Non-uniform memory access (NUMA) este o arhitectură de memorie partajată utilizată în sistemele multiprocesare de astăzi. Fiecărui procesor i se atribuie propria memorie locală și poate accesa memoria de la alte procesoare din sistem. Accesul la memoria locală oferă o latență scăzută-performanță ridicată a lățimii de bandă. În timp ce accesați memoria deținută de celălalt procesor are o latență mai mare și o performanță mai mică a lățimii de bandă. Aplicațiile moderne și sistemele de operare, cum ar fi ESXi, acceptă NUMA în mod implicit, dar pentru a oferi cea mai bună performanță, configurația mașinii virtuale ar trebui făcută având în vedere arhitectura NUMA. Dacă este proiectat incorect, se produce un comportament inconsecvent sau o degradare generală a performanței pentru mașina virtuală respectivă sau, în cel mai rău caz, pentru toate VM-urile care rulează pe acea gazdă ESXi.
această serie își propune să ofere informații despre arhitectura procesorului, subsistemul de memorie și ESXi CPU și Memory scheduler. Permițându-vă în crearea unei platforme de înaltă performanță, care pune bazele pentru servicii mai mari și a crescut consolidarea rapoarte. Înainte de a ajunge la arhitecturi moderne de calcul, este util să revizuim Istoricul arhitecturilor multiprocesor cu memorie partajată pentru a înțelege de ce folosim sistemele NUMA astăzi.
- Evoluția arhitecturii multiprocesoarelor cu memorie partajată în ultimele decenii
- introducerea protocoalelor snoop în cache
- Uniform Memory Access Architecture
- arhitectura neuniformă de acces la memorie
- 1: Organizarea neuniformă a accesului la memorie
- 2: interconectare punct-la-punct
- 3: coerență cache scalabilă
- non-intercalat activat NUMA = SUMA
- Nehalem & prezentare generală a microarhitecturii de bază
Evoluția arhitecturii multiprocesoarelor cu memorie partajată în ultimele decenii
se pare că o arhitectură numită acces uniform la memorie ar fi o potrivire mai bună atunci când se proiectează o platformă consistentă de latență scăzută, lățime de bandă mare. Cu toate acestea, arhitecturile de sistem moderne îl vor împiedica să fie cu adevărat uniform. Pentru a înțelege motivul din spatele acestui lucru, trebuie să ne întoarcem în istorie pentru a identifica factorii cheie ai calculului paralel.
odată cu introducerea Bazelor de date relaționale la începutul anilor șaptezeci, nevoia de sisteme care ar putea deservi mai multe operațiuni concurente ale utilizatorilor și generarea excesivă de date a devenit mainstream. În ciuda ratei impresionante de performanță a uniprocesorului, sistemele multiprocesor au fost mai bine echipate pentru a face față acestei sarcini de lucru. Pentru a oferi un sistem rentabil, spațiul de adrese de memorie partajat a devenit punctul central al cercetării. La început, au fost susținute sisteme care foloseau un comutator transversal, cu toate acestea, această complexitate a designului a fost scalată odată cu creșterea procesoarelor, ceea ce a făcut ca sistemul bazat pe magistrală să fie mai atractiv. Procesoarele dintr-un sistem bus au voie să acceseze întregul spațiu de memorie prin trimiterea de solicitări în autobuz, o modalitate foarte rentabilă de a utiliza memoria disponibilă cât mai optim posibil.
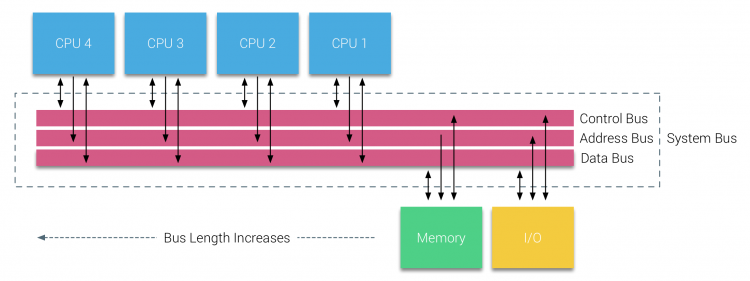
cu toate acestea, sistemele bazate pe autobuze au propriile probleme de scalabilitate. Problema principală este cantitatea limitată de lățime de bandă, aceasta restrânge numărul de procesoare pe care autobuzul le poate găzdui. Adăugarea procesoarelor la sistem introduce două domenii majore de îngrijorare:
- lățimea de bandă disponibilă pe nod scade odată cu adăugarea fiecărui procesor.
