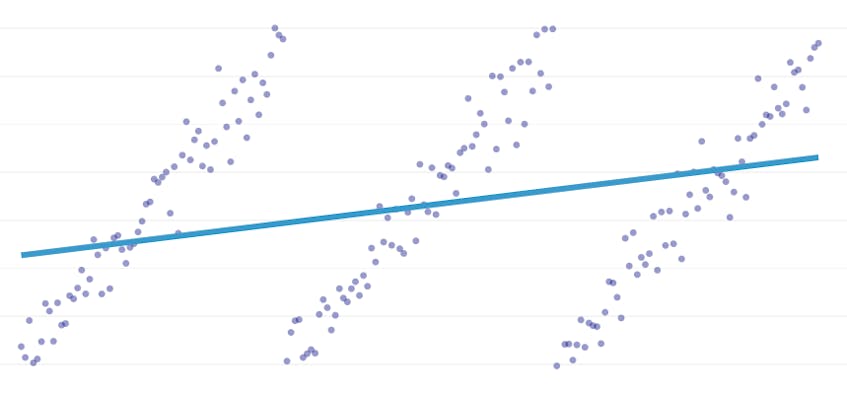
Esta regressão é um tipo especial de regressão linear que surge quando uma única linha não é suficiente para modelar um conjunto de dados. Regressão em trechos quebra o domínio em potencialmente muitos “segmentos” e cabe uma linha separada através de cada um. Por exemplo, nos gráficos abaixo, uma única linha não é capaz de modelar os dados, bem como uma regressão em trechos com três linhas:
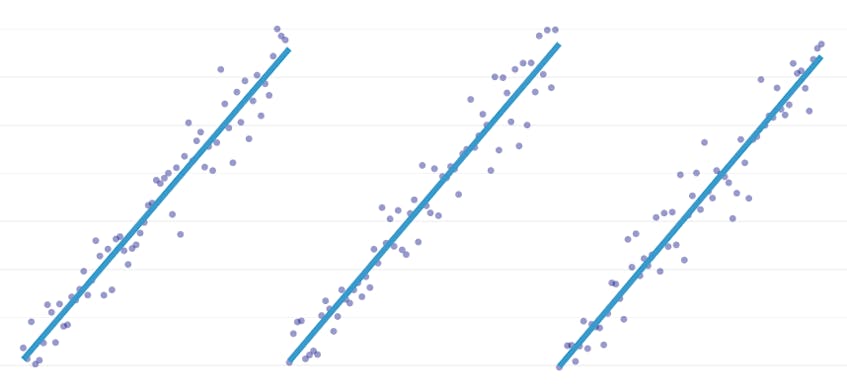
Este post apresenta Datadog de abordagem para automatizar piecewise de regressão em dados de séries de tempo.
Objectivos
Piecewise de regressão pode significar coisas ligeiramente diferentes em contextos diferentes, então vamos tomar um minuto para esclarecer o que exatamente estamos tentando alcançar com o nosso piecewise algoritmo regressão.
detecção automática de pontos de paragem. Na literatura de estatística clássica, a regressão em trechos é frequentemente sugerida durante o trabalho de análise de regressão manual, onde é óbvio a olho nu onde uma tendência linear dá lugar a outra. Nesse caso, um ser humano pode especificar o ponto de ruptura entre segmentos de trechos, dividir o conjunto de dados, e realizar uma regressão linear em cada segmento independentemente. Em nossos casos de uso, queremos fazer centenas de regressões por segundo, e não é possível ter um humano especificar todos os pontos de paragem. Em vez disso, temos o requisito de que nosso algoritmo de regressão em trechos identifique seus próprios pontos de ruptura.Detecção automática de contagem de segmentos. Se soubéssemos que um conjunto de dados tem exatamente dois segmentos, poderíamos facilmente olhar para cada um dos possíveis pares de segmentos. No entanto, na prática, quando dada uma série cronológica arbitrária, não há razão para acreditar que deve haver mais de um segmento ou menos de 3 ou 4 ou 5. Nosso algoritmo deve escolher um número apropriado de segmentos sem que ele seja especificado pelo Usuário.
sem necessidade de continuidade. Alguns métodos para regressões em trechos geram segmentos conectados, onde o ponto final de cada segmento é o ponto inicial do próximo segmento. Não impomos tal exigência ao nosso algoritmo.
