Non-uniform memory access (NUMA) is a shared memory architecture used in today’s multiprocessing systems. Cada CPU é atribuída sua própria memória local e pode acessar a memória de outros CPUs no sistema. O acesso à memória local oferece um desempenho de baixa latência-alta largura de banda. Enquanto acessar a memória de propriedade da outra CPU tem maior latência e menor desempenho de largura de banda. Aplicações modernas e sistemas operacionais, como o Suporte ESXi NUMA por padrão, mas para fornecer o melhor desempenho, a configuração da máquina virtual deve ser feita com a arquitetura NUMA em mente. Se o comportamento incorreto projetado, inconsequente ou degradação geral do desempenho ocorrer para essa máquina virtual em particular ou, na pior das hipóteses, para todos os VMs que rodam nesse host ESXi.
esta série tem como objetivo fornecer insights sobre a arquitetura da CPU, o subsistema de memória e a CPU ESXi e scheduler de memória. Permitindo-lhe criar uma plataforma de alto desempenho que estabelece as bases para os serviços mais elevados e maiores rácios de consolidação. Antes de chegarmos às arquiteturas modernas de computação, é útil rever a história das arquiteturas multiprocessadoras de memória compartilhada para entender por que estamos usando sistemas NUMA hoje.
- A evolução de memória compartilhada multiprocessadores arquitetura nas últimas décadas
- introdução de protocolos de cache snoop
- Arquitetura uniforme de acesso à memória
- Arquitectura de acesso à memória não uniforme
- 1: organização não uniforme de acesso à memória
- 2: interconexão ponto-a-ponto
- 3: coerência de Cache escalável
- numa = SUMA
A evolução de memória compartilhada multiprocessadores arquitetura nas últimas décadas
parece que uma arquitetura chamada de Acesso Uniforme à Memória seria um melhor ajuste ao projetar um consistente com baixa latência e alta largura de banda da plataforma. No entanto, arquitecturas modernas de sistemas irão restringi-lo de ser verdadeiramente uniforme. Para entender a razão por trás disso, precisamos voltar na história para identificar os principais drivers da computação paralela.
com a introdução de bases de dados relacionais no início da década de 70, a necessidade de sistemas que pudessem servir múltiplas operações simultâneas de usuários e geração excessiva de dados tornou-se Corrente. Apesar da impressionante taxa de desempenho do uniprocessador, os sistemas multiprocessadores estavam mais bem equipados para lidar com esta carga de trabalho. A fim de fornecer um sistema de custo-eficaz, o espaço de endereçamento de memória compartilhada tornou-se o foco da pesquisa. No início, sistemas usando um switch de barra cruzada foram defendidos, no entanto, com esta complexidade de projeto escalado, juntamente com o aumento dos processadores, o que tornou o sistema baseado em ônibus mais atraente. Processadores em um sistema de barramento são autorizados a acessar todo o espaço de memória, enviando pedidos no barramento, uma maneira muito econômica de usar a memória disponível da forma mais otimizada possível.
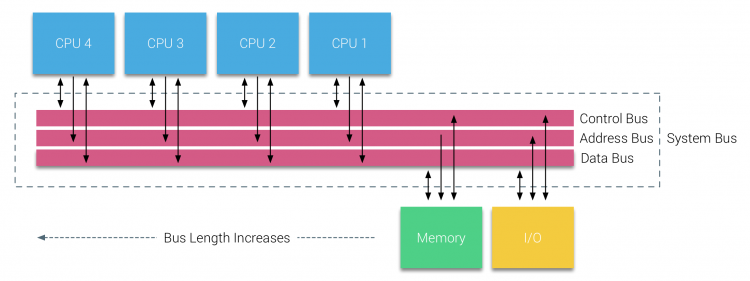
no entanto, os sistemas baseados em ônibus têm seus próprios problemas de escalabilidade. A questão principal é a quantidade limitada de largura de banda, isto restringe o número de processadores que o ônibus pode acomodar. A adição de CPUs ao sistema introduz duas grandes áreas de preocupação:
- a largura de banda disponível por nó diminui à medida que cada CPU é adicionada.
