în acest tutorial vom explica, una dintre tehnicile emergente și proeminente de încorporare a cuvintelor numită Word2Vec propuse de Mikolov și colab. în 2013. Am colectat aceste conținuturi din diferite tutoriale și surse pentru a facilita cititorii într-un singur loc. Sper că ajută.
Word2vec este o combinație de modele utilizate pentru a reprezenta reprezentări distribuite ale cuvintelor într-un corpus C. Word2Vec (W2V) este un algoritm care acceptă corpus text ca intrare și emite o reprezentare vectorială pentru fiecare cuvânt, așa cum se arată în diagrama de mai jos:

există două arome ale acestui algoritm și anume: CCOW și Skip-Gram. Având în vedere un set de propoziții (numite și corpus) modelul se învârte pe cuvintele fiecărei propoziții și fie încearcă să folosească cuvântul curent w pentru a-și prezice vecinii (adică contextul său), această abordare se numește „Skip-Gram”, sau folosește fiecare dintre aceste contexte pentru a prezice cuvântul curent w, în acest caz metoda se numește „sac continuu de cuvinte” (CCOW). Pentru a limita numărul de cuvinte din fiecare context, se utilizează un parametru numit „dimensiunea ferestrei”.

vectorii pe care îi folosim pentru a reprezenta cuvinte se numesc încorporări de cuvinte neuronale, iar reprezentările sunt ciudate. Un lucru descrie altul, chiar dacă aceste două lucruri sunt radical diferite. Elvis Costello spunea: „a scrie despre muzică este ca și cum ai dansa despre arhitectură.”Word2vec” vectorizează ” despre cuvinte și, făcând acest lucru, face ca limbajul natural să poată fi citit de computer-putem începe să efectuăm operații matematice puternice asupra cuvintelor pentru a detecta asemănările lor.
deci, încorporarea unui cuvânt neural reprezintă un cuvânt cu numere. Este o traducere simplă, dar puțin probabilă. Word2vec este similar cu un autoencoder, care codifică fiecare cuvânt într-un vector, dar mai degrabă decât să se antreneze împotriva cuvintelor de intrare prin reconstrucție, așa cum face o mașină Boltzmann restricționată, word2vec antrenează cuvinte împotriva altor cuvinte care le înconjoară în corpusul de intrare.
face acest lucru într-unul din cele două moduri, fie folosind contextul pentru a prezice un cuvânt țintă (O metodă cunoscută sub numele de sac continuu de cuvinte sau CCOW), fie folosind un cuvânt pentru a prezice un context țintă, care se numește skip-gram. Folosim ultima metodă deoarece produce rezultate mai precise pe seturi de date mari.

când vectorul de caracteristici atribuit unui cuvânt nu poate fi utilizat pentru a prezice cu exactitate contextul cuvântului respectiv, componentele vectorului sunt ajustate. Contextul fiecărui cuvânt din corpus este profesorul care trimite semnale de eroare înapoi pentru a ajusta vectorul de caracteristici. Vectorii cuvintelor considerate similare prin contextul lor sunt împinși mai aproape prin ajustarea numerelor din vector. În acest tutorial, ne vom concentra pe modelul Skip-Gram care, spre deosebire de CCOW, consideră cuvântul central ca intrare așa cum este descris în figura de mai sus și prezice cuvintele contextuale.
Prezentare generală a modelului
am înțeles că trebuie să alimentăm o rețea neuronală ciudată cu câteva perechi de cuvinte, dar nu putem face asta folosind ca intrări caracterele reale, trebuie să găsim o modalitate de a reprezenta aceste cuvinte matematic, astfel încât rețeaua să le poată procesa. O modalitate de a face acest lucru este de a crea un vocabular al tuturor cuvintelor din textul nostru și apoi de a codifica cuvântul nostru ca vector de aceleași dimensiuni ale vocabularului nostru. Fiecare dimensiune poate fi gândită ca un cuvânt în vocabularul nostru. Deci, vom avea un vector cu toate zerourile și un 1 care reprezintă cuvântul corespunzător din vocabular. Această tehnică de codificare se numește codificare one-hot. Având în vedere exemplul nostru, dacă avem un vocabular format din cuvintele „the”, „quick”, „brown”, „fox”, „jumps”, „over”, „the” „lazy”, „dog”, cuvântul „brown” este reprezentat de acest vector: .

