min artikel om forskellen mellem KLASSEVARIABLER og efter variabler i SAS fokuserede på SAS analytiske procedurer. BY-erklæringen er dog også nyttig i SAS-DATATRINNET, hvor den bruges til at flette datasæt og til at analysere data på gruppeniveau. Når du bruger sætningen by i DATATRINNET, opretter DATATRINNET to midlertidige indikatorvariabler for hver variabel i sætningen BY. Navnene på disse variabler er først.variabel og sidste.variabel, hvor variabel er navnet på en variabel i by-sætningen. For eksempel, hvis du bruger udsagnet efter køn, er navnene på indikatorvariablerne først.Køn og sidst.Sex.
denne artikel giver flere eksempler på at bruge den første.variabel og sidste.variabel indikatorvariabler til Gruppeanalyse i SAS-DATATRINNET.Det første eksempel viser, hvordan man beregner tællinger og kumulative beløb for hver gruppe. Det andet eksempel viser, hvordan man beregner tiden mellem det første og sidste besøg af en patient på en klinik samt ændringen i en målt mængde mellem det første og sidste besøg.gruppebehandling i DATATRINNET er en grundlæggende operation, der hører hjemme i hver SAS-programmørs værktøjskasse.
Brug først. og sidst. variabler for at finde tælle størrelsen af grupper
det første eksempel bruger data fra Sashelp.Hjertedatasæt, som indeholder data for 5.209 patienter i en medicinsk undersøgelse af hjertesygdomme. Dataene distribueres med SAS. Følgende DATATRIN udtrækker variablerne Smoking_Status og vægt og sorterer dataene med variablen Smoking_Status:
proc sortere data=Sashelp.Hjerte (holde=Rygning_status vægt) ud=hjerte; ved Rygning_status; løb;
da dataene er sorteret efter variablen Smoking_Status, kan du bruge den første.Smoking_Status og sidste.Smoking_status midlertidige variabler til at tælle antallet af observationer i hvert niveau af smoking_status-variablen. (PROC beregner de samme oplysninger, men kræver ikke sorterede data.) Når du bruger sætningen by Smoking_Status, opretter DATATRINNET automatisk det første.Smoking_Status og sidste.Smoking_status indikator variabler. Som navnet antyder, den første.Smoking_status-variablen har værdien 1 for den første observation i hver efter gruppe og værdien 0 ellers.(Mere korrekt er værdien 1 for den første post og for poster, for hvilke variablen Smoking_Status er anderledes end den var for den forrige post.) Tilsvarende den sidste.Smoking_status indikator variabel har værdien 1 For Den Sidste observation i hver efter gruppe og 0 ellers.
følgende DATATRIN definerer en variabel med navnet Count og initialiserer Count=0 i begyndelsen af hver gruppe. For hver observation i efter-gruppen øges Tællevariablen med 1. Når den sidste post i hver gruppe læses, skrives denne post til Tælledatasættet.
data Count; sæt hjerte; / * data er sorteret efter Smoking_Status * / af Smoking_Status; / * opretter automatisk indikator Vars * / hvis først.Smoking_Status tæl derefter = 0; / * Initialiser optælling i begyndelsen af hver efter gruppe */ Count + 1; / * increment Count for hver post */ hvis sidst.Smoking_Status; / * output kun den sidste post af hver efter gruppe * / Kør; proc print data=Count noobs; format Count comma10.;var Smoking_Status Count; løb;
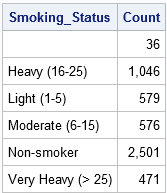
den samme teknik gør det muligt at akkumulere værdier af en variabel i en gruppe. For eksempel kan du akkumulere den samlede vægt af alle patienter i hver rygegruppe ved hjælp af følgende udsagn:
hvis først.Rygning_status derefter cum = 0; cum vægt + vægt;
den samme teknik kan bruges til at akkumulere indtægter fra forskellige kilder, såsom afdelinger, butikker eller regioner.