- lungimea magistralei crește atunci când adăugați mai multe procesoare, crescând astfel latența.
creșterea performanței procesorului și în special decalajul de viteză dintre procesor și performanța memoriei a fost, și de fapt este încă, devastator pentru multiprocesoare. Deoarece decalajul de memorie dintre procesor și memorie era de așteptat să crească, s-au depus multe eforturi pentru a dezvolta strategii eficiente de gestionare a sistemelor de memorie. Una dintre aceste strategii a fost adăugarea memoriei cache, care a introdus o multitudine de provocări. Rezolvarea acestor provocări este în continuare principalul obiectiv al echipelor de proiectare a procesorului, se fac multe cercetări asupra structurilor de cache și a algoritmilor sofisticați pentru a evita pierderea cache-ului.
introducerea protocoalelor snoop în cache
atașarea unui cache la fiecare procesor crește performanța în mai multe moduri. Aducerea memoriei mai aproape de CPU reduce timpul mediu de acces la memorie și, în același timp, reduce încărcarea lățimii de bandă pe magistrala de memorie. Provocarea cu adăugarea cache-ului la fiecare procesor într-o arhitectură de memorie partajată este că permite existența mai multor copii ale unui bloc de memorie. Aceasta se numește problema cache-coerență. Pentru a rezolva acest lucru, s-au inventat protocoalele de cache snoop încercând să creeze un model care să furnizeze datele corecte, fără a încerca să mănânce toată lățimea de bandă din autobuz. Cel mai popular protocol, write invalidate, șterge toate celelalte copii ale datelor înainte de a scrie memoria cache locală. Orice citire ulterioară a acestor date de către alte procesoare va detecta o lipsă de cache în memoria cache locală și va fi deservită din memoria cache a unui alt procesor care conține cele mai recente date modificate. Acest model a salvat o mulțime de lățime de bandă a autobuzului și a permis apariția sistemelor uniforme de acces la memorie la începutul anilor 1990. protocoalele moderne de coerență a cache-ului sunt acoperite mai detaliat de partea 3.
Uniform Memory Access Architecture
procesoarele multiprocesoarelor bazate pe magistrală care experimentează același timp de acces uniform la orice modul de memorie din sistem sunt adesea denumite sisteme de acces uniform la memorie (UMA) sau multi-procesoare simetrice (SMP).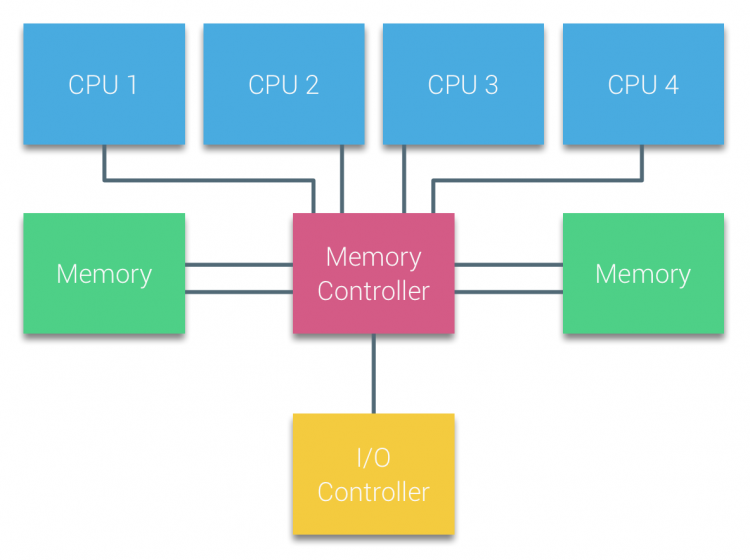
cu sistemele UMA, procesoarele sunt conectate printr-o magistrală de sistem (magistrală frontală) la Northbridge. Northbridge conține controlerul de memorie și toate comunicațiile către și dinspre memorie trebuie să treacă prin Northbridge. Controlerul I/O, responsabil pentru gestionarea I / O la toate dispozitivele, este conectat la Northbridge. Prin urmare, fiecare I/O trebuie să treacă prin Northbridge pentru a ajunge la CPU.
