Non-uniform memory access (NUMA) is een gedeelde geheugenarchitectuur die wordt gebruikt in de hedendaagse multiprocessing systemen. Elke CPU krijgt zijn eigen lokaal geheugen toegewezen en heeft toegang tot het geheugen van andere CPU ‘ s in het systeem. Lokale geheugentoegang biedt een lage latency – hoge bandbreedte prestaties. Terwijl de toegang tot het geheugen van de andere CPU heeft een hogere latency en lagere bandbreedte prestaties. Moderne toepassingen en besturingssystemen zoals ESXi ondersteunen standaard NUMA, maar om de beste prestaties te bieden, moet de virtuele machineconfiguratie worden gedaan met de NUMA-architectuur in het achterhoofd. Indien onjuist ontworpen, inconsequent gedrag of algehele prestatievermindering optreedt voor die specifieke virtuele machine of in het ergste geval voor alle VM ‘ s die op die ESXi-host draaien.
deze serie heeft tot doel inzicht te verschaffen in de CPU-architectuur, het geheugensubsysteem en de ESXi CPU en geheugenplanner. Zodat u in het creëren van een hoog presterende platform dat de basis legt voor de hogere diensten en verhoogde consoliderende ratio ‘ s. Voordat we tot moderne computerarchitecturen komen, is het handig om de geschiedenis van multiprocessorarchitecturen met gedeeld geheugen te bekijken om te begrijpen waarom we vandaag de dag NUMA-systemen gebruiken.
- de evolutie van multiprocessors voor gedeeld geheugen in de laatste decennia
- introductie van caching Snoop protocollen
- Uniform Memory Access Architecture
- niet-uniforme Geheugentoegangsarchitectuur
- 1: niet-uniforme Geheugentoegangorganisatie
- 2: Point-to-Point verbinding
- 3: schaalbare Cachecoherentie
- non-interleaved enabled NUMA = SUMA
- Nehalem & Core microarchitecture overview
de evolutie van multiprocessors voor gedeeld geheugen in de laatste decennia
het lijkt erop dat een architectuur genaamd Uniform Memory Access beter zou passen bij het ontwerpen van een consistent platform met lage latentie en hoge bandbreedte. Maar moderne systeemarchitecturen zullen het onmogelijk maken om echt uniform te zijn. Om de reden hierachter te begrijpen moeten we terug in de geschiedenis om de belangrijkste drivers van parallel computing te identificeren.
met de introductie van relationele databases in het begin van de jaren zeventig werd de behoefte aan systemen die meerdere gelijktijdige gebruikersactiviteiten konden bedienen en overmatige gegevensgeneratie mainstream. Ondanks de indrukwekkende prestaties van uniprocessor waren multiprocessorsystemen beter uitgerust om deze werkdruk aan te kunnen. Om een kosteneffectief systeem te bieden, werd gedeelde geheugenadresseruimte de focus van het onderzoek. In het begin werden systemen met behulp van een dwarsbalk switch aanbevolen, maar met deze ontwerpcomplexiteit geschaald samen met de toename van processors, waardoor het bus-gebaseerde systeem aantrekkelijker werd. Processors in een bussysteem hebben toegang tot de volledige geheugenruimte door aanvragen op de bus te sturen, een zeer kosteneffectieve manier om het beschikbare geheugen zo optimaal mogelijk te gebruiken.
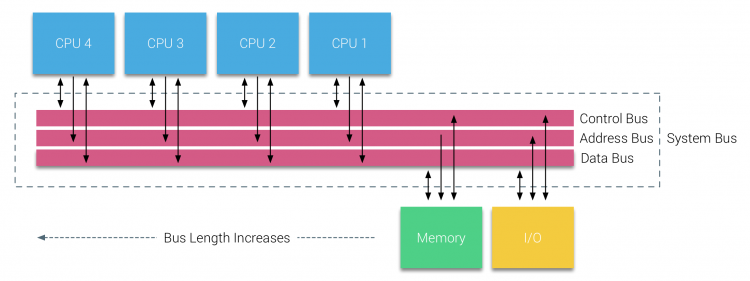
busgebaseerde systemen hebben echter hun eigen schaalbaarheidsproblemen. Het belangrijkste probleem is de beperkte hoeveelheid bandbreedte, dit beperkt het aantal processors de bus kan huisvesten. Het toevoegen van CPU ‘ s aan het systeem introduceert twee belangrijke gebieden van zorg:
- de beschikbare bandbreedte per knooppunt neemt af naarmate elke CPU wordt toegevoegd.
