Modelul Markov ascuns (HMM) este un model statistic Markov în care se presupune că sistemul modelat este un proces Markov cu stări neobservate (adică ascunse).
modelele Markov ascunse sunt cunoscute în special pentru aplicarea lor în învățarea întăririi și recunoașterea modelului temporal, cum ar fi vorbirea, scrierea de mână, recunoașterea gesturilor, etichetarea parțială a vorbirii, urmărirea partiturii muzicale, descărcările parțiale și bioinformatica.
terminologie în HMM
termenul ascuns se referă la procesul Markov de ordinul întâi din spatele observației. Observarea se referă la datele pe care le cunoaștem și le putem observa. Procesul Markov este prezentat de interacțiunea dintre” ploios „și” însorit ” în diagrama de mai jos și fiecare dintre acestea sunt stări ascunse.

observațiile sunt date cunoscute și se referă la „plimbare”, „magazin” și „curat” în diagrama de mai sus. În sensul învățării automate, observarea este datele noastre de antrenament, iar numărul de stări ascunse este hiper parametrul nostru pentru modelul nostru. Evaluarea modelului va fi discutată mai târziu.

T = nu aveți încă nicio observație, N = 2, M = 3, Q = {„Rainy”, „Sunny”}, V = {„Walk”, „Shop”, „Clean”}
probabilitățile de tranziție de stat sunt săgețile care indică fiecare stare ascunsă. Matricea de probabilitate de observare sunt săgețile albastre și roșii care indică fiecare observație din fiecare stare ascunsă. Matricea sunt rând stochastic sensul rândurile adăuga până la 1.


matricea explică care este probabilitatea de a merge la o stare la alta sau de a trece de la o stare la o observație.
distribuția inițială a stării face ca modelul să meargă pornind de la o stare ascunsă.
modelul complet cu probabilități de tranziție de stare cunoscute, matricea de probabilitate de observare și distribuția inițială a stării sunt marcate ca,
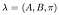
cum putem construi modelul de mai sus în Python?
în cazul de mai sus, emisiile sunt discrete {„Walk”, „Shop”, „Clean”}. MultinomialHMM din biblioteca hmmlearn este utilizat pentru modelul de mai sus. GaussianHMM și GMMHMM sunt alte modele din bibliotecă.
acum, cu HMM, care sunt câteva probleme cheie de rezolvat?
- Problema 1, Având în vedere un model cunoscut care este probabilitatea ca secvența O să se întâmple?
- Problema 2, Având în vedere un model cunoscut și secvența o, care este secvența optimă de stare ascunsă? Acest lucru va fi util dacă vrem să știm dacă vremea este” ploioasă „sau”însorită”
- Problema 3, având în vedere secvența O și numărul de stări ascunse, care este modelul optim care maximizează probabilitatea de O?
Problema 1 în Python
probabilitatea ca prima observație să fie” plimbare ” este egală cu multiplicarea matricei inițiale de distribuție a stării și a probabilității de emisie. 0, 6 x 0, 1 + 0, 4 x 0, 6 = 0, 30 (30%). Probabilitatea jurnalului este furnizată de la apelare .scor.
Problema 2 în Python

având în vedere modelul cunoscut și observația {„Shop”, „Clean”, „Walk”}, vremea a fost cel mai probabil {„Rainy”, „Rainy”, „Sunny”} cu o probabilitate de ~1,5%.
având în vedere modelul cunoscut și observația {„curat”, „curat”, „curat”}, vremea a fost cel mai probabil {„ploios”, „ploios”, „ploios”} cu o probabilitate de ~3,6%.
intuitiv, când apare” plimbarea”, Vremea cel mai probabil nu va fi”ploioasă”.
Problema 3 în Python
recunoașterea vorbirii cu Fișier Audio: prezice aceste cuvinte

amplitudinea poate fi folosită ca observație pentru HMM, dar ingineria caracteristicilor ne va oferi mai multă performanță.

funcția stft și peakfind generează caracteristică pentru semnal audio.
exemplul de mai sus a fost luat de aici. Kyle Kastner construit clasa HMM care ia în matrice 3d, folosesc hmmlearn care permite numai matrice 2D. Acesta este motivul pentru care reduc caracteristicile generate de Kyle Kastner ca X_test.medie(axă = 2).
trecerea prin această modelare a durat mult timp pentru a înțelege. Am avut impresia că variabila țintă trebuie să fie observația. Acest lucru este valabil pentru seriile de timp. Clasificarea se face prin construirea HMM pentru fiecare clasă și compara ieșire prin calcularea logprob pentru intrare.
soluție matematică la problema 1: Algoritmul înainte

Alpha pass este probabilitatea de observare și secvența de stat dat model.
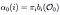
trecerea alfa la timp (t) = 0, distribuția inițială a stării la i și de acolo la prima observație O0.
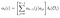
trecerea alfa la timp (t) = t, suma ultimei treceri alfa la fiecare stare ascunsă înmulțită cu emisia la Ot.
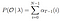
soluție matematică la problema 2: Algoritmul înapoi


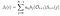

având în vedere modelul și observația, probabilitatea de a fi la starea qi la momentul t.
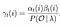
soluție matematică la problema 3: Algoritm Înainte-Înapoi


probabilitatea de la stat qi la qj la momentul t cu modelul dat și observație
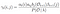
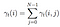
suma tuturor probabilităților de tranziție de la i la j.
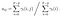
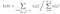
matricea de probabilitate de tranziție și emisie este estimată cu di-gamma.
Itera dacă probabilitatea pentru P(O|model) crește