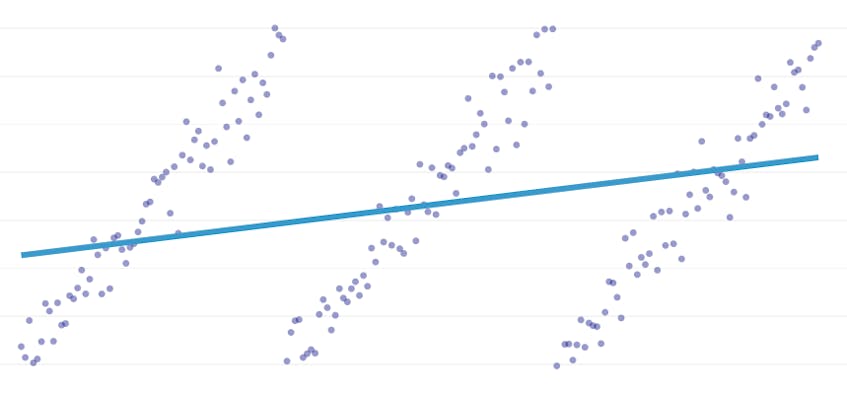
stuksgewijze regressie is een speciaal type lineaire regressie dat ontstaat wanneer een enkele lijn niet voldoende is om een dataset te modelleren. Stuksgewijze regressie breekt het domein in potentieel veel” segmenten ” en past een aparte lijn door elk. Bijvoorbeeld, in de grafieken hieronder, is een enkele regel niet in staat om de gegevens te modelleren evenals een stuksgewijze regressie met drie regels:
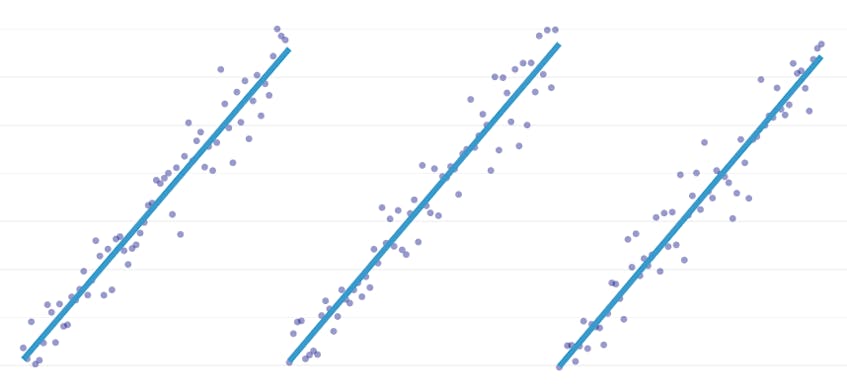
dit bericht presenteert Datadog ‘ s benadering van het automatiseren stuksgewijze regressie op tijdreeksgegevens.
doelstellingen
stuksgewijze regressie kan iets verschillende dingen betekenen in verschillende contexten, dus laten we een minuut nemen om duidelijk te maken wat we precies proberen te bereiken met ons stuksgewijze regressie algoritme.
geautomatiseerde breekpuntdetectie. In de klassieke statistiekliteratuur wordt stuksgewijze regressie vaak voorgesteld tijdens handmatige regressieanalyse, waarbij het voor het blote oog duidelijk is dat de ene lineaire trend plaats maakt voor de andere. In dat geval kan een mens het breekpunt tussen stuksgewijze segmenten specificeren, de dataset splitsen en een lineaire regressie op elk segment onafhankelijk uitvoeren. In onze use cases willen we honderden regressies per seconde doen, en het is niet haalbaar om een mens alle breekpunten te laten specificeren. In plaats daarvan hebben we de eis dat ons stuksgewijze regressiealgoritme zijn eigen breekpunten identificeert.
geautomatiseerde detectie van segmenttelling. Als we zouden weten dat een dataset precies twee segmenten heeft, zouden we gemakkelijk naar elk van de mogelijke segmenten-paren kunnen kijken. Echter, in de praktijk, wanneer gegeven een willekeurige tijdreeks, is er geen reden om te geloven dat er meer dan één segment of minder dan 3 of 4 of 5 moet zijn. Ons algoritme moet een passend aantal segmenten kiezen zonder dat het door de gebruiker wordt gespecificeerd.
geen continuïteitsvereiste. Sommige methoden voor stuksgewijze regressies genereren verbonden segmenten, waarbij het eindpunt van elk segment het beginpunt van het volgende segment is. We leggen een dergelijke eis niet op aan ons algoritme.
uitdagingen
de meest voor de hand liggende uitdaging voor het implementeren van een stuksgewijze regressie met geautomatiseerde breekpuntdetectie is de grote omvang van de oplossingszoekruimte; een brute-force zoekopdracht van alle mogelijke segmenten is onbetaalbaar. Het aantal manieren waarop een tijdreeks kan worden opgesplitst in segmenten is exponentieel in de lengte van de tijdreeks. Hoewel dynamisch programmeren veel efficiënter kan worden gebruikt om deze zoekruimte te doorkruisen dan een naïeve brute-force implementatie, is het in de praktijk nog steeds te traag. Een hebzuchtige heurist zal nodig zijn om snel grote delen van de zoekruimte te verwijderen.
een subtielere uitdaging is dat we een manier nodig hebben om de kwaliteit van de ene oplossing met de andere te vergelijken. Voor onze versie van het probleem, met onbekende nummers en locaties van segmenten, moeten we potentiële oplossingen vergelijken met verschillende nummers van segmenten en verschillende breekpunten. We proberen twee concurrerende doelen in evenwicht te brengen:
- minimaliseer de fouten. Dat wil zeggen, maak de regressielijn van elk segment dicht bij de waargenomen gegevenspunten.
