Hidden Markov Model (HMM) is een statistisch Markov model waarin wordt aangenomen dat het systeem dat gemodelleerd wordt een Markov-proces is met niet-geobserveerde (d.w.z. verborgen) toestanden.Verborgen Markov-modellen zijn vooral bekend om hun toepassing in versterkingsleer en temporele patroonherkenning, zoals spraak, handschrift, gebarenherkenning, labeling van delen van spraak, volgen van muziekpartituren, gedeeltelijke ontladingen en bio-informatica.
terminologie in HMM
verwijst de term verborgen naar het eerste Markov-proces achter de waarneming. Observatie verwijst naar de gegevens die we kennen en kunnen waarnemen. Markov proces wordt getoond door de interactie tussen” regenachtig “en” zonnig ” in het onderstaande diagram en elk van deze zijn verborgen toestanden.

waarnemingen zijn bekende gegevens en verwijst naar” lopen”,” Shop”, en” schoon ” in het bovenstaande diagram. In machine learning zin, observatie is onze trainingsgegevens, en het aantal verborgen toestanden is onze hyper parameter voor ons model. De evaluatie van het model zal later worden besproken.

T = nog geen waarneming, N = 2, M = 3, Q = {“Rainy”, “Sunny”}, V = {“Walk”, “Shop”, “Clean”}
kans op Toestandstransitie zijn de pijlen die naar elke verborgen toestand wijzen. Observatie waarschijnlijkheidsmatrix zijn de blauwe en rode pijlen die naar elke waarneming van elke verborgen toestand wijzen. De matrix zijn Rij stochastisch wat betekent dat de rijen optellen tot 1.


De matrix legt uit wat de waarschijnlijkheid is van plan om de ene staat naar de andere, of gaat van de ene toestand naar een observatie.
initiële statusdistributie laat het model starten door te beginnen met een verborgen status.
volledig model met bekende toestandstransitie waarschijnlijkheden, observatie waarschijnlijkheidsmatrix en initiële toestandsverdeling is gemarkeerd als,
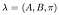
Hoe kunnen we het bovenstaande model in Python bouwen?
in het bovenstaande geval zijn emissies discreet {“Walk”, “Shop”,”Clean”}. MultinomialHMM uit de hmmlearn-bibliotheek wordt gebruikt voor het bovenstaande model. GaussianHMM en GMMHMM zijn andere modellen in de bibliotheek.
nu met de HMM wat zijn enkele belangrijke problemen op te lossen?
- Probleem 1, gegeven een bekend model wat is de waarschijnlijkheid van sequentie O?
- Probleem 2, gegeven een bekend model en een reeks O, Wat is de optimale verborgen toestandsreeks? Dit zal nuttig zijn als we willen weten of het weer “regenachtig” of “zonnig”
- Probleem 3, gegeven volgorde O en aantal verborgen toestanden, Wat is het optimale model dat de kans op O maximaliseert?
Probleem 1 in Python
de waarschijnlijkheid dat de eerste waarneming “lopen” is, is gelijk aan de vermenigvuldiging van de initiële toestandsverdeling en emissiewaarschijnlijkheidsmatrix. 0,6 x 0,1 + 0,4 x 0,6 = 0,30 (30%). De log waarschijnlijkheid wordt geleverd door te bellen .scoren.
Probleem 2 in Python

gezien het bekende model en de observatie {“Shop”, “Clean”, “Walk”}, was het weer zeer waarschijnlijk {“Rainy”, “Rainy”, “Sunny”} met ~1,5% waarschijnlijkheid.
gezien het bekende model en de waarneming {“Clean”, “Clean”, “Clean”}, was het weer zeer waarschijnlijk {“Rainy”, “Rainy”, “Rainy”} met een waarschijnlijkheid van ~3,6%.
Intuã tief, wanneer “lopen” optreedt, zal het weer hoogstwaarschijnlijk niet “regenachtig”zijn.
Probleem 3 in Python
spraakherkenning met audiobestand: voorspel deze woorden

Amplitude kan worden gebruikt als observatie voor HMM, maar feature engineering zal ons meer prestaties geven.

functie stft en peakfind genereert functie voor audiosignaal.
het voorbeeld hierboven is hier genomen. Kyle Kastner gebouwd HMM klasse die neemt in 3d arrays, Ik gebruik hmmlearn die alleen 2d arrays toestaat. Dit is de reden waarom ik ben het verminderen van de functies die door Kyle Kastner als X_test.gemiddelde (as = 2).
het doorlopen van deze modellering kostte veel tijd om het te begrijpen. Ik had de indruk dat de doelvariabele de observatie moest zijn. Dit geldt voor tijdreeksen. Classificatie wordt gedaan door het bouwen van HMM voor elke klasse en vergelijk de output door het berekenen van de logprob voor uw invoer.
wiskundige oplossing voor Probleem 1: Forward algoritme

Alpha pass is de waarschijnlijkheid van waarneming en TOESTANDSSEQUENTIE gegeven model.
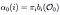
Alpha pass op tijd ( t) = 0, initiële toestandsverdeling naar i en van daaruit naar eerste waarneming O0.
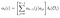
Alfapas op tijdstip (t) = t, som van de laatste alfapas voor elke verborgen toestand vermenigvuldigd met de emissie naar Ot.
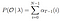
wiskundige oplossing voor probleem 2: Backward Algoritme


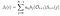

Gegeven model en waarneming, kans op staat qi op tijdstip t.
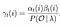
Wiskundige Oplossing voor Probleem 3: Forward-Backward Algoritme


de Waarschijnlijkheid van state qi qj op tijdstip t met het gegeven model en waarneming
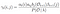
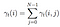
Som van alle overgang waarschijnlijkheid van i naar j.
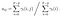
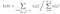
Overgang en emissie kans matrix zijn geschat met di-gamma.
herhalen als de waarschijnlijkheid voor P (O|model) toenames