regresia pe bucăți este un tip special de regresie liniară care apare atunci când o singură linie nu este suficientă pentru a modela un set de date. Regresia în bucăți rupe domeniul în potențial multe „segmente” și se potrivește cu o linie separată prin fiecare. De exemplu, în graficele de mai jos, o singură linie nu este capabilă să modeleze datele, precum și o regresie în bucăți cu trei linii:
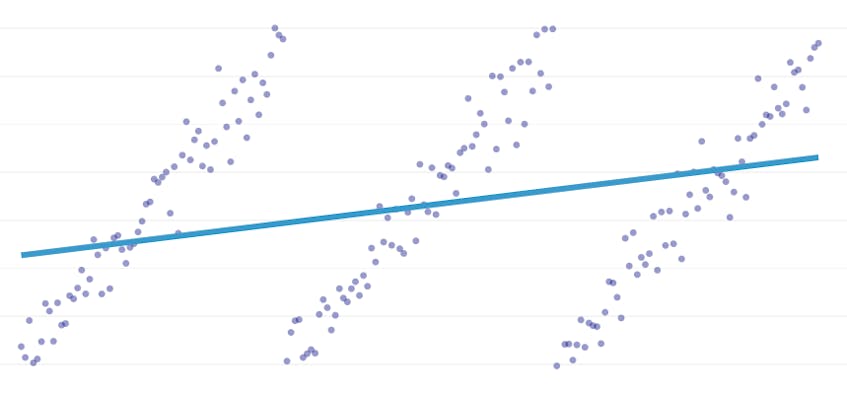
acest post prezintă abordarea Datadog de a automatiza regresia în bucăți pe datele seriilor de timp.
obiective
regresia în bucăți poate însemna lucruri ușor diferite în contexte diferite, așa că haideți să luăm un minut pentru a clarifica ce anume încercăm să realizăm cu algoritmul nostru de regresie în bucăți.
detectare automată a punctului de întrerupere. În literatura statistică clasică, regresia pe bucăți este adesea sugerată în timpul analizei Manuale a regresiei, unde este evident cu ochiul liber unde o tendință liniară dă loc alteia. În acest caz, un om poate specifica punctul de întrerupere între segmente în bucăți, poate împărți setul de date și poate efectua o regresie liniară pe fiecare segment independent. În cazurile noastre de utilizare, vrem să facem sute de regresii pe secundă și nu este posibil ca un om să specifice toate punctele de întrerupere. În schimb, avem cerința ca algoritmul nostru de regresie în bucăți să identifice propriile Puncte de întrerupere.
detectarea automată a numărului de segmente. Dacă ar fi să știm că un set de date are exact două segmente, am putea privi cu ușurință fiecare dintre perechile posibile de segmente. Cu toate acestea, în practică, atunci când este dată o serie de timp arbitrară, nu există niciun motiv să credem că trebuie să existe mai mult de un segment sau mai puțin de 3 sau 4 sau 5. Algoritmul nostru trebuie să aleagă un număr adecvat de segmente fără a fi specificat de utilizator.
nicio cerință de continuitate. Unele metode pentru regresii în bucăți generează segmente conectate, unde punctul final al fiecărui segment este punctul de pornire al următorului segment. Nu impunem o astfel de cerință algoritmului nostru.
provocări
cea mai evidentă provocare pentru implementarea unei regresii în bucăți cu detectarea automată a punctului de întrerupere este dimensiunea mare a spațiului de căutare a soluției; o căutare cu forță brută a tuturor segmentelor posibile este prohibitiv costisitoare. Numărul de moduri în care o serie de timp poate fi împărțită în segmente este exponențial în lungimea seriei de timp. În timp ce programarea dinamică poate fi utilizată pentru a traversa acest spațiu de căutare mult mai eficient decât o implementare naivă a forței brute, este încă prea lentă în practică. Va fi nevoie de o euristică lacomă pentru a arunca rapid zone mari din spațiul de căutare.
o provocare mai subtilă este că avem nevoie de un mod de a compara calitatea unei soluții cu alta. Pentru versiunea noastră a problemei, cu numere necunoscute și locații de segmente, trebuie să comparăm soluțiile potențiale cu numere diferite de segmente și puncte de întrerupere diferite. Ne găsim încercând să echilibrăm două obiective concurente:
- minimizați Erorile. Adică, faceți linia de regresie a fiecărui segment aproape de punctele de date observate.