- o comprimento do barramento aumenta ao adicionar mais processadores, aumentando assim a latência.
o crescimento do desempenho da CPU e, especificamente, a diferença de velocidade entre o processador e o desempenho da memória foi, e na verdade ainda é, devastador para multiprocessadores. Uma vez que a diferença de memória entre processador e memória era esperada para aumentar, um grande esforço foi para desenvolver estratégias eficazes para gerenciar os sistemas de memória. Uma dessas estratégias foi a adição de cache de memória, que introduziu uma infinidade de desafios. Resolver esses desafios ainda é o foco principal de hoje para as equipes de design de CPU, muita pesquisa é feita sobre estruturas de cache e algoritmos sofisticados para evitar falhas de cache.
introdução de protocolos de cache snoop
anexar um cache a cada CPU aumenta o desempenho de muitas maneiras. Aproximar a memória da CPU reduz o tempo médio de acesso à memória e, ao mesmo tempo, reduz a carga de largura de banda no barramento da memória. O desafio com a adição de cache para cada CPU em uma arquitetura de memória compartilhada é que ele permite várias cópias de um bloco de memória para existir. Isto é chamado de problema de coerência de cache. Para resolver isso, protocolos Snoop Cache foram inventados tentando criar um modelo que forneceu os dados corretos, enquanto não tentando consumir toda a largura de banda no bus. O protocolo mais popular, escrever invalidar, apagar todas as outras cópias de dados antes de escrever o cache local. Qualquer leitura posterior destes dados por outros processadores irá detectar uma falha de cache em seu cache local e será atendida a partir do cache de outro CPU contendo os dados mais recentemente modificados. Este modelo salvou uma grande quantidade de largura de banda de barramento e permitiu que Sistemas uniformes de acesso à memória emergissem no início da década de 1990. modernos protocolos de coherência de cache são cobertos em mais detalhes pela parte 3.
Arquitetura uniforme de acesso à memória
processadores de multiprocessadores baseados em barramento que experimentam o mesmo – tempo uniforme de acesso a qualquer módulo de memória no sistema são muitas vezes referidos como Sistemas uniformes de acesso à memória (UMA) ou Multi-processadores simétricos (SMP).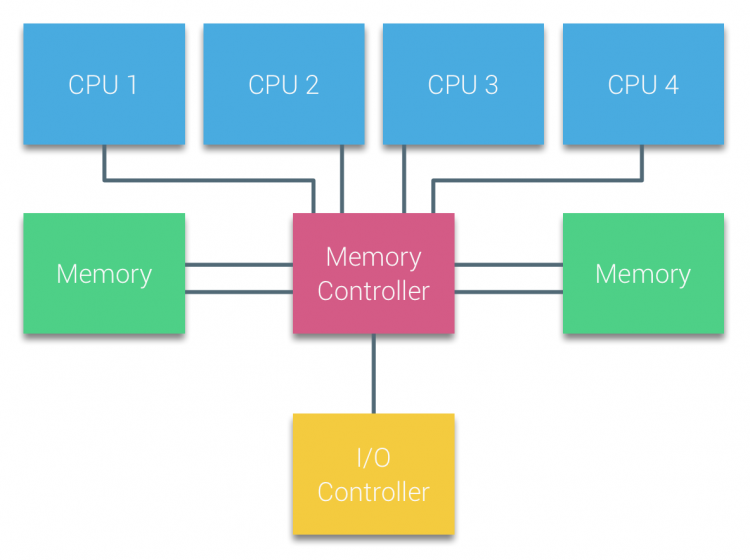
With UMA systems, the CPUs are connected via a system bus (Front-Side Bus) to the Northbridge. O Northbridge contém o controlador de memória e todas as comunicações de e para a memória devem passar pelo Northbridge. O controlador de E/S, responsável pela gestão de E / S a todos os dispositivos, Está ligado ao Northbridge. Portanto, todos os i / O têm de passar por Northbridge para chegar à CPU.
múltiplos barramentos e canais de memória são usados para dobrar a largura de banda disponível e reduzir o gargalo do Northbridge. Para aumentar ainda mais a largura de banda da memória, alguns sistemas conectaram controladores de memória externos ao Northbridge, melhorando a largura de banda e suporte de mais memória. No entanto, devido à largura de banda interna do Northbridge e a natureza de transmissão dos primeiros protocolos de cache snoopy, UMA foi considerada como tendo uma escamabilidade limitada. Com o uso atual de dispositivos flash de alta velocidade, empurrando centenas de milhares de IO por segundo, eles estavam absolutamente certos que esta arquitetura não iria escalar para futuras cargas de trabalho.