Modelul Skip-gram preia un corpus de text și creează un vector fierbinte pentru fiecare cuvânt. Un vector fierbinte este o reprezentare vectorială a unui cuvânt în care vectorul este dimensiunea vocabularului (cuvinte unice totale). Toate dimensiunile sunt setate la 0, cu excepția dimensiunii care reprezintă cuvântul care este folosit ca intrare în acel moment. Iată un exemplu de vector fierbinte:

intrarea de mai sus este dată unei rețele neuronale cu un singur strat ascuns.
vom reprezenta un cuvânt de intrare ca „furnici” ca un vector one-hot. Acest vector va avea 10.000 de componente (unul pentru fiecare cuvânt din vocabularul nostru) și vom plasa un „1” în poziția corespunzătoare cuvântului „furnici” și 0s în toate celelalte poziții. Ieșirea rețelei este un singur vector (de asemenea, cu 10.000 de componente) care conține, pentru fiecare cuvânt din vocabularul nostru, probabilitatea ca un cuvânt din apropiere selectat aleatoriu să fie acel cuvânt din vocabular.
în word2vec, se folosește o reprezentare distribuită a unui cuvânt. Luați un vector cu câteva sute de dimensiuni (să zicem 1000). Fiecare cuvânt este reprezentat de o distribuție a greutăților între aceste elemente. Deci, în loc de o mapare unu-la-unu între un element din vector și un cuvânt, reprezentarea unui cuvânt este răspândită pe toate elementele din vector și fiecare element din vector contribuie la definirea multor cuvinte.
dacă etichetez dimensiunile într-un vector de cuvinte ipotetic (nu există astfel de etichete pre-atribuite în algoritm, desigur), ar putea arăta cam așa:

un astfel de vector ajunge să reprezinte într-un mod abstract sensul unui cuvânt. Și după cum vom vedea în continuare, pur și simplu examinând un corpus mare este posibil să învățăm vectori de cuvinte care sunt capabili să surprindă relațiile dintre cuvinte într-un mod surprinzător de expresiv. De asemenea, putem folosi vectorii ca intrări într-o rețea neuronală. Deoarece vectorii noștri de intrare sunt unul fierbinte, înmulțirea unui vector de intrare cu matricea de greutate W1 înseamnă pur și simplu selectarea unui rând din W1.
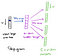

de la stratul ascuns la stratul de ieșire, a doua matrice de greutate W2 poate fi utilizată pentru a calcula un scor pentru fiecare cuvânt din vocabular, iar softmax poate fi utilizat pentru a obține distribuția posterioară a cuvintelor. Modelul skip-gram este opusul modelului CCOW. Acesta este construit cu cuvântul focus ca vector de intrare unic, iar cuvintele context țintă sunt acum la stratul de ieșire. Funcția de activare pentru stratul ascuns se ridică pur și simplu la copierea rândului corespunzător din matricea de greutăți W1 (liniară) așa cum am văzut înainte. La stratul de ieșire, Acum producem distribuții multinomiale C în loc de una singură. Obiectivul de formare este de a mimimiza eroarea de predicție însumată în toate cuvintele contextuale din stratul de ieșire. În exemplul nostru, intrarea ar fi” învățare”și sperăm să vedem („an”,” eficient”,” metodă”,” pentru”,” înalt”,” calitate”,” distribuit”,” vector”) la stratul de ieșire.
Iată arhitectura rețelei noastre neuronale.

pentru exemplul nostru, vom spune că învățăm vectori de cuvinte cu 300 de caracteristici. Deci stratul ascuns va fi reprezentat de o matrice de greutate cu 10.000 de rânduri (unul pentru fiecare cuvânt din vocabularul nostru) și 300 de coloane (unul pentru fiecare neuron ascuns). 300 de caracteristici este ceea ce Google a folosit în modelul lor publicat instruit pe setul de date Google news (îl puteți descărca de aici). Numărul de caracteristici este un „parametru hiper” pe care ar trebui doar să-l acordați aplicației dvs. (adică încercați diferite valori și vedeți ce dă cele mai bune rezultate).
dacă te uiți la rândurile acestei matrice de greutate, acestea vor fi vectorii noștri de cuvinte!

deci, scopul final al tuturor acestor lucruri este de fapt doar să învățăm această matrice de greutate a stratului ascuns-stratul de ieșire pe care îl vom arunca doar când am terminat! Vectorul de 1 x 300 de cuvinte pentru „furnici” este apoi alimentat la stratul de ieșire. Stratul de ieșire este un clasificator de regresie softmax. Mai exact, fiecare neuron de ieșire are un vector de greutate pe care îl înmulțește împotriva cuvântului vector din stratul ascuns, apoi aplică funcția exp(x) rezultatului. În cele din urmă, pentru ca ieșirile să însumeze până la 1, împărțim acest rezultat la suma rezultatelor din toate cele 10.000 de noduri de ieșire. Iată o ilustrare a calculării ieșirii neuronului de ieșire pentru cuvântul”mașină”.