Challenges
The most obvious challenge to implementing a piecewise regression with automated breakpoint detection is the large size of the solution search space; a brute-force search of all the possible segments is prohibitively expensive. O número de maneiras que uma série cronológica pode ser dividida em segmentos é exponencial no comprimento da série cronológica. Enquanto a programação dinâmica pode ser usada para atravessar este espaço de busca muito mais eficientemente do que uma implementação ingênua de Força bruta, ainda é muito lenta na prática. Um heurístico ganancioso será necessário para descartar rapidamente grandes áreas do espaço de busca.
um desafio mais sutil é que precisamos de alguma forma de comparar a qualidade de uma solução a outra. Para a nossa versão do problema, com números desconhecidos e localizações de segmentos, precisamos comparar soluções potenciais com diferentes números de segmentos e pontos de paragem diferentes. Estamos a tentar equilibrar dois objectivos concorrentes.:
- minimizar os erros. Ou seja, fazer a reta de regressão de cada segmento próximo dos pontos de dados observados.
- usa o menor número de segmentos que modelam bem os dados. Poderíamos sempre obter um erro zero criando um único segmento para cada ponto (ou mesmo um segmento para cada dois pontos). No entanto, isso iria derrotar todo o ponto de fazer uma regressão; nós não aprenderíamos nada sobre a relação geral entre um timestamp e seu valor métrico associado, e não poderíamos facilmente usar o resultado para interpolação ou extrapolação.
Our solution
We use the following greedy algorithm for the piecewise regression problem:
- faz uma regressão em trechos com segmentos n / 2, onde n é o número de observações na série cronológica. A reta de regressão em cada segmento é ajustada usando regressão dos mínimos quadrados ordinários (OLS). Esta regressão inicial em trechos terá quase nenhum erro, mas irá sobrecarregar severamente o conjunto de dados.
- iterativamente, até que haja apenas um segmento:
- para todos os pares de segmentos vizinhos, avalie o aumento no erro total que resultaria se os dois segmentos fossem combinados, suas duas linhas de regressão sendo substituídas por uma única linha de regressão.
- juntar o par de segmentos que resultaria no menor aumento de erro.
- se a realização desta junção cumpre os nossos critérios de paragem (definidos abaixo), então podemos ter ido longe demais, fundindo dois segmentos que devem permanecer separados. Se este for o caso, lembre-se do Estado dos segmentos antes da fusão desta iteração.
- Se nenhuma fusão resultou em lembrar o estado dos segmentos em (2c) acima, então a melhor solução é um segmento grande. Caso contrário, o último estado de segmento a ser lembrado em (2c) é a melhor solução.
critérios de paragem
consideramos uma junção como um ponto de paragem potencial se aumentar a soma total dos erros ao quadrado em mais do que qualquer junção anterior. Para evitar parar muito cedo nos casos em que deveria haver apenas um segmento, não consideraremos uma junção como um ponto de parada potencial a menos que resulte em um aumento no erro total que é menos de 3% do erro total de uma regressão com um segmento. (Os 3% são um limiar arbitrário, mas na prática considerámos que funcionam bem.) Abaixo estão alguns exemplos para demonstrar por que esse critério de parada funciona.
em primeiro lugar, vamos olhar para um conjunto de dados que foi gerado pela adição de ruído normalmente distribuído em pontos ao longo de uma única linha. O algoritmo encaixa corretamente apenas um segmento através deste conjunto de dados.
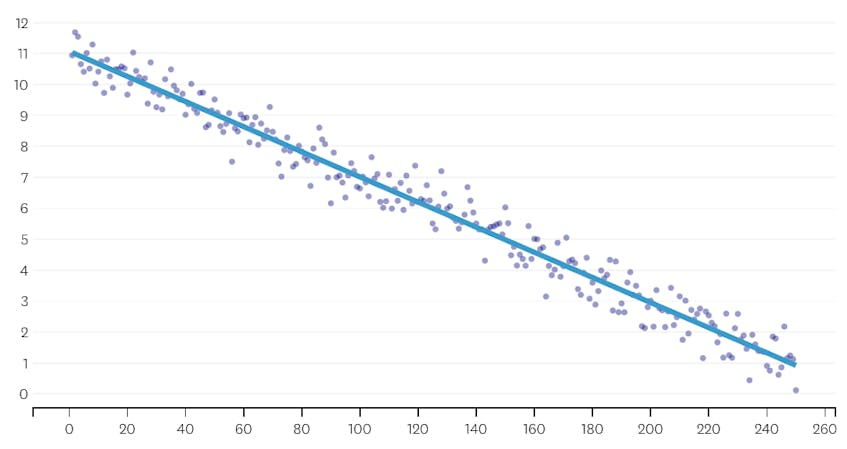
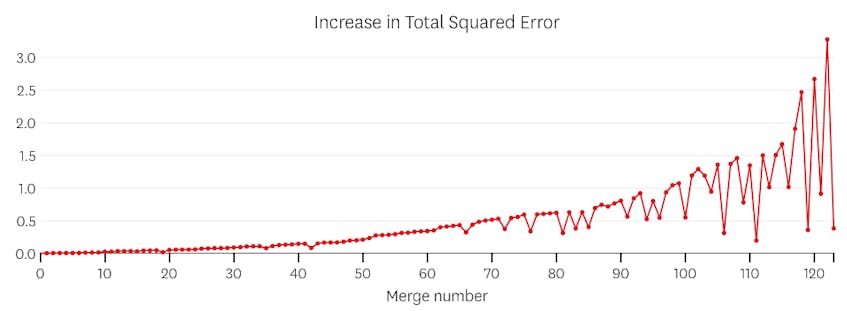
neste caso, nenhuma junção nunca aumenta a soma total de erros ao quadrado em mais de 3%. Portanto, nenhum merge é considerado um ponto de parada adequado, e usamos o estado final depois de todas as merges terem sido executadas. No gráfico abaixo, vemos que as fusões posteriores tendem a introduzir mais erros do que os anteriores (o que faz sentido porque cada um deles impacta mais pontos), mas o aumento do erro só aumenta gradualmente à medida que mais segmentos são fundidos.