- de buslengte neemt toe bij het toevoegen van meer processoren, waardoor de latentie toeneemt.
de groei van de prestaties van de CPU en in het bijzonder de snelheidskloof tussen de processor en de geheugenprestaties was, en is nog steeds, verwoestend voor multiprocessors. Aangezien de geheugenkloof tussen processor en geheugen naar verwachting zal toenemen, is er veel moeite gedaan om effectieve strategieën te ontwikkelen om de geheugensystemen te beheren. Een van deze strategieën was het toevoegen van geheugen cache, die een veelheid van uitdagingen geïntroduceerd. Het oplossen van deze uitdagingen is nog steeds de belangrijkste focus van vandaag voor CPU design teams, veel onderzoek wordt gedaan op caching structuren en geavanceerde algoritmen om cache misses te voorkomen.
introductie van caching Snoop protocollen
het koppelen van een cache aan elke CPU verhoogt de prestaties op vele manieren. Door het geheugen dichter bij de CPU te brengen, wordt de gemiddelde toegangstijd van het geheugen verkort en wordt tegelijkertijd de bandbreedtebelasting op de geheugenbus verminderd. De uitdaging met het toevoegen van cache aan elke CPU in een gedeelde geheugenarchitectuur is dat het mogelijk maakt meerdere kopieën van een geheugenblok te bestaan. Dit heet het cachecoherentieprobleem. Om dit op te lossen, werden caching snoop protocollen uitgevonden die probeerden een model te maken dat de juiste gegevens verschafte, terwijl het niet probeerde om alle bandbreedte op de bus op te eten. Het meest populaire protocol, write invalidate, wist alle andere kopieën van gegevens voordat het schrijven van de lokale cache. Elke volgende lezing van deze gegevens door andere processors zal een cache missen detecteren in hun lokale cache en zal worden onderhouden vanuit de cache van een andere CPU met de meest recent gewijzigde gegevens. Dit model bespaarde veel bandbreedte van de bus en liet uniforme toegangssystemen toe om in de vroege jaren 1990 te ontstaan. moderne cachecoherentieprotocollen worden in meer detail behandeld door deel 3.
Uniform Memory Access Architecture
Processors van op Bus gebaseerde multiprocessors die dezelfde – uniform – access tijd hebben tot een geheugenmodule in het systeem worden vaak aangeduid als Uniform Memory Access (UMA) systemen of symmetrische multiprocessors (SMPs).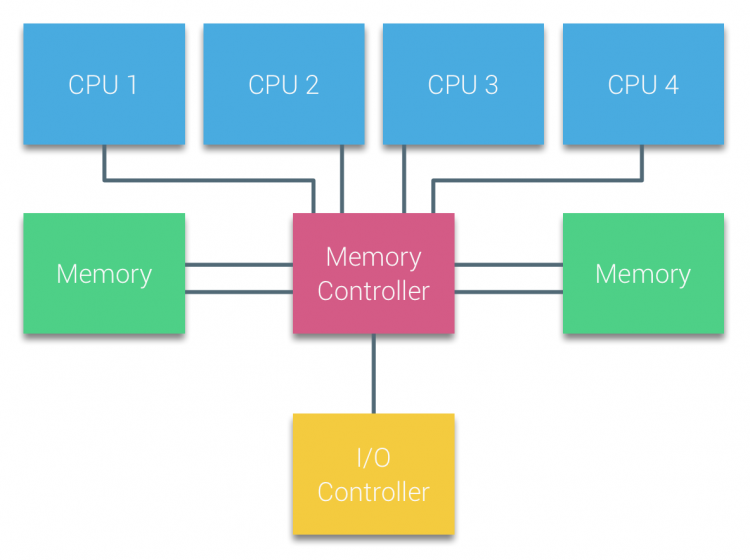
bij UMA systemen zijn de CPU ‘ s via een systeembus (Front-Side Bus) verbonden met de Northbridge. De Northbridge bevat de geheugencontroller en alle communicatie van en naar het geheugen moet via de Northbridge gaan. De I / O controller, die verantwoordelijk is voor het beheren van I/O op alle apparaten, is aangesloten op de Northbridge. Daarom moet elke I / O via de Northbridge naar de CPU.