- utilizați cel mai mic număr de segmente care modelează bine datele. Am putea obține întotdeauna eroare zero creând un singur segment pentru fiecare punct (sau chiar un segment pentru fiecare două puncte). Cu toate acestea, asta ar învinge întregul punct de a face o regresie; nu am învăța nimic despre relația generală dintre o marcă de timp și valoarea metrică asociată și nu am putea folosi cu ușurință rezultatul pentru interpolare sau extrapolare.
soluția noastră
folosim următorul algoritm greedy pentru problema de regresie în bucăți:
- faceți o regresie în bucăți cu N/2 segmente, unde n este numărul de observații din seriile de timp. Linia de regresie din fiecare segment este potrivită folosind regresia obișnuită a celor mai mici pătrate (OLS). Această regresie inițială în bucăți nu va avea aproape nicio eroare, dar va suprasolicita grav setul de date.
- iterativ, până când există un singur segment:
- pentru toate perechile de segmente vecine, evaluați creșterea erorii totale care ar rezulta dacă cele două segmente ar fi combinate, cele două linii de regresie ale acestora fiind înlocuite cu o singură linie de regresie.
- îmbinați perechea de segmente care ar duce la cea mai mică creștere a erorii.
- Dacă efectuarea acestei fuziuni îndeplinește criteriile noastre de oprire (definite mai jos), atunci este posibil să fi mers prea departe, fuzionând două segmente care ar trebui să rămână separate. Dacă acesta este cazul, amintiți-vă starea segmentelor înainte de îmbinarea acestei iterații.
- Dacă nicio îmbinare nu a dus la amintirea stării segmentelor din (2c) de mai sus, atunci cea mai bună soluție este un segment mare. În caz contrar, ultima stare de segment care trebuie amintită în (2C) este cea mai bună soluție.
criterii de oprire
considerăm că o îmbinare este un punct de oprire potențial dacă crește suma totală a erorilor pătrate cu mai mult decât orice îmbinare anterioară. Pentru a preveni oprirea prea devreme în cazurile în care ar trebui să existe un singur segment, nu vom considera o îmbinare ca fiind un potențial punct de oprire decât dacă duce la o creștere a erorii totale care este mai mică de 3% din eroarea totală a unei regresii cu un segment. (3% este un prag arbitrar, dar am constatat că funcționează bine în practică.) Mai jos sunt câteva exemple pentru a demonstra de ce funcționează acest criteriu de oprire.
în primul rând, să ne uităm la un set de date care a fost generat prin adăugarea de zgomot distribuit în mod normal la puncte de-a lungul unei singure linii. Algoritmul se potrivește corect doar unui singur segment prin acest set de date.
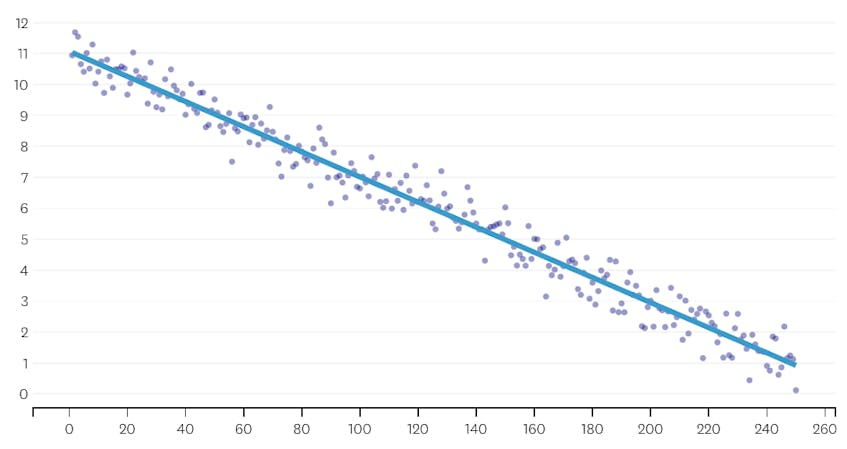
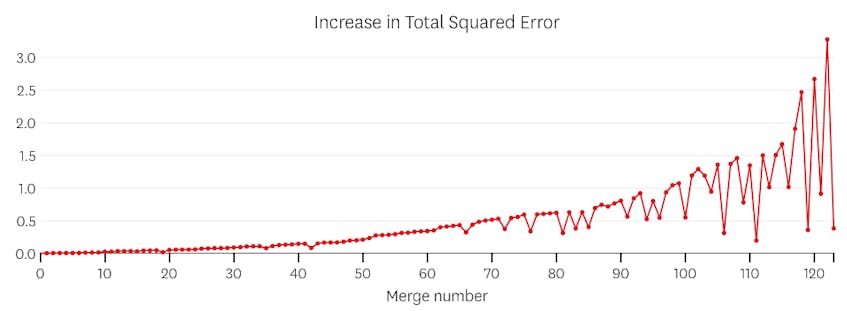
în acest caz, nicio îmbinare nu crește vreodată suma totală a erorilor pătrate cu mai mult de 3%. Prin urmare, nici o îmbinare nu este considerată un punct de oprire adecvat și folosim starea finală după ce toate fuziunile au fost executate. În graficul de mai jos, vedem că fuziunile ulterioare tind să introducă mai multe erori decât cele anterioare (ceea ce are sens, deoarece fiecare afectează mai multe puncte), dar creșterea erorii crește doar treptat pe măsură ce mai multe segmente sunt îmbinate.
