クラス変数とSASでの変数の違いについての私の記事は、SAS分析手順に焦点を当てました。 ただし、BY文は、データセットをマージしたり、グループレベルでデータを分析したりするために使用するSAS DATAステップでも役立ちます。 DATAステップでBY文を使用すると、DATAステップではBY文の各変数に対して2つの一時標識変数が作成されます。 これらの変数の名前が最初です。変数と最後。ここで、variableはBYステートメント内の変数の名前です。 たとえば、Sexで文を使用する場合、指標変数の名前が最初になります。セックスと最後。セックス
この記事では、最初のものを使用するいくつかの例を示します。変数と最後。SAS DATAステップでのグループ別分析のための変数indicatorvariables。最初の例では、グループごとにカウントと累積金額を計算する方法を示しています。 2番目の例は、患者の診療所への最初の訪問と最後の訪問の間の時間と、最初の訪問と最後の訪問の間の測定量の変化を計算する方法を示しています。DATAステップでのグループ別処理は、すべてのSASプログラマのツールボックスに属する基本的な操作です。
最初に使用します。 そして最後。 グループのサイズをカウントする変数
最初の例では、Sashelpからのデータを使用します。心臓病の医学的研究における5,209人の患者のデータが含まれている心臓データセット。 データはSASと共に配布されます。 次のデータステップでは、Smoking_Status変数とWeight変数を抽出し、Smoking_Status変数でデータを並べ替えます:
proc sort data=Sashelp.Heart(keep=Smoking_Status Weight)out=Heart;By Smoking_Status;run;
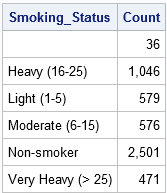
データはSmoking_Status変数でソートされるため、最初の変数を使用できます。Smoking_statusとLAST.Smoking_Status変数の各レベルの観測値の数をカウントするための一時変数。 (PROC FREQは同じ情報を計算しますが、ソートされたデータは必要ありません。BY Smoking_Status文を使用すると、DATAステップで最初の文が自動的に作成されます。Smoking_statusとLAST.Smoking_statusインジケータ変数。 その名前が示すように、最初のもの。Smoking_status変数は、各グループの最初の観測値の値1を持ち、それ以外の値は0を持ちます。(より正確には、最初のレコードとSmoking_Status変数が前のレコードとは異なるレコードの値は1です。)同様に、最後の。Smoking_statusインジケータ変数は、各グループの最後の観測値の値1を持ち、それ以外の場合は0を持ちます。
次のDATAステップでは、Countという名前の変数を定義し、各BY groupの先頭にCount=0を初期化します。 BYグループ内のすべての観測値に対して、Count変数は1ずつ増分されます。 各BYグループの最後のレコードが読み取られると、そのレコードがCountデータ・セットに書き込まれます。
data Count;set Heart;/*データはSmoking_Statusによってソートされます*/Smoking_Statusによって;/*インディケータ変数を自動的に作成します*/最初の場合。Smoking_status then Count=0;/*グループごとにそれぞれの先頭でカウントを初期化*/Count+1;/*各レコードのカウントをインクリメント*/IF LAST。Smoking_status;/*各グループの最後のレコードのみを出力します*/run;proc print data=Count noobs;Format Count comma10.;var Smoking_Status Count;run;
同じ手法を使用すると、グループ内の変数の値を累積することができます。 たとえば、次のステートメントを使用して、各喫煙グループのすべての患者の総体重を累積することができます:
最初の場合。Smoking_statusその後cumWt=0;cumWt+Weight;
これと同じ手法を使用して、部門、店舗、地域などのさまざまなソースからの収益を蓄積できます。
最初に使用します。 そして最後。 治療期間を計算する変数
最初の別の一般的な使用。変数と最後。変数インジケータ変数は、患者の最初の訪問と彼の最後の訪問の間の時間の長さを決定することです。 体重減少プログラムの一環として診療所を訪問した4人の男性患者の日付と体重を定義する次のデータステップを考えてみましょう。:
データ患者;情報提供日付date7.;フォーマット日付date7. 患者番号Z4。;input PatientID Date Weight@@;datalines;1021 04jan16 302 1042 06jan16 2851053 07jan16 325 1063 11jan16 2911053 01feb16 299 1021 01feb16 2881063 09feb16 283 1042 16feb16 2791021 07Mar16 280 1063 09mar16 2721042 28mar16 272 1021 04apr16 2731063 20apr16 270 1053 28apr16 2891053 13may16 295 1063 31may16 269;
これらのデータについては、患者IDと訪問日で並べ替えることができます。 ソート後、各患者の最初のレコードには診療所への最初の訪問が含まれ、最後のレコードには最後の訪問が含まれます。 これらの日付の患者の体重を差し引いて、試験中に患者がどれだけ得られたか、または失われたかを判断できます。 また、INTCK関数を使用して、訪問間の経過時間を計算することもできます。 日単位で時間を測定する場合は、単に日付を減算することができますが、INTCK関数を使用すると、年、月、週、およびその他の時間単位で期間を計算できます。
proc sort data=Patients;by PatientID Date;run;data weightLoss;set Patients;BY PatientID;retain startDate startWeight;/*開始値を保持します*/最初の場合。患者さんは、その後、; startDate=Date;startWeight=