Arquitectura de acesso à memória não uniforme
para melhorar a escalabilidade e o desempenho são feitas três alterações críticas à arquitectura de multiprocessadores de memória partilhada;
- organização não uniforme de acesso à memória
- topologia interconectada ponto-a-ponto
- soluções escaláveis de coerência do cache
1: organização não uniforme de acesso à memória
NUMA afasta-se de um conjunto centralizado de memória e introduz propriedades topológicas. Ao classificar bases de localização de memória em comprimento do Caminho do sinal do processador para a memória, latência e gargalos de largura de banda podem ser evitados. Isto é feito redesenhando todo o sistema de processador e chipset. Arquiteturas NUMA ganharam popularidade no final dos anos 90, quando foi usado em supercomputadores SGI, como o Cray Origin 2000. NUMA ajudou a identificar a localização da memória, neste caso destes sistemas, Eles tiveram que se perguntar qual a região de memória em que chassis estava segurando os bits de memória.
na primeira metade da década de milênio, AMD trouxe NUMA para a paisagem empresarial onde sistemas UMA reinavam supremos. Em 2003, a família AMD Opteron foi introduzida, com controladores de memória integrados com cada CPU possuindo bancos de memória designados. Cada CPU tem agora seu próprio espaço de endereço de memória. Um sistema operacional NUMA otimizado, como o ESXi, permite que a carga de trabalho consuma memória de ambos os espaços de endereços de memória, enquanto otimiza para o acesso à memória local. Vamos usar um exemplo de um sistema de duas CPU para esclarecer a distinção entre acesso de memória local e remoto dentro de um único sistema.
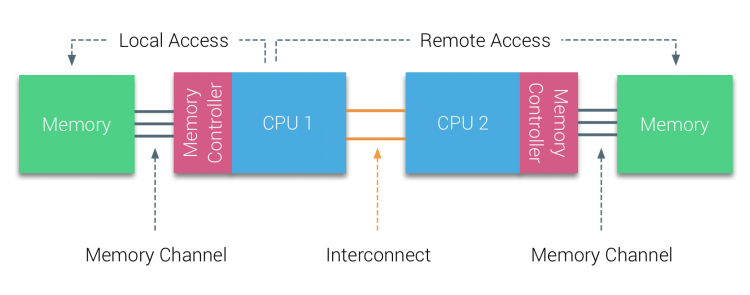
a memória ligada ao controlador de memória da CPU1 é considerada memória local. A memória conectada a outro socket de CPU (CPU2) é considerada estranha ou remota para CPU1. O acesso à memória remota tem latência adicional sobre o acesso à memória local, uma vez que tem de atravessar uma interligação (ligação ponto-a-ponto) e conectar-se ao controlador de memória remota. Como resultado das diferentes localizações de memória, este sistema experimenta tempo de acesso de memória” não uniforme”.
2: interconexão ponto-a-ponto
AMD introduziu sua conexão ponto-a-ponto HyperTransport com a microarquitetura AMD Opteron. A Intel se afastou de sua dupla arquitetura independente de ônibus em 2007, introduzindo a arquitetura QuickPath em seu design familiar de processadores Nehalem.
a arquitetura Nehalem foi uma mudança significativa de design dentro da microarquitetura Intel e é considerada a primeira geração verdadeira da Intel Core series. A arquitetura Broadwell atual é a quarta geração Da Marca Intel Core (Intel Xeon E5 v4), o último parágrafo contém mais informações sobre as gerações microarquiteturas. Dentro da arquitetura QuickPath, os controladores de memória moveram-se para a CPU e introduziram o QuickPath point-to-point Interconnect (QPI) como ligações de dados entre CPUs no sistema.
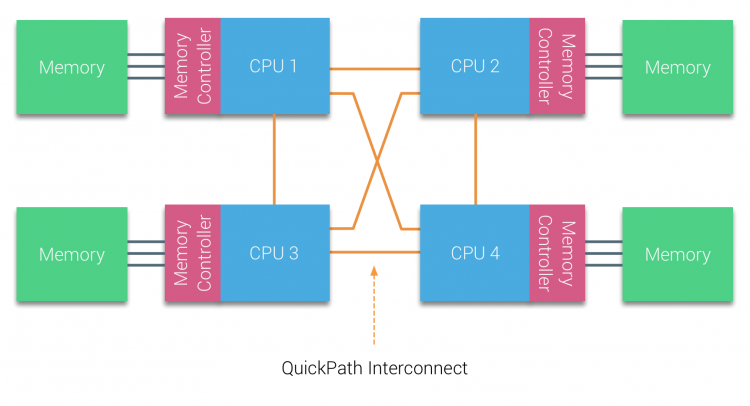
a microarquitetura Nehalem não só substituiu o barramento anterior legado, mas reorganizou todo o sub-sistema em um projeto modular para CPU servidor. Este projeto modular foi introduzido como o” Uncore ” e cria uma biblioteca de blocos de construção para cache e velocidades interconectadas. A remoção do barramento frontal melhora os problemas de escalabilidade da largura de banda, mas a comunicação intra e inter – processadores tem de ser resolvida quando se lida com enormes quantidades de capacidade de memória e largura de banda. Tanto o controlador de memória integrado quanto as interconexões QuickPath são uma parte da Uncore e são registradores específicos do modelo (MSR). Eles se conectam a um MSR que fornece a comunicação intra e inter – processadores. A modularidade do Uncore também permite que a Intel para oferecer diferentes QPI velocidades, na hora de escrever a Intel Broadwell-PE microarquitetura (2016) oferece 6.4 Giga-transferências por segundo (GT/s), 8.0 GT/s e 9,6 GT/s. Fornecendo, respectivamente, a largura de banda máxima teórica de 25,6 GB/s, 32 GB/s e 38,4 GB/s entre as CPUs. Para colocar isso em perspectiva, o último barramento frontal usado forneceu 1.6 GT/s ou 12.8 GB/s de largura de banda de plataforma. Ao introduzir Sandy Bridge Intel renomeado Uncore em agente de Sistema, no entanto, o termo Uncore ainda é usado na documentação atual. Você pode encontrar mais sobre o QuickPath e o Uncore na parte 2.