mai multe autobuze și canale de memorie sunt utilizate pentru a dubla lățimea de bandă disponibilă și pentru a reduce blocajul podului de Nord. Pentru a crește și mai mult lățimea de bandă a memoriei, unele sisteme au conectat controlere de memorie externe la Northbridge, îmbunătățind lățimea de bandă și suport pentru mai multă memorie. Cu toate acestea, datorită lățimii de bandă interne a Northbridge și a naturii de difuzare a protocoalelor cache snoopy timpurii, UMA a fost considerat a avea o scalabilitate limitată. Cu utilizarea de astăzi a dispozitivelor flash de mare viteză, împingând sute de mii de IO pe secundă, au avut absolut dreptate că această arhitectură nu va fi scalată pentru sarcini de lucru viitoare.
arhitectura neuniformă de acces la memorie
pentru a îmbunătăți scalabilitatea și performanța, se fac trei modificări critice la arhitectura multiprocesoarelor cu memorie partajată;
- organizare neuniformă a accesului la memorie
- topologie de interconectare punct-la-punct
- soluții de coerență cache scalabile
1: Organizarea neuniformă a accesului la memorie
NUMA se îndepărtează de un bazin centralizat de memorie și introduce proprietăți topologice. Prin clasificarea bazelor de localizare a memoriei pe lungimea căii semnalului de la procesor la memorie, pot fi evitate blocajele de latență și lățime de bandă. Acest lucru se face prin reproiectarea întregului sistem de procesor și chipset. Arhitecturile NUMA au câștigat popularitate la sfârșitul anilor 90, când au fost utilizate pe supercomputerele SGI, cum ar fi Cray Origin 2000. NUMA a ajutat la identificarea locației memoriei, în acest caz a acestor sisteme, au trebuit să se întrebe ce regiune de memorie în care șasiu ținea biții de memorie.
în prima jumătate a deceniului mileniului, AMD a adus NUMA în peisajul întreprinderii, unde UMA systems a domnit suprem. În 2003 a fost introdusă familia AMD Opteron, cu controlere de memorie integrate, fiecare procesor deținând bănci de memorie desemnate. Fiecare procesor are acum propriul spațiu de adrese de memorie. Un sistem de operare optimizat NUMA, cum ar fi ESXi, permite volumului de lucru să consume memorie din ambele spații de adrese de memorie, optimizând în același timp accesul la memoria locală. Să folosim un exemplu de sistem cu două procesoare pentru a clarifica distincția dintre accesul la memorie locală și la distanță într-un singur sistem.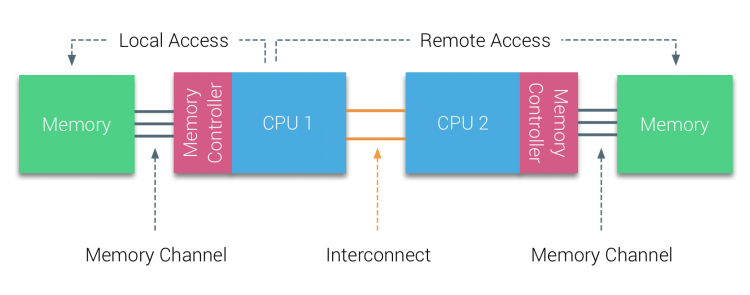
memoria conectată la controlerul de memorie al CPU1 este considerată memorie locală. Memoria conectată la un alt soclu CPU (CPU2)este considerată străină sau la distanță pentru CPU1. Accesul la memorie la distanță are o latență suplimentară deasupra capului la accesul la memorie locală, deoarece trebuie să traverseze o interconectare (legătură punct-la-punct) și să se conecteze la controlerul de memorie la distanță. Ca urmare a diferitelor locații de memorie, acest sistem are un timp de acces la memorie „neuniform”.