meerdere bussen en geheugenkanalen worden gebruikt om de beschikbare bandbreedte te verdubbelen en het knelpunt van de Northbridge te verkleinen. Om de geheugenbandbreedte nog verder te verhogen, hebben sommige systemen externe geheugencontrollers aangesloten op de Northbridge, waardoor de bandbreedte en ondersteuning van meer geheugen worden verbeterd. Vanwege de interne bandbreedte van de Northbridge en de broadcasting aard van de vroege snoopy cache protocollen, UMA werd beschouwd als een beperkte schaalbaarheid. Met het huidige gebruik van high-speed flash-apparaten, het duwen van honderdduizenden IO ‘ s per seconde, ze hadden absoluut gelijk dat deze architectuur niet zou schaal voor toekomstige workloads.
niet-uniforme Geheugentoegangsarchitectuur
om de schaalbaarheid en prestaties te verbeteren worden drie belangrijke wijzigingen aangebracht in de multiprocessors-architectuur met gedeeld geheugen;
- niet-uniforme organisatie voor geheugentoegang
- Point-to-Point interconnect topologie
- schaalbare cachecoherentieoplossingen
1: niet-uniforme Geheugentoegangorganisatie
NUMA verlaat een gecentraliseerde geheugenpool en introduceert topologische eigenschappen. Door het classificeren van geheugenlocatiebasissen op signaalweglengte van de processor naar het geheugen, kunnen latency en bandbreedteknelpunten worden vermeden. Dit wordt gedaan door het hele systeem van processor en chipset opnieuw te ontwerpen. NUMA architecturen kreeg populariteit aan het einde van de jaren 90 toen het werd gebruikt op SGI supercomputers zoals de Cray Origin 2000. NUMA hielp om de locatie van het geheugen te identificeren, in dit geval van deze Systemen, moesten ze zich afvragen welk geheugengebied waarin het chassis de geheugenbits hield.In de eerste helft van het millenniumdecennium bracht AMD NUMA naar het ondernemingslandschap waar UMA systems de overhand kreeg. In 2003 werd de AMD Opteron-familie geïntroduceerd, met geïntegreerde geheugencontrollers waarbij elke CPU geheugenbanken bezit. Elke CPU heeft nu zijn eigen geheugenadresruimte. Een NUMA geoptimaliseerd besturingssysteem, zoals ESXi, maakt het mogelijk om geheugen te verbruiken vanuit beide geheugenadressen spaties terwijl het optimaliseren voor lokale geheugentoegang. Laten we een voorbeeld van een twee CPU-systeem gebruiken om het onderscheid tussen lokale en externe geheugentoegang binnen een enkel systeem te verduidelijken.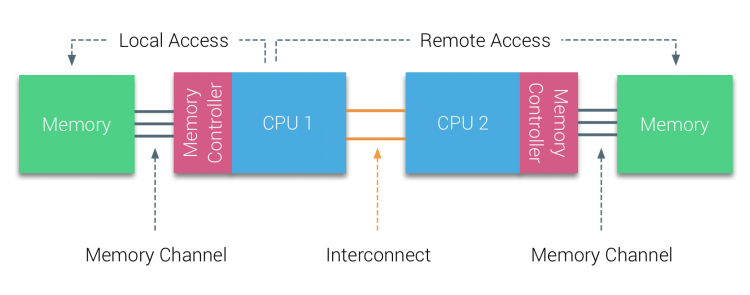
het geheugen dat is aangesloten op de geheugencontroller van de CPU1 wordt beschouwd als lokaal geheugen. Geheugen aangesloten op een andere cpu socket (CPU2) wordt beschouwd als buitenlands of remote voor CPU1. Remote memory access heeft extra latency overhead voor lokale geheugentoegang, omdat het een interconnect (point-to-point link) moet doorlopen en verbinding moet maken met de remote memory controller. Als gevolg van de verschillende geheugenlocaties, dit systeem ervaart “niet-uniforme” toegang tot het geheugen tijd.