3: coerência de Cache escalável
cada núcleo tinha um caminho privado para o cache L3. Cada caminho consistia de mil fios e você pode imaginar que isso não escala bem se você quiser diminuir o processo de fabricação de nanômetro, enquanto também aumentar os núcleos que querem acessar o cache. A fim de ser capaz de escalar, a arquitetura da Ponte de areia moveu o cache L3 para fora do desconhecido e introduziu o anel escalável on-die Interconect. Isto permitiu que a Intel partisse e distribuísse o cache L3 em fatias iguais. Isto proporciona maior largura de banda e associatividade. Cada fatia é de 2,5 MB e uma fatia é associada a cada núcleo. O anel permite que cada núcleo tenha acesso a cada outra fatia. Ilustrada abaixo está a configuração de uma CPU Xeon Low Core Count (LCC) da microarquitetura Broadwell (v4) (2016).
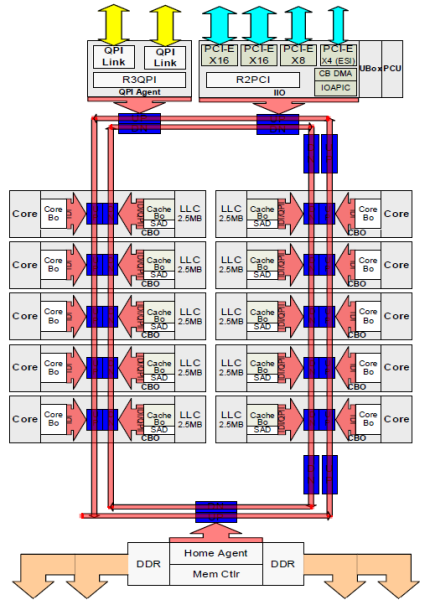
esta arquitectura de cache requer um protocolo de bisbilhotice que incorpora tanto o cache local distribuído como os outros processadores no sistema para garantir a coerência do cache. Com a adição de mais núcleos no sistema, a quantidade de tráfego snoop cresce, uma vez que cada núcleo tem seu próprio fluxo constante de falhas de cache. Isso afeta o consumo dos links de QPI e caches de último nível, exigindo o desenvolvimento contínuo nos protocolos de coherência snoop. Na parte 3 será incluída uma visão em profundidade da interconexão incipiente e escalável do anel na linha e da importância dos protocolos de cache snoop sobre o desempenho da NUMA.
numa = SUMA
a memória física é distribuída através da placa-mãe, no entanto, o sistema pode fornecer um único espaço de endereço de memória, intercalando a memória entre os dois nós NUMA. Isto é chamado de nó-interleaving (a configuração é coberta na parte 2). Quando o nó intercepta é ativado, o sistema se torna uma arquitetura de memória suficientemente uniforme (SUMA). Em vez de repassar a informação topológica e a natureza dos processadores e memória no sistema para o sistema operacional, o sistema quebra toda a gama de memória em regiões endereçáveis 4KB e mapeia-os de uma forma de robin redonda de cada nó. Isto fornece uma estrutura de memória ‘interleaved’ onde o espaço de endereço de memória é distribuído através dos nós. Quando a ESXi atribui a memória à máquina virtual, ela aloca a memória física localizada a partir de dois nós diferentes, quando a CPU física localizada no nó 0 precisa buscar a memória do nó 1, a memória atravessará as ligações de QPI.