2: interconectare punct-la-punct
AMD și-a introdus HyperTransport-ul de conexiune punct-la-punct cu microarhitectura AMD Opteron. Intel s-a îndepărtat de arhitectura autobuzului dual independent în 2007, introducând arhitectura QuickPath în designul familiei de procesoare Nehalem.
arhitectura Nehalem a fost o schimbare semnificativă de design în cadrul microarhitecturii Intel și este considerată prima generație adevărată a seriei Intel Core. Actuala arhitectură Broadwell este a 4-a generație a mărcii Intel Core (Intel Xeon E5 v4), ultimul paragraf conține mai multe informații despre generațiile de microarhitectură. În cadrul arhitecturii QuickPath, controlerele de memorie s-au mutat la CPU și au introdus QuickPath interconectare punct-la-punct (QPI) ca legături de date între procesoarele din sistem.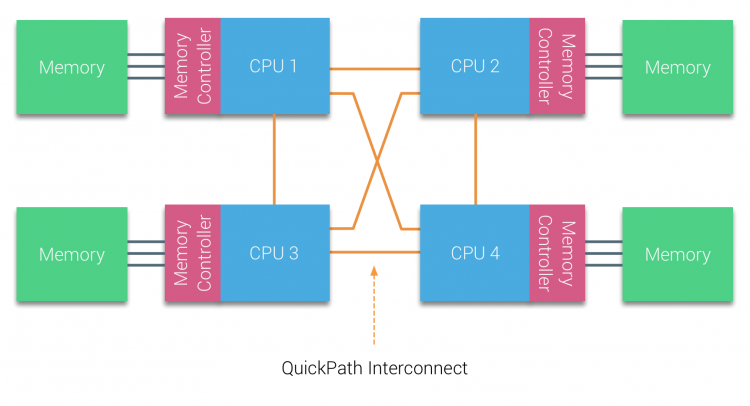
microarhitectura Nehalem nu numai că a înlocuit magistrala frontală moștenită, dar a reorganizat întregul sub-sistem într-un design modular pentru CPU server. Acest design modular a fost introdus ca „Uncore” și creează o bibliotecă de blocuri pentru cache și viteze de interconectare. Scoaterea magistralei frontale îmbunătățește problemele de scalabilitate a lățimii de bandă, totuși comunicarea intra – și inter-procesor trebuie rezolvată atunci când se ocupă de cantități enorme de capacitate de memorie și lățime de bandă. Atât controlerul de memorie integrat, cât și interconectările QuickPath fac parte din Uncore și sunt registre specifice modelului (MSR) ). Se conectează la un MSR care asigură comunicarea intra – și inter-procesor. Modularitatea Uncore permite, de asemenea, Intel să ofere viteze QPI diferite, la momentul scrierii microarhitecturii Intel Broadwell-EP (2016) oferă 6, 4 Giga-transferuri pe secundă (GT/S), 8, 0 GT/S și 9, 6 GT/s. respectiv oferind o lățime de bandă teoretică maximă de 25, 6 GB/s, 32 GB/s și 38, 4 GB/s între procesoare. Pentru a pune acest lucru în perspectivă, ultima magistrală frontală utilizată a furnizat 1,6 GT/S sau 12,8 GB/s lățime de bandă a platformei. La introducerea Sandy Bridge Intel rebranded Uncore în agent de sistem, totuși termenul Uncore este încă utilizat în documentația curentă. Puteți găsi mai multe despre QuickPath și Uncore în partea 2.