dacă două cuvinte diferite au „contexte” foarte similare (adică ce cuvinte sunt susceptibile să apară în jurul lor), atunci modelul nostru trebuie să producă rezultate foarte similare pentru aceste două cuvinte. Și o modalitate prin care rețeaua poate emite predicții de context similare pentru aceste două cuvinte este dacă vectorii de cuvinte sunt similari. Deci, dacă două cuvinte au contexte similare, atunci rețeaua noastră este motivată să învețe vectori de cuvinte similari pentru aceste două cuvinte! Ta da!
fiecare dimensiune a intrării trece prin fiecare nod al stratului ascuns. Dimensiunea este înmulțită cu greutatea care o duce la stratul ascuns. Deoarece intrarea este un vector fierbinte, doar unul dintre nodurile de intrare va avea o valoare diferită de zero (și anume valoarea 1). Aceasta înseamnă că pentru un cuvânt vor fi activate doar greutățile asociate nodului de intrare cu valoarea 1, așa cum se arată în imaginea de mai sus.
deoarece intrarea în acest caz este un vector fierbinte, doar unul dintre nodurile de intrare va avea o valoare diferită de zero. Aceasta înseamnă că numai greutățile conectate la acel nod de intrare vor fi activate în nodurile ascunse. Un exemplu de ponderi care vor fi luate în considerare este prezentat mai jos pentru al doilea cuvânt din vocabular:
reprezentarea vectorială a celui de-al doilea cuvânt din Vocabular (prezentat în rețeaua neuronală de mai sus) va arăta după cum urmează, odată activat în stratul ascuns:
aceste greutăți încep ca valori aleatorii. Rețeaua este apoi instruită pentru a ajusta greutățile pentru a reprezenta cuvintele de intrare. Aici stratul de ieșire devine important. Acum, că suntem în stratul ascuns cu o reprezentare vectorială a cuvântului, avem nevoie de o modalitate de a determina cât de bine am prezis că un cuvânt se va potrivi într-un anumit context. Contextul cuvântului este un set de cuvinte într-o fereastră din jurul său, așa cum se arată mai jos:

imaginea de mai sus arată că contextul pentru vineri include cuvinte precum „pisică” și „este”. Scopul rețelei neuronale este de a prezice că „vineri” se încadrează în acest context.
activăm stratul de ieșire înmulțind vectorul pe care l-am trecut prin stratul ascuns (care a fost Vectorul fierbinte de intrare * greutăți care intră în nodul ascuns) cu o reprezentare vectorială a cuvântului context (care este Vectorul fierbinte pentru cuvântul context * greutăți care intră în nodul de ieșire). Starea stratului de ieșire pentru primul cuvânt de context poate fi vizualizată mai jos:

multiplicarea de mai sus se face pentru fiecare cuvânt în context pereche de cuvinte. Apoi calculăm probabilitatea ca un cuvânt să aparțină unui set de cuvinte contextuale folosind valorile rezultate din straturile ascunse și de ieșire. În cele din urmă, aplicăm coborârea gradientului stochastic pentru a schimba valorile greutăților pentru a obține o valoare mai dorită pentru Probabilitatea calculată.
în coborârea gradientului trebuie să calculăm gradientul funcției optimizate în punctul care reprezintă greutatea pe care o schimbăm. Gradientul este apoi utilizat pentru a alege direcția în care să faceți un pas pentru a vă deplasa către optimul local, așa cum se arată în exemplul de minimizare de mai jos.
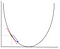
greutatea va fi modificată făcând un pas în direcția punctului optim (în exemplul de mai sus, cel mai jos punct din grafic). Noua valoare se calculează scăzând din valoarea curentă a greutății funcția derivată în punctul greutății scalate de rata de învățare. Următorul pas este utilizarea Backpropagation, pentru a regla greutățile între mai multe straturi. Eroarea care este calculată la sfârșitul stratului de ieșire este transmisă înapoi de la stratul de ieșire la stratul ascuns prin aplicarea regulii lanțului. Coborârea gradientului este utilizată pentru a actualiza greutățile dintre aceste două straturi. Eroarea este apoi ajustată la fiecare strat și trimisă înapoi. Aici este o diagramă pentru a reprezenta backpropagation:

