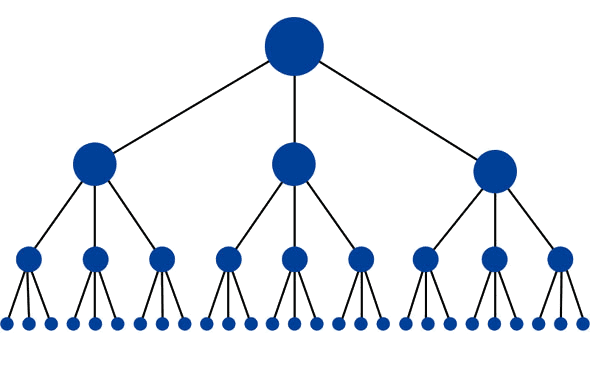
deze structuur heeft de minimale hoeveelheid links mogelijk tussen de homepage en een bepaalde pagina. Dit is handig omdat het link equity (ranking power) mogelijk maakt om door de hele site te stromen, waardoor het ranking potentieel voor elke pagina wordt vergroot. Deze structuur is gebruikelijk op veel goed presterende websites (zoals Amazon.com) in de vorm van categorie-en subcategorie-systemen.
maar hoe wordt dit bereikt? De beste manier om dit te doen is met interne links en aanvullende URL structuren. Ze linken bijvoorbeeld intern naar een pagina op http://www.example.com/mammals… met de ankertekst ” cats.”Hieronder is het formaat voor een correct geformatteerde interne link. Stel je voor dat deze link op het domein staat jonwye.com.

in de bovenstaande afbeelding geeft de ” a ” tag het begin van een link aan. Link-tags kunnen afbeeldingen, tekst of andere objecten bevatten, die allemaal een “klikbaar” gebied op de pagina bieden dat gebruikers kunnen inschakelen om naar een andere pagina te gaan. Dit is het oorspronkelijke concept van het Internet: “hyperlinks.”De link referral locatie vertelt de browser-en de zoekmachines-waar de link wijst. In dit voorbeeld wordt verwezen naar de URL http://www.jonwye.com. Vervolgens beschrijft het zichtbare gedeelte van de link voor bezoekers, genaamd “anchor text” in de SEO wereld, de pagina waar de link naar wijst. In dit voorbeeld gaat de pagina waarnaar wordt verwezen over custom belts gemaakt door een man genaamd Jon Wye, dus de link gebruikt de ankertekst “Jon Wye’ s Custom Designed Belts.”Het </a> label sluit de link, zodat elementen later op de pagina niet het link attribuut op hen zullen worden toegepast.
dit is het meest basale formaat van een link—en het is zeer begrijpelijk voor de zoekmachines. De zoekmachine spiders weten dat ze deze link moeten toevoegen aan de link grafiek van de motor van het web, gebruiken om query-onafhankelijke variabelen te berekenen (zoals MozRank), en volg het om de inhoud van de pagina waarnaar wordt verwezen indexeren.
hieronder vindt u enkele veel voorkomende redenen waarom pagina ‘ s mogelijk niet bereikbaar zijn en dus niet geïndexeerd zijn.
Links in Indieningsvereiste formulieren
formulieren kunnen elementen bevatten die zo eenvoudig zijn als een keuzemenu of elementen die zo complex zijn als een volledige enquête. In beide gevallen zal search spiders niet proberen om formulieren” in te dienen ” en dus zijn alle inhoud of links die toegankelijk zijn via een formulier onzichtbaar voor de motoren.
Links die alleen toegankelijk zijn via interne zoekvakken
Spiders zullen niet proberen om zoekopdrachten uit te voeren om inhoud te vinden, en daarom wordt geschat dat miljoenen pagina ‘ s verborgen zijn achter volledig ontoegankelijke interne zoekvakken.
Links in On-Parseable Javascript
Links die met Javascript zijn gebouwd, kunnen ofwel onkrawlable of gedevalueerd in gewicht zijn, afhankelijk van hun implementatie. Om deze reden, is het raadzaam dat standaard HTML links moeten worden gebruikt in plaats van Javascript gebaseerde links op elke pagina waar zoekmachine doorverwezen verkeer is belangrijk.
Links in Flash, Java of andere Plug-ins
links in Flash, Java-applets en andere plug-ins zijn meestal niet toegankelijk voor zoekmachines.
Links naar pagina ‘ s die geblokkeerd zijn door de meta Robots Tag of Robots.txt
de Meta Robots tag en de robots.txt-bestand beide staan een site-eigenaar om spider toegang tot een pagina te beperken.
Links op pagina ’s met honderden of duizenden Links
de zoekmachines hebben allemaal een ruwe crawl limiet van 150 links per pagina voordat ze kunnen stoppen met het spideren van extra pagina’ s waarnaar wordt gelinkt van de oorspronkelijke pagina. Deze limiet is enigszins flexibel, en bijzonder belangrijke pagina ’s kunnen meer dan 200 of zelfs 250 links gevolgd, maar in de algemene praktijk, is het verstandig om het aantal links op een bepaalde pagina te beperken tot 150 of het risico verliezen van de mogelijkheid om extra pagina’ s gekropen.
koppelingen in Frames of I-Frames
technisch gezien zijn koppelingen in zowel frames als I-Frames crawlerbaar, maar beide vormen structurele problemen voor de motoren in termen van organisatie en volgende. Alleen gevorderde gebruikers met een goede technische kennis van hoe zoekmachines index en volg links in frames moeten deze elementen gebruiken in combinatie met interne koppeling.
door deze valkuilen te vermijden, kan een webmaster schone, spiderable HTML-links hebben waarmee spiders gemakkelijk toegang hebben tot hun inhoudspagina ‘ s. Links kunnen extra attributen hebben, maar de engines negeren bijna al deze attributen, met uitzondering van de tag rel="nofollow".
wilt u snel een kijkje nemen in de indexatie van uw site? Gebruik een tool zoals Moz Pro, Link Explorer, of Screaming Frog om een Site crawl draaien. Vergelijk vervolgens het aantal pagina ’s dat de crawl heeft weergegeven met het aantal pagina’ s dat wordt weergegeven wanneer u een site uitvoert:zoeken op Google.
Rel= “nofollow” kan met de volgende syntaxis worden gebruikt:
< pre><a href=” / “rel=” nofollow “>nofollow deze link</a></pre>
in dit Voorbeeld, door het rel="nofollow" attribuut toe te voegen aan de link tag, vertelt de webmaster de zoekmachines dat ze niet willen dat deze link wordt geïnterpreteerd als een normale, juice passing, ” redactionele stemming.”Nofollow kwam tot stand als een methode om te helpen stoppen geautomatiseerde blog commentaar, gastenboek, en link injectie spam, maar is veranderd in de loop van de tijd in een manier van het vertellen van de motoren om elke link waarde die normaal zou worden doorgegeven korting. Links met nofollow worden door elk van de motoren iets anders geïnterpreteerd.
blijf leren
- ankertekst
- Link Equity
- Webmaster Guidelines Google ‘ s Official Guidelines for Webmasters.
- tekstlinks en PageRank voormalig hoofd van het Webspam Team bij Google, Matt Cutts’, gedachten over hyperlinks in relatie tot SEO en Google.