3: coerență cache scalabilă
fiecare nucleu avea o cale privată către memoria cache L3. Fiecare cale a constat dintr-o mie de fire și vă puteți imagina că acest lucru nu se scalează bine dacă doriți să reduceți procesul de fabricație a nanometrilor, crescând în același timp nucleele care doresc să acceseze memoria cache. Pentru a putea scala, arhitectura Sandy Bridge a mutat cache-ul L3 din Uncore și a introdus interconectarea scalabilă ring on-die. Acest lucru a permis Intel să partiționeze și să distribuie memoria cache L3 în felii egale. Aceasta oferă o lățime de bandă mai mare și asociativitate. Fiecare felie este de 2,5 MB și o felie este asociată cu fiecare miez. Inelul permite fiecărui miez să acceseze și fiecare altă felie. În imaginea de mai jos este configurația matriței unui procesor Xeon Low Core Count (LCC) al microarhitecturii Broadwell (v4) (2016).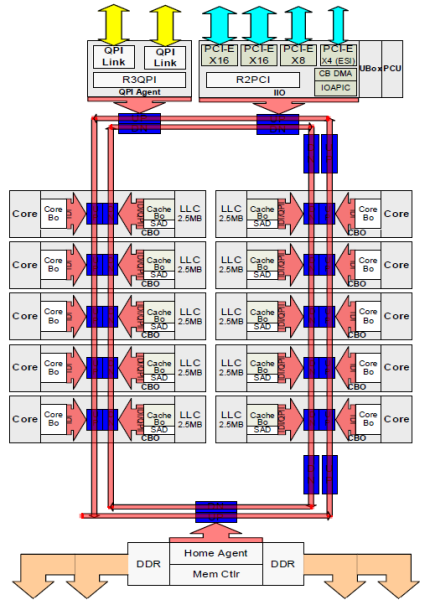
această arhitectură de cache necesită un protocol de snooping care încorporează atât cache local distribuit, cât și celelalte procesoare din sistem pentru a asigura coerența cache-ului. Odată cu adăugarea mai multor nuclee în sistem, cantitatea de trafic snoop crește, deoarece fiecare nucleu are propriul flux constant de pierderi de cache. Acest lucru afectează consumul legăturilor QPI și al cache-urilor de ultimul nivel, necesitând o dezvoltare continuă în protocoalele de coerență snoop. O vedere în profunzime a interconectării Necore, scalabile ring on-Die și importanța memorării în cache a protocoalelor snoop privind performanța NUMA vor fi incluse în partea 3.
non-intercalat activat NUMA = SUMA
memoria fizică este distribuită pe placa de bază, cu toate acestea, sistemul poate oferi un singur spațiu de adrese de memorie prin intercalarea memoriei între cele două noduri NUMA. Aceasta se numește nod-intercalare (setarea este acoperită în partea 2). Când este activată intercalarea nodului, sistemul devine o arhitectură de memorie suficient de uniformă (SUMA). În loc să transmită informațiile de topologie și natura procesoarelor și a memoriei din sistem către sistemul de operare, sistemul descompune întreaga gamă de memorie în regiuni adresabile 4KB și le mapează într-un mod round robin de la fiecare nod. Aceasta oferă o structură de memorie intercalată în care spațiul de adrese de memorie este distribuit peste noduri. Când ESXi atribuie memorie mașinii virtuale, alocă memorie fizică localizată din două noduri diferite atunci când CPU-ul fizic situat în nodul 0 trebuie să preia memoria din nodul 1, memoria va traversa legăturile QPI.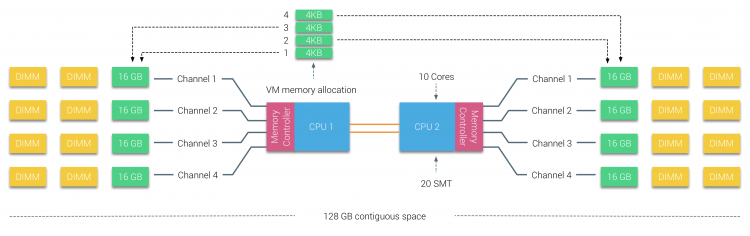
interesant este că sistemul SUMA oferă un timp uniform de acces la memorie. Numai că nu cel mai optim și depinde foarte mult de nivelurile de dispută din arhitectura QPI. Intel Memory Latency Checker a fost folosit pentru a demonstra diferențele dintre configurația NUMA și SUMA pe același sistem.