înțelegerea folosind exemplul
Word2vec utilizează un singur strat ascuns, rețea neuronală complet conectat așa cum se arată mai jos. Neuronii din stratul ascuns sunt toți neuroni liniari. Stratul de intrare este setat pentru a avea cât mai mulți neuroni ca există cuvinte în vocabularul de formare. Dimensiunea stratului ascuns este setată la dimensionalitatea vectorilor de cuvinte rezultați. Dimensiunea stratului de ieșire este aceeași cu stratul de intrare. Astfel, dacă vocabularul pentru învățarea vectorilor de cuvinte constă din cuvinte V și N pentru a fi dimensiunea vectorilor de cuvinte, intrarea la conexiunile de strat ascunse poate fi reprezentată de matrice WI de dimensiune VxN cu fiecare rând reprezentând un cuvânt de vocabular. În același mod, conexiunile de la stratul ascuns la stratul de ieșire pot fi descrise prin matricea WO de dimensiune NxV. În acest caz, fiecare coloană a matricei WO reprezintă un cuvânt din vocabularul dat.

intrarea în rețea este codificată folosind reprezentarea” 1-out of-V”, ceea ce înseamnă că o singură linie de intrare este setată la una și restul liniilor de intrare sunt setate la zero.
să presupunem că avem un corpus de antrenament cu următoarele propoziții:
„câinele a văzut o pisică”, „câinele a urmărit pisica”, „pisica s-a urcat într-un copac”
vocabularul corpusului are opt cuvinte. Odată ordonat alfabetic, fiecare cuvânt poate fi referit prin indexul său. Pentru acest exemplu, rețeaua noastră neuronală va avea opt neuroni de intrare și opt neuroni de ieșire. Să presupunem că decidem să folosim trei neuroni în stratul ascuns. Aceasta înseamnă că WI și WO vor fi 8 matrice 3 și 3 matrice 8, respectiv. Înainte de începerea antrenamentului, aceste matrice sunt inițializate la valori aleatorii mici, așa cum este de obicei în antrenamentul rețelei neuronale. Doar de dragul ilustrației, să presupunem că WI și WO vor fi inițializate la următoarele valori:

să presupunem că dorim ca rețeaua să învețe relația dintre cuvintele” pisică „și”urcat”. Adică, rețeaua ar trebui să arate o mare probabilitate de „urcat” atunci când „pisica” este introdusă în rețea. În terminologia de încorporare a cuvintelor, cuvântul” pisică „este denumit cuvântul de context, iar cuvântul” urcat ” este denumit cuvântul țintă. În acest caz, vectorul de intrare X va fi t. observați că numai a doua componentă a vectorului este 1. Acest lucru se datorează faptului că cuvântul de intrare este „pisică”, care deține poziția numărul doi în lista sortată de cuvinte corpus. Având în vedere că cuvântul țintă este „urcat”, vectorul țintă va arăta ca t. cu vectorul de intrare reprezentând „pisică”, ieșirea la neuronii stratului ascuns poate fi calculată ca:
Ht = XtWI =
nu ar trebui să ne surprindă faptul că vectorul H al ieșirilor neuronale ascunse imită greutățile celui de-al doilea rând de matrice WI din cauza 1-out-of-Vreprezentare. Deci, funcția de intrare a conexiunilor strat ascunse este, în principiu pentru a copia vectorul cuvânt de intrare la strat ascuns. Efectuând manipulări similare pentru stratul de ieșire ascuns, vectorul de activare pentru neuronii stratului de ieșire poate fi scris ca
HtWO =
deoarece, scopul este produce probabilități pentru cuvintele din stratul de ieșire, Pr(wordk|wordcontext) pentru k = 1, V, pentru a reflecta următoarea lor relație de cuvânt cu cuvântul context la intrare, avem nevoie de suma ieșirilor neuronilor din stratul de ieșire pentru a adăuga la unul. Word2vec realizează acest lucru prin conversia valorilor de activare ale neuronilor stratului de ieșire în probabilități folosind funcția softmax. Astfel, ieșirea neuronului k este calculată prin următoarea expresie în care activarea (n) reprezintă valoarea de activare a neuronului stratului de ieșire n:
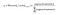
astfel, probabilitățile pentru opt cuvinte din corpus sunt:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
probabilitatea cu caractere aldine este pentru cuvântul țintă ales”urcat”. Având în vedere vectorul țintă t, vectorul de eroare pentru stratul de ieșire este ușor calculat prin scăderea vectorului de probabilitate din vectorul țintă. Odată ce eroarea este cunoscută, greutățile din matricile WO și WI pot fi actualizate folosind backpropagation. Astfel, formarea poate continua prin prezentarea diferitelor perechi de cuvinte context-țintă din corpus. Acesta este modul în care Word2vec învață relațiile dintre cuvinte și în acest proces dezvoltă reprezentări vectoriale pentru cuvintele din corpus.
ideea din spatele word2vec este de a reprezenta cuvinte printr-un vector de numere reale de dimensiune d. Prin urmare, a doua matrice este reprezentarea acestor cuvinte. Linia i a acestei matrice este reprezentarea vectorială a cuvântului I. Să presupunem că în exemplul dvs. aveți 5 cuvinte : , atunci primul vector înseamnă că luați în considerare cuvântul „cal” și astfel reprezentarea „calului” este . În mod similar, este reprezentarea cuvântului „Leu”.