Brug først. og sidst. variabler til beregning af behandlingsvarighed
en anden almindelig anvendelse af den første.variabel og sidste.variabel indikator variabler er at bestemme længden af tid mellem en patients første besøg og hans sidste besøg. Overvej følgende DATATRIN, der definerer datoer og vægte for fire mandlige patienter, der besøgte en klinik som en del af et vægttabsprogram:
data patienter;informat Dato date7.; format Dato dato7. Patient Med 4.;input patient Dato vægt @@;datalines;1021 04Jan16 302 1042 06Jan16 2851053 07Jan16 325 1063 11jan16 2911053 01feb16 299 1021 01Feb16 2881063 09Feb16 283 1042 16feb16 2791021 07mar16 280 1063 09mar16 2721042 28mar16 272 1021 04apr16 2731063 20apr16 270 1053 28apr16 2891053 13may16 295 1063 31may16 269;
for disse data kan du sortere efter patient-ID og efter besøgsdato. Efter sortering indeholder den første post for hver patient det første besøg på klinikken, og den sidste post indeholder det sidste besøg. Du kan trække patientens vægt for disse datoer for at bestemme, hvor meget patienten fik eller tabte under forsøget. Du kan også bruge INTCK-funktionen til at beregne den forløbne tid mellem besøg. Hvis du vil måle tid i dage, kan du blot trække datoerne fra, men INTCK-funktionen giver dig mulighed for at beregne varighed med hensyn til år, måneder, uger og andre tidsenheder.
proc Sorter data=patienter;efter PatientID Dato; løb; data vægttab; sæt patienter; ved PatientID; Bevar startdato startvægt; / * Bevar startværdierne * / hvis først.PatientID derefter gøre; startDate = Dato; startvægt = vægt; / * husk de oprindelige værdier * / slut; hvis sidst.PatientID gør derefter; slutdato = Dato; slutvægt = vægt; elapsedDays = intck('dag', startdato, slutdato); /* forløbet tid (i dage) */ vægttab = startvægt - slutvægt; /* vægttab */ gennemsnitsvægt = vægttab / elapsedDays; /* gennemsnitligt vægttab pr. dag */ output; /* output kun den sidste rekord i hver gruppe */ slut;løb; proc print noobs; var PatientID elapsedDays startvægt slutvægt vægttab avgvægttab;løb;
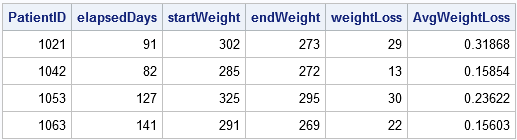
outputdatasættet opsummerer hver patients aktiviteter på klinikken, inklusive hans gennemsnitlige vægttab og varigheden af hans behandling.
nogle programmører mener, at den første.variabel og sidste.variable indikatorvariabler kræver, at dataene sorteres, men det er ikke sandt. De midlertidige variabler oprettes, når du bruger en by-sætning i et DATATRIN. Du kan bruge indstillingen NOTSORTED i sætningen by til at behandle poster uanset sorteringsrækkefølgen.
oversigt
sammenfattende opretter by-sætningen i DATATRINNET automatisk to indikatorvariabler. Du kan bruge variablerne til at bestemme den første og sidste post i hver efter gruppe. Typisk den første.variabel indikator bruges til at initialisere sammenfattende statistik og til at huske de indledende værdier for måling.Den sidste.variabel indikator bruges til at udsende resultatet af beregningerne, som ofte inkluderer enkle beskrivende statistikker såsom en sum, forskel, maksimum, minimum eller gennemsnitsværdier.
gruppebehandling i DATATRINNET er et fælles emne, der præsenteres på SAS-konferencer. Nogle forfattere bruger FIRST.BY og LAST.BY som navnet på indikatorvariablerne. For yderligere læsning anbefaler jeg papiret “kraften i By-erklæringen” (Choate and Dunn, 2007). SAS leverer også flere prøver om behandling efter gruppe i SAS-DATATRINNET, herunder følgende:
- bær ikke-manglende værdier ned en efter gruppe
- brug af grupper til at transponere data fra lang til bred
- Vælg et specificeret antal observationer fra toppen af hver efter gruppe
Tags Kom godt i gang SAS programmering