acest test măsoară latențele inactive (în nanosecunde) de la fiecare priză la cealaltă priză din sistem. Latența raportată a nodului de memorie 0 de Socket 0 este acces la memorie locală, accesul la memorie din socket 0 al nodului de memorie 1 este acces la memorie la distanță în sistemul configurat ca NUMA.
| NUMA | nod de memorie 0 | nod de memorie 1 | – | suma | nod de memorie 0 | nod de memorie 1 |
| soclu 0 | 75.7 | 132.0 | – | soclu 0 | 105.5 | 106.4 |
| soclu 1 | 131.9 | 75.8 | – | soclu 1 | 106.0 | 104.6 |
așa cum era de așteptat, intercalarea este afectată de traversarea constantă a legăturilor QPI. Testul de memorie inactiv este cel mai bun caz, un test mai interesant este măsurarea latențelor încărcate. Ar fi fost o investiție proastă dacă serverele ESXi sunt la ralanti, prin urmare, puteți presupune că un sistem ESXi procesează date. Măsurarea latențelor încărcate oferă o perspectivă mai bună asupra modului în care sistemul va funcționa sub sarcină normală. În timpul testului, întârzierile de injecție a sarcinii sunt modificate automat la fiecare 2 secunde și atât lățimea de bandă, cât și latența corespunzătoare sunt măsurate la acel nivel. Acest test utilizează 100% trafic citit.Rezultatele testului NUMA în stânga, rezultatele testului SUMA în dreapta.
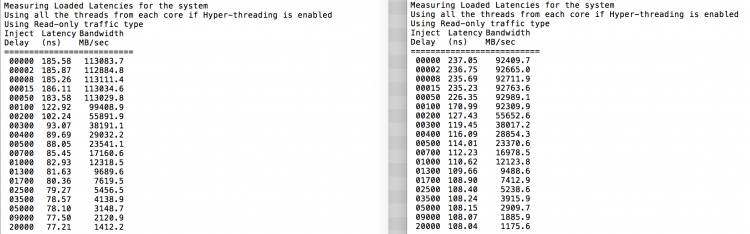
lățimea de bandă raportată pentru sistemul SUMA este mai mică, menținând în același timp o latență mai mare decât sistemul configurat ca NUMA. Prin urmare, accentul ar trebui să fie pe optimizarea dimensiunii VM pentru a valorifica caracteristicile NUMA ale sistemului.
Nehalem & prezentare generală a microarhitecturii de bază
odată cu introducerea microarhitecturii Nehalem în 2008, Intel s-a îndepărtat de arhitectura Netburst. Microarhitectura Nehalem a introdus clienții Intel la NUMA. De-a lungul anilor, Intel a introdus noi microarhitecturi și optimizări, conform celebrului său model Tick-Tock. Cu fiecare bifă, are loc optimizarea, micșorând tehnologia procesului și cu fiecare Tock este introdusă o nouă microarhitectură. Chiar dacă Intel oferă un model de branding consistent din 2012, oamenii tind să Intel architecture codenames pentru a discuta despre generațiile CPU tick și tock. Chiar și liniile de bază EVC listează aceste nume de cod Intel interne, atât numele de branding, cât și numele de cod de arhitectură vor fi utilizate pe parcursul acestei serii:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDDR3-2133 | Tock | 22nm |
| Broadwell | E5 – 26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4xDDR3-2400 | bifați | 14 nm |
în continuare, partea 2: arhitectura sistemului
seria NUMA Deep Dive din 2016:
partea 0: Introducere seria NUMA Deep Dive
Partea 1:de la UMA la NUMA
Partea 2: arhitectura sistemului
Partea 3: coerența Cache
Partea 4: Optimizarea memoriei locale
Partea 5: construcțiile ESXi VMkernel NUMA