din câte știu, nu există niciun „sens uman” specific pentru fiecare dintre numerele din aceste reprezentări. Un număr nu reprezintă dacă cuvântul este un verb sau nu, un adjectiv sau nu… sunt doar greutățile pe care le schimbați pentru a vă rezolva problema de optimizare pentru a învăța reprezentarea cuvintelor voastre.
o diagramă vizuală cea mai bună elaborare a procesului de multiplicare a matricei word2vec este prezentată în figura următoare:

prima matrice reprezintă vectorul de intrare într-un format fierbinte. A doua matrice reprezintă greutățile sinaptice de la neuronii stratului de intrare la neuronii stratului ascuns. Observați mai ales colțul din stânga sus unde matricea stratului de intrare este înmulțită cu matricea de greutate. Acum uită-te în dreapta sus. Această matrice multiplicare inputlayer Dot-produs cu greutăți transpune este doar un mod la îndemână pentru a reprezenta rețeaua neuronală din dreapta sus.
prima parte reprezintă cuvântul de intrare ca un vector fierbinte, iar cealaltă matrice reprezintă greutatea pentru conectarea fiecăruia dintre neuronii stratului de intrare la neuronii stratului ascuns. Pe măsură ce Word2Vec se antrenează, se întoarce (folosind coborârea gradientului) în aceste greutăți și le schimbă pentru a oferi reprezentări mai bune ale cuvintelor ca vectori. Odată ce antrenamentul este realizat, utilizați numai această matrice de greutate, luați pentru a spune ‘câine’ și înmulțiți-o cu matricea de greutate îmbunătățită pentru a obține reprezentarea vectorială a ‘câine’ într-o dimensiune = nu de neuroni ascunși. În diagramă, numărul de neuroni ascunși ai stratului este de 3.
pe scurt, modelul Skip-gram inversează utilizarea cuvintelor țintă și context. În acest caz, cuvântul țintă este alimentat la intrare, stratul ascuns rămâne același, iar stratul de ieșire al rețelei neuronale este reprodus de mai multe ori pentru a găzdui numărul ales de cuvinte contextuale. Luând exemplul „pisică” și „copac” ca cuvinte contextuale și „urcat” ca cuvânt țintă, vectorul de intrare în modelul skim-gram ar fi t, în timp ce cele două straturi de ieșire ar avea t și respectiv t ca vectori țintă. În locul producerii unui vector de probabilități, doi astfel de vectori ar fi produși pentru exemplul curent. Vectorul de eroare pentru fiecare strat de ieșire este produs în modul discutat mai sus. Cu toate acestea, vectorii de eroare din toate straturile de ieșire sunt însumați pentru a regla greutățile prin backpropagare. Acest lucru asigură că matricea de greutate WO pentru fiecare strat de ieșire rămâne identică pe tot parcursul antrenamentului.
avem nevoie de câteva modificări suplimentare la modelul de bază skip-gram, care sunt importante pentru a face posibilă instruirea. Rularea coborâre gradient pe o rețea neuronală că mare va fi lent. Și pentru a înrăutăți lucrurile, aveți nevoie de o cantitate imensă de date de antrenament pentru a regla atât de multe greutăți și pentru a evita supra-montarea. milioane de greutăți ori miliarde de probe de formare înseamnă că formarea acestui model va fi o fiară. Pentru aceasta, autorii au propus două tehnici numite subeșantionare și eșantionare negativă în care cuvintele nesemnificative sunt eliminate și doar un eșantion specific de greutăți sunt actualizate.
Mikolov și colab. utilizați, de asemenea, o abordare simplă de subeșantionare pentru a contracara dezechilibrul dintre cuvintele rare și frecvente din setul de antrenament (de exemplu, „in”, „the” ȘI „a” oferă o valoare informațională mai mică decât cuvintele rare). Fiecare cuvânt din setul de antrenament este aruncat cu probabilitate P (wi) unde