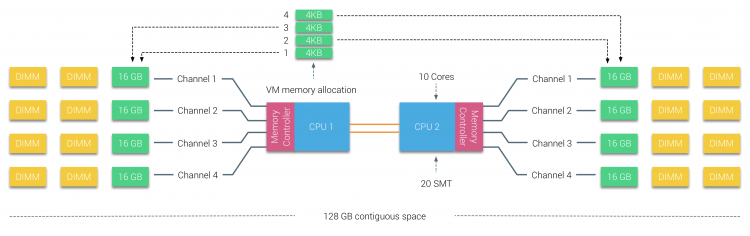
a coisa interessante é que o sistema SUMA fornece um tempo uniforme de acesso à memória. Apenas não é o mais ideal e depende fortemente dos níveis de contenção na arquitetura QPI. O Checker de latência de memória Intel foi usado para demonstrar as diferenças entre a configuração de NUMA e SUMA no mesmo sistema.
este ensaio mede as latências ociosas (em nanossegundos) de cada tomada para a outra tomada do sistema. A latência relatada do nó de memória 0 pelo Socket 0 é o acesso de memória local, o acesso de memória do socket 0 do nó de memória 1 é o acesso de memória remota no sistema configurado como NUMA.
| NUMA | Memória do Nó 0 | Nó de Memória 1 | – | a SUMA | Memória do Nó 0 | Nó de Memória 1 |
| Soquete 0 | 75.7 | 132.0 | – | Soquete 0 | 105.5 | 106.4 |
| Soquete 1 | 131.9 | 75.8 | – | Soquete 1 | 106.0 | 104.6 |
Como esperado intercalação é impactado pela constante atravessando o QPI links. O teste de memória ociosa é o melhor cenário, um teste mais interessante é medir latências carregadas. Teria sido um mau investimento se os seus servidores ESXi estão em marcha lenta SEM carga, por isso pode assumir que um sistema ESXi está a processar dados. A medição de latências carregadas proporciona uma melhor visão de como o sistema irá funcionar sob carga normal. Durante o ensaio, os atrasos na injecção de carga são automaticamente alterados a cada 2 segundos e tanto a largura de banda como a latência correspondente são medidas a esse nível. Este teste usa tráfego 100% lido.Resultados do teste numa à esquerda, resultados do teste de SUMA à direita.
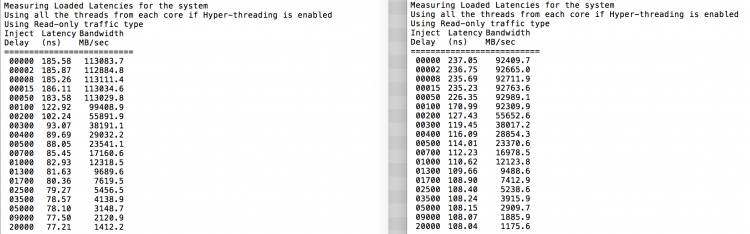
a largura de banda relatada para o sistema SUMA é menor, mantendo uma latência maior do que o sistema configurado como NUMA. Portanto, o foco deve ser na otimização do tamanho VM para alavancar as características NUMA do sistema.Com a introdução da microarquitetura Nehalem em 2008, a Intel se afastou da arquitetura Netburst. A microarquitetura Nehalem introduziu clientes da Intel na NUMA. Ao longo dos anos, a Intel introduziu novas microarquiteturas e otimizações, de acordo com seu famoso modelo Tick-Tock. Com cada Tick, a otimização ocorre, encolhendo a tecnologia de processo e com cada Tock uma nova microarquitetura é introduzida. Apesar de A Intel fornecer um modelo de marca consistente desde 2012, as pessoas tendem a usar codinome de arquitetura Intel para discutir as gerações tick e tock. Mesmo o EVC baselines lista esses codinome Intel interno, ambos nomes de marca e codinome de arquitetura serão usados ao longo desta série:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDDR3-2133 | Tock | 22nm |
| Broadwell | E5-26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4xDDR3-2400 | marque a opção | 14 nm |
Até a próxima, Parte 2: Arquitetura do Sistema
2016 NUMA Profunda Série de Mergulhos:
Parte 0: Introdução NUMA Profunda Série de Mergulhos
Parte 1: De UMA a NUMA
Parte 2: Arquitetura do Sistema
Parte 3: Coerência da Cache
Parte 4: Local de Memória de Otimização
Parte 5: ESXi VMkernel NUMA Construções