în al doilea rând, să ne uităm un exemplu în cazul în care există șapte segmente distincte în setul de date.
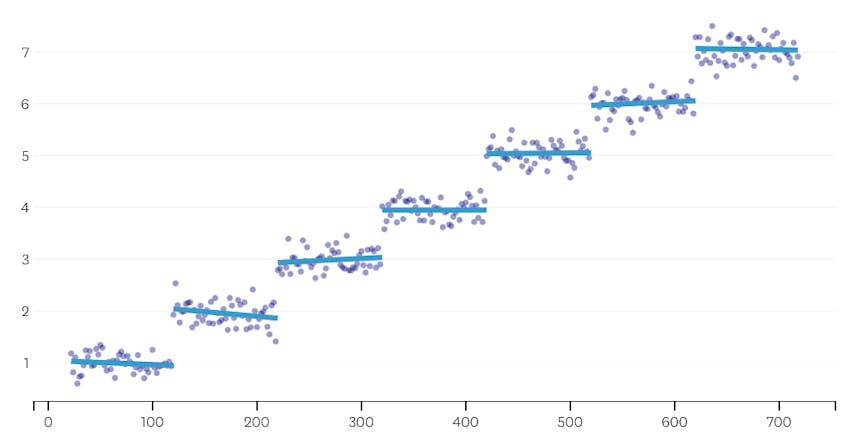
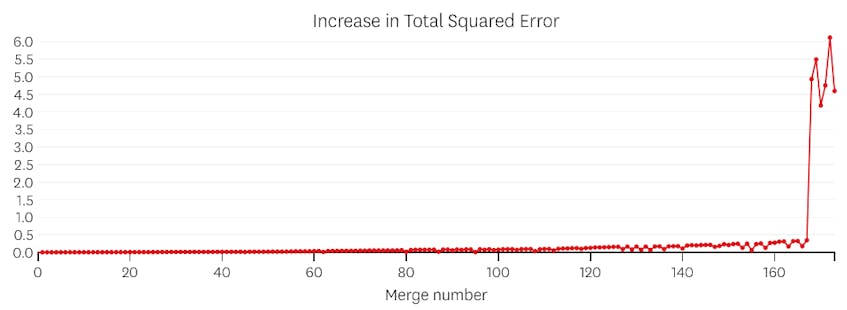
în acest caz, când ne uităm la graficul erorilor introduse de fiecare îmbinare, vedem că ultimele șase fuziuni au introdus mult mai multă eroare decât oricare dintre fuziunile anterioare. Prin urmare, algoritmul nostru a amintit starea segmentelor înainte de îmbinarea a 6-A până la ultima și a folosit-o ca soluție finală.
codul
în repo-ul Datadog/piecewise Github, veți găsi implementarea noastră Python a algoritmului. Funcția piecewise() este locul în care are loc ridicarea grea; având în vedere un set de date, acesta va returna coeficienții de locație și regresie pentru fiecare dintre segmentele montate.
de asemenea, incluse în esența este plot_data_with_regression() — o funcție de înveliș pentru complot rapid și ușor. Un exemplu rapid de modul în care acest lucru ar putea fi utilizate:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)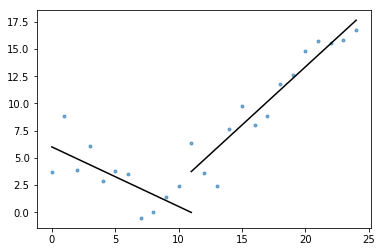
în timp ce această implementare utilizează regresia liniară OLS, același cadru poate fi adaptat pentru a rezolva problemele conexe. Prin înlocuirea erorii pătrate cu eroare absolută sau pierdere Huber, regresia poate fi robustă. Sau, o funcție de pas poate fi potrivită atribuind fiecărui segment o valoare constantă egală cu media observațiilor din domeniul său.