em segundo lugar, vamos olhar um exemplo onde existem sete segmentos distintos no conjunto de dados.
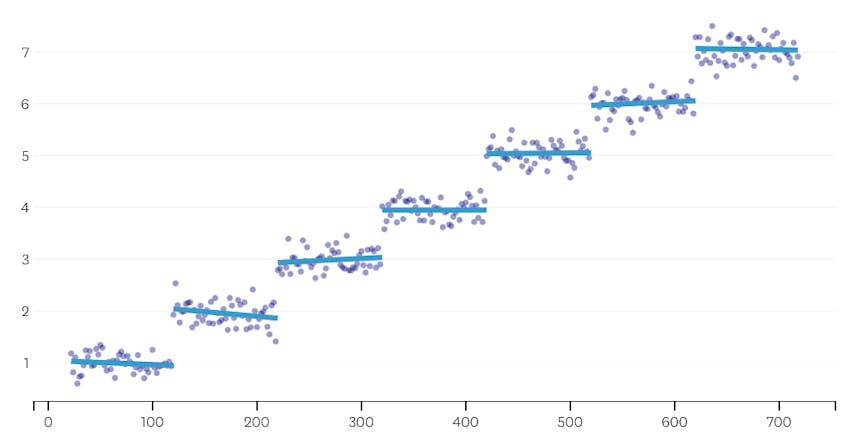
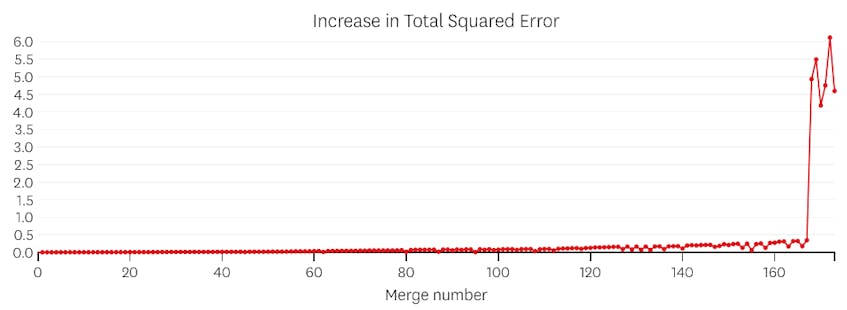
neste caso, quando olhamos para o enredo de erros introduzidos por cada série, vemos que os últimos seis mescla introduzida muito mais erro do que qualquer um dos anteriores mescla. Portanto, o nosso algoritmo lembrou-se do Estado dos segmentos antes da 6ª-última fusão e usou-o como solução final.
The code
In The Datadog/piecewise Github repo, you’ll find our Python implementation of the algorithm. A função piecewise() é onde ocorre o levantamento pesado; dado um conjunto de dados, ele irá retornar a localização e coeficientes de regressão para cada um dos segmentos instalados.
também incluído no gist é
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)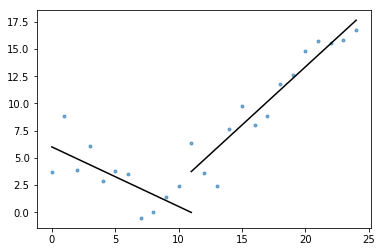
Enquanto esta implementação utiliza OLS de regressão linear, o mesmo quadro pode ser adaptado para resolver problemas relacionados. Ao substituir o erro quadrado por Erro absoluto ou perda Huber, a regressão pode ser feita robusta. Ou, uma função step pode ser adequada atribuindo a cada segmento um valor constante igual à média das observações em seu domínio.