- gebruik het minste aantal segmenten dat de gegevens goed modelleert. We kunnen altijd nul fout te krijgen door het creëren van een enkel segment voor elk punt (of zelfs een segment voor elke twee punten). Toch zou dat het hele punt van het doen van een regressie verslaan; we zouden niets leren over de algemene relatie tussen een tijdstempel en de bijbehorende metrische waarde, en we konden het resultaat niet gemakkelijk gebruiken voor interpolatie of extrapolatie.
onze oplossing
we gebruiken het volgende inhalige algoritme voor het stuksgewijze regressieprobleem:
- doe een stuksgewijze regressie met n / 2 segmenten, waarbij n het aantal waarnemingen in de tijdreeks is. De regressielijn in elk segment is geschikt met behulp van gewone OLS-regressie (least squares). Deze eerste stuksgewijze regressie zal nauwelijks een fout hebben, maar het zal ernstig over de dataset gaan.
- iteratief, totdat er slechts één segment is:
- voor alle paren van naburige segmenten, evalueer de toename van de totale fout die zou resulteren als de twee segmenten werden gecombineerd, waarbij de twee regressielijnen worden vervangen door één regressielijnen.
- voeg het paar segmenten samen dat zou resulteren in de kleinste toename van fouten.
- als het uitvoeren van deze samenvoeging voldoet aan onze stopcriteria (hieronder gedefinieerd), dan zijn we misschien te ver gegaan door twee segmenten samen te voegen die gescheiden zouden moeten blijven. Als dit het geval is, onthoud dan de toestand van de segmenten van voor de samenvoeging van deze iteratie.
- als geen samenvoeging resulteerde in het onthouden van de toestand van segmenten in (2c) hierboven, dan is de beste oplossing een groot segment. Anders is de laatste segmentstatus die moet worden onthouden in (2c) de beste oplossing.
Stopcriteria
we beschouwen een samenvoeging als een potentieel stoppunt als het de totale som van kwadraatfouten met meer verhoogt dan een eerdere samenvoeging. Om te voorkomen dat er te vroeg wordt gestopt in gevallen waarin er maar één segment zou moeten zijn, zullen we een samenvoeging niet beschouwen als een potentiële stoppunt tenzij het resulteert in een toename van de totale fout die minder is dan 3% van de totale fout van een regressie met één segment. (De 3% is een willekeurige drempel, maar we hebben geconstateerd dat het in de praktijk goed werkt.) Hieronder zijn een paar voorbeelden om aan te tonen waarom dit stoppen criteria werkt.
laten we eerst eens kijken naar een dataset die werd gegenereerd door normaal gedistribueerde ruis toe te voegen aan punten langs een enkele lijn. Het algoritme past correct slechts één segment door deze dataset.
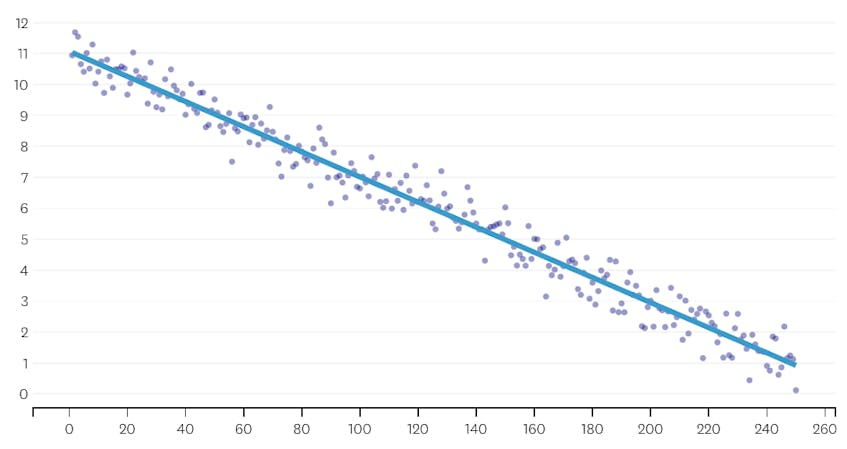
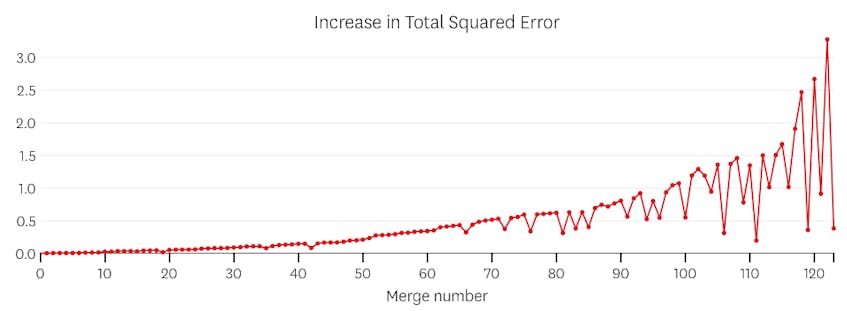
in dit geval, geen samenvoeging ooit verhoogt de totale som van kwadraat fouten met meer dan 3%. Daarom wordt geen merge beschouwd als een adequaat stoppunt, en we gebruiken de uiteindelijke status nadat alle merges zijn uitgevoerd. In de plot hieronder zien we dat latere samenvoegingen de neiging hebben om meer fouten in te voeren dan eerdere (wat logisch is omdat ze elk meer punten beïnvloeden), maar de toename van fouten neemt alleen geleidelijk toe naarmate meer segmenten worden samengevoegd.