2: Point-to-Point verbinding
AMD introduceerde hun point-to-point verbinding HyperTransport met de AMD Opteron microarchitectuur. Intel verliet hun dual independent bus architectuur in 2007 door de introductie van de QuickPath architectuur in hun Nehalem Processor familie ontwerp.De Nehalem-architectuur was een belangrijke ontwerpwijziging binnen de Intel-microarchitectuur en wordt beschouwd als de eerste echte generatie van de Intel Core-serie. De huidige Broadwell architectuur is de 4e generatie van de Intel Core merk (Intel Xeon E5 v4), de laatste paragraaf bevat meer informatie over de microarchitectuur generaties. Binnen de QuickPath architectuur, de geheugen controllers verplaatst naar de CPU en introduceerde de QuickPath point-to-point Interconnect (QPI) als data-links tussen CPU ‘ s in het systeem.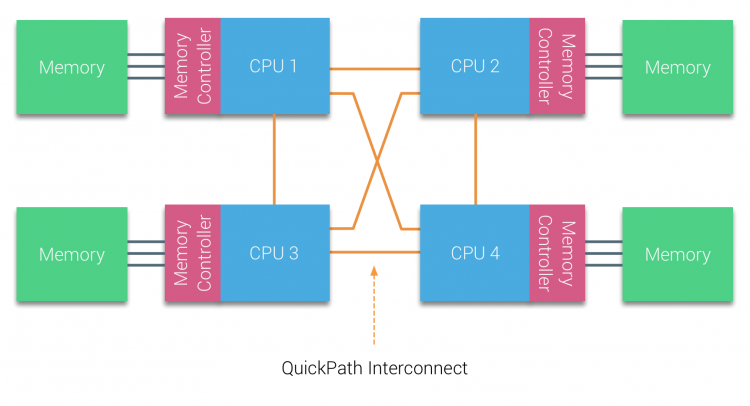
de Nehalem microarchitectuur verving niet alleen de oude front-side bus, maar reorganiseerde het hele subsysteem tot een modulair ontwerp voor server CPU. Dit modulaire ontwerp werd geïntroduceerd als de “Uncore” en creëert een bouwstenen bibliotheek voor caching en interconnect snelheden. Het verwijderen van de front-side bus verbetert de bandbreedte schaalbaarheid problemen, maar intra – en inter-processor communicatie moeten worden opgelost bij het omgaan met enorme hoeveelheden geheugencapaciteit en bandbreedte. Zowel de geïntegreerde geheugencontroller als de QuickPath Interconnects maken deel uit van de Uncore en zijn modelspecifieke Registers (MSR). Ze maken verbinding met een MSR die de intra – en interprocessorcommunicatie biedt. De modulariteit van de Uncore maakt het ook mogelijk dat Intel verschillende QPI-snelheden biedt, op het moment van schrijven biedt de Intel Broadwell-EP microarchitecture (2016) 6,4 Giga-transfers per seconde (GT/s), 8.0 GT/s en 9.6 GT/s. respectievelijk een theoretische maximale bandbreedte van 25.6 GB/s, 32 GB/s en 38.4 GB/s tussen de CPU ‘ s. Om dit in perspectief te plaatsen, de laatst gebruikte front-side bus voorzien van 1.6 GT / s of 12.8 GB / s platform bandbreedte. Bij de introductie van Sandy Bridge Intel omgedoopt Uncore in System Agent, maar de term Uncore wordt nog steeds gebruikt in de huidige documentatie. Meer over QuickPath en de Uncore vind je in deel 2.