F (wi) este frecvența cuvântului wi și t este un prag ales, de obicei în jur de 10-5.
detalii de implementare
Word2vec a fost implementat în diferite limbi, dar aici ne vom concentra în special pe Java adică., DeepLearning4j , darks-învățare și python . Diferiți algoritmi neuronali net au fost implementați în DL4j, codul este disponibil pe GitHub.
pentru a-l implementa în DL4j, vom parcurge câțiva pași dați după cum urmează:
a) Word2Vec Setup
creați un nou proiect în IntelliJ folosind Maven. Apoi specificați proprietățile și dependențele în POM.fișier xml în directorul rădăcină al proiectului.
b) încărcați date
acum creați și denumiți o nouă clasă în Java. După aceea, veți lua propozițiile brute în dvs.fișier txt, traversați-le cu iteratorul dvs. și supuneți-le unui fel de pre-procesare, cum ar fi conversia tuturor cuvintelor în litere mici.
string filePath = New ClassPathResource(„raw_sentences.txt”).getFile ().getAbsolutePath ();
log.info („Load & vectorize propoziții….”);
// Strip spațiu alb înainte și după pentru fiecare linie
SentenceIterator iter = New BasicLineIterator (filePath);
dacă doriți să încărcați un fișier text pe lângă propozițiile furnizate în exemplul nostru, ați face acest lucru:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) tokenizarea datelor
Word2vec trebuie să fie hrănite cuvinte, mai degrabă decât propoziții întregi, astfel încât următorul pas este de a tokenize datele. A tokeniza un text înseamnă a-l împărți în unitățile sale atomice, creând un nou simbol de fiecare dată când lovești un spațiu alb, de exemplu.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) formarea modelului
acum, că datele sunt gata, puteți configura Word2vec neural net și feed în jetoane.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
această configurație acceptă mai mulți hiperparametri. Câteva necesită o explicație:
- dimensiune lot este cantitatea de cuvinte pe care le procesați la un moment dat.
- minWordFrequency este numărul minim de ori un cuvânt trebuie să apară în corpus. Aici, dacă apare mai puțin de 5 ori, nu este învățat. Cuvintele trebuie să apară în mai multe contexte pentru a afla caracteristici utile despre ele. În corpii foarte mari, este rezonabil să ridicați minimul.
- useAdaGrad — Adagrad creează un gradient diferit pentru fiecare caracteristică. Aici nu suntem preocupați de asta.
- layerSize specifică numărul de caracteristici din cuvântul vector. Aceasta este egală cu numărul de dimensiuni din caracteristicispațiu. Cuvintele reprezentate de 500 de caracteristici devin puncte într-un spațiu de 500 de dimensiuni.
- learningRate este dimensiunea pasului pentru fiecare actualizare a coeficienților, deoarece cuvintele sunt repoziționate în spațiul feature.
- minLearningRate este podeaua pe rata de învățare. Rata de învățare se descompune pe măsură ce numărul de cuvinte pe care le antrenezi scade. Dacă rata de învățare se micșorează prea mult, învățarea rețelei nu mai este eficientă. Acest lucru menține coeficienții în mișcare.
- itera spune net ce lot de setul de date este de formare pe.
- tokenizer se hrănește cuvintele din lotul curent.
- vec.fit () spune net configurat pentru a începe formarea.
e) evaluarea modelului, folosind Word2vec
următorul pas este să evaluați calitatea vectorilor de caracteristici.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
linia vec.similarity("word1","word2") va returna similitudinea cosinusului celor două cuvinte pe care le introduceți. Cu cât este mai aproape de 1, cu atât rețeaua percepe mai mult aceste cuvinte (a se vedea exemplul Suedia-Norvegia de mai sus). De exemplu:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
cu vec.wordsNearest("word1", numWordsNearest), cuvintele imprimate pe ecran vă permit să globul ocular dacă net a grupat cuvinte similare semantic. Puteți seta numărul de cuvinte cele mai apropiate dorite cu al doilea parametru al wordsNearest. De exemplu:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec în Java în http://deeplearning4j.org/word2vec.html
7) Word2Vec și Doc2Vec în Python în genism http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html