ten tweede, laten we eens kijken naar een voorbeeld waar er zeven verschillende segment in de dataset.
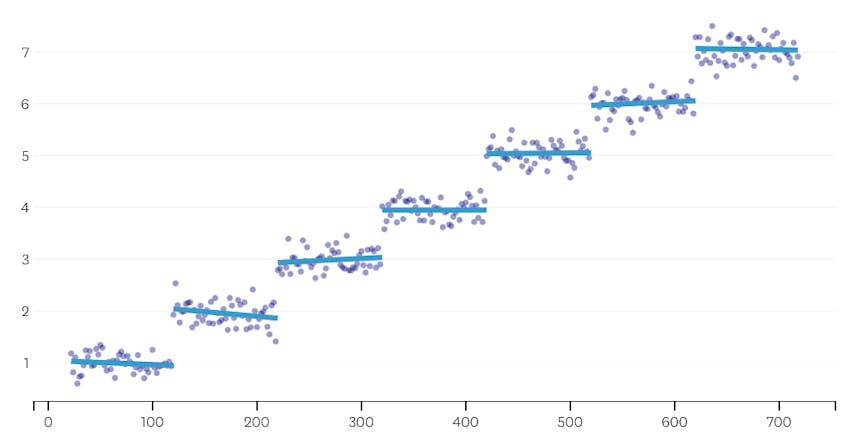
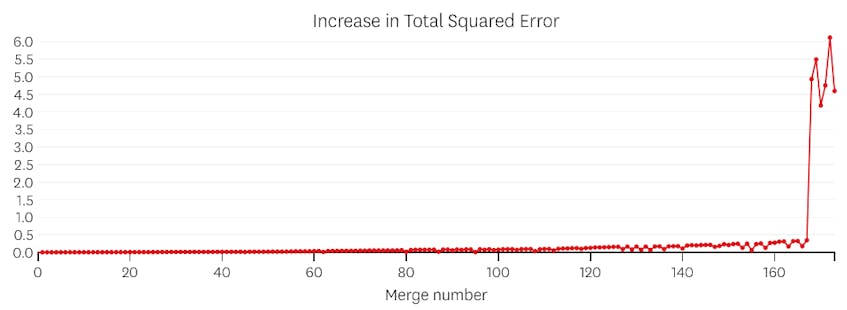
in dit geval, als we kijken naar de plot van fouten geïntroduceerd door elke merge, zien we dat de laatste zes merges introduceerde veel meer fouten dan een van de vorige merges. Daarom herinnerde ons algoritme de toestand van de segmenten van voor de 6e-tot-laatste samenvoeging en gebruikte dat als de uiteindelijke oplossing.
de code
In de Datadog / stukswise GitHub repo, vindt u onze Python implementatie van het algoritme. De functie piecewise() is de plaats waar het zwaar tillen plaatsvindt; gegeven een reeks gegevens geeft deze de locatie-en regressiecoëfficiënten voor elk van de gemonteerde segmenten terug.
ook opgenomen in de gist is plot_data_with_regression() — een wrapper functie voor snel en eenvoudig plotten. Een snel voorbeeld van hoe dit kan worden gebruikt:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)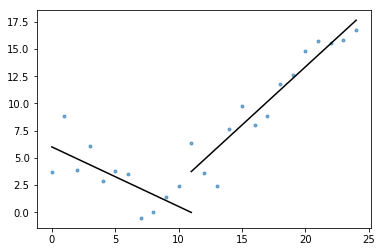
hoewel bij deze implementatie gebruik wordt gemaakt van OLS lineaire regressie, kan hetzelfde kader worden aangepast om gerelateerde problemen op te lossen. Door kwadraat fout te vervangen door absolute fout of Huber verlies, kan de regressie robuust worden gemaakt. Of een step-functie kan worden aangepast door elk segment een constante waarde toe te kennen die gelijk is aan het gemiddelde van de waarnemingen in zijn domein.