3: schaalbare Cachecoherentie
elke core had een eigen pad naar de L3 cache. Elk pad bestond uit Duizend draden en je kunt je voorstellen dat dit niet goed schaalt als je het productieproces van de nanometer wilt verlagen terwijl je ook de kernen wilt verhogen die toegang willen krijgen tot de cache. Om te kunnen schalen, de Sandy Bridge architectuur verplaatste de L3 cache uit de Uncore en introduceerde de schaalbare ring on-die Interconnect. Hierdoor kon Intel de L3 cache partitioneren en distribueren in gelijke slices. Dit zorgt voor een hogere bandbreedte en associativiteit. Elke slice is 2,5 MB en een slice wordt geassocieerd met elke kern. De ring maakt het mogelijk elke kern om toegang te krijgen tot elke andere schijf ook. Hieronder afgebeeld is de die configuratie van een Low Core Count (LCC) Xeon CPU van de Broadwell Microarchitecture (v4) (2016).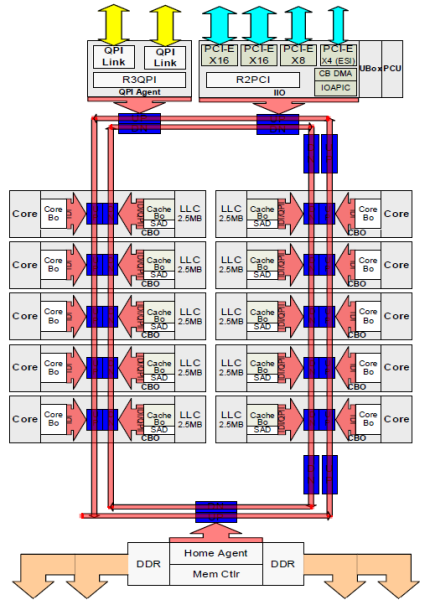
deze cachingarchitectuur vereist een snooping-protocol dat zowel gedistribueerde lokale cache als de andere processors in het systeem bevat om cachecoherentie te garanderen. Met de toevoeging van meer kernen in het systeem, de hoeveelheid snoop verkeer groeit, omdat elke kern heeft zijn eigen gestage stroom van cache misses. Dit beà nvloedt het verbruik van de QPI links en laatste niveau caches, die voortdurende ontwikkeling in Snoop cohesieprotocollen vereisen. Een diepgaand overzicht van de Oncore, schaalbare Ring On-Die Interconnect en het belang van caching snoop protocollen op NUMA performance zal worden opgenomen in deel 3.
non-interleaved enabled NUMA = SUMA
fysiek geheugen is verdeeld over het moederbord, maar het systeem kan één geheugenadresruimte bieden door het geheugen tussen de twee NUMA-knooppunten te interleaven. Dit heet knooppunt-interleaving (instelling wordt behandeld in deel 2). Wanneer knooppunt interleaving is ingeschakeld, wordt het systeem een voldoende uniforme geheugenarchitectuur (SUMA). In plaats van het doorgeven van de topologie info en de aard van de processors en het geheugen in het systeem aan het besturingssysteem, het systeem breekt het gehele geheugenbereik in 4KB adresseerbare regio ‘ s en kaarten ze in een round robin manier van elk knooppunt. Dit zorgt voor een’ interleaved ‘ geheugenstructuur waarbij de geheugenadresruimte over de knooppunten wordt verdeeld. Wanneer ESXi geheugen toewijst aan een virtuele machine wijst het fysiek geheugen toe dat zich bevindt op twee verschillende knooppunten wanneer de fysieke CPU in knooppunt 0 het geheugen moet ophalen van knooppunt 1, zal het geheugen de QPI-koppelingen doorlopen.
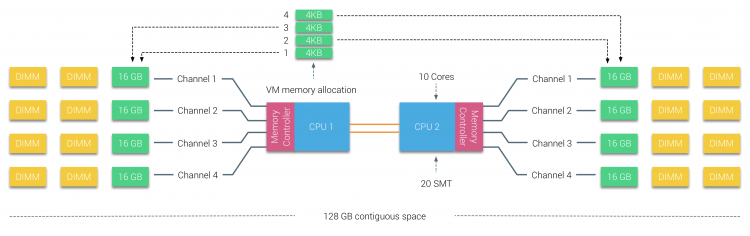
interessant is dat het SUMA-systeem een uniforme toegangstijd voor het geheugen biedt. Alleen niet de meest optimale en sterk afhankelijk van contention levels in de QPI architectuur. Intel Memory Latency Checker werd gebruikt om de verschillen tussen NUMA en SUMA configuratie op hetzelfde systeem aan te tonen.
deze test meet de inactieve latenties (in nanoseconden) van elke socket naar de andere socket in het systeem. De latentie gemeld van Geheugenknooppunt 0 Door Socket 0 is lokale geheugentoegang, geheugentoegang van socket 0 van geheugenknooppunt 1 is externe geheugentoegang in het systeem geconfigureerd als NUMA.
| NUMA | Geheugen Node 0 | Geheugen Knooppunt 1 | – | SUMA | Geheugen Node 0 | Geheugen Knooppunt 1 |
| Aansluiting 0 | 75.7 | 132.0 | – | Socket 0 | 105.5 | 106.4 |
| Socket 1 | 131.9 | 75.8 | – | Socket 1 | 106.0 | 104.6 |
zoals verwacht wordt interleaving beïnvloed door het constant doorlopen van de QPI-koppelingen. De inactieve geheugentest is het beste scenario, een interessantere test is het meten van geladen latenties. Het zou een slechte investering zijn geweest als uw ESXi servers stationair draaien, daarom kunt u ervan uitgaan dat een ESXi systeem gegevens verwerkt. Het meten van geladen latencies geeft een beter inzicht in hoe het systeem zal presteren onder normale belasting. Tijdens de test worden de laadinjectievertragingen om de 2 seconden automatisch gewijzigd en wordt zowel de bandbreedte als de bijbehorende latentie op dat niveau gemeten. Deze test gebruikt 100% leesverkeer.NUMA testresultaten aan de linkerkant, SUMA testresultaten aan de rechterkant.
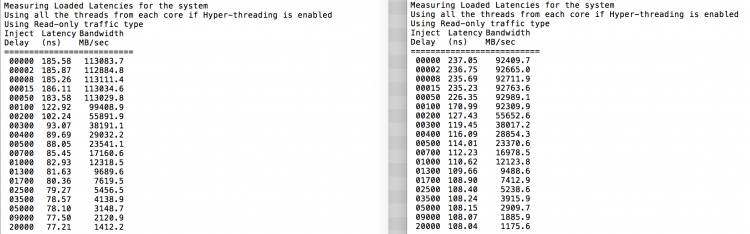
de gerapporteerde bandbreedte voor het SUMA-systeem is lager met behoud van een hogere latency dan het systeem geconfigureerd als NUMA. Daarom moet de focus liggen op het optimaliseren van de VM-grootte om de NUMA-kenmerken van het systeem te benutten.
Nehalem & Core microarchitecture overview
met de introductie van de Nehalem microarchitectuur in 2008, verliet Intel de NetBurst-architectuur. De Nehalem microarchitectuur introduceerde Intel klanten bij NUMA. In de loop der jaren introduceerde Intel nieuwe microarchitecturen en optimalisaties, volgens zijn beroemde Tick-Tock model. Bij elke tik vindt optimalisatie plaats, krimpt de procestechnologie en bij elke tak wordt een nieuwe microarchitectuur geïntroduceerd. Hoewel Intel biedt een consistente branding model sinds 2012, mensen de neiging om Intel architectuur codenamen om de CPU tick en tock generaties te bespreken. Zelfs de EVC baselines geeft deze interne Intel codenamen, zowel branding namen en architectuur codenamen zullen worden gebruikt in deze serie:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDDR3-2133 | Tock | 22nm |
| Broadwell | E5-26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4xDDR3-2400 | Vink | 14 nm |
Tot de volgende, Deel 2: de Systeem Architectuur
2016, NUMA Diepe Duik Serie:
Deel 0: Inleiding NUMA Deep Dive Series
Deel 1: Van A tot NUMA
Deel 2: de Systeem Architectuur
Deel 3: Cache Coherentie
Deel 4: Lokale Geheugen Optimalisatie
Deel 5: ESXi VMkernel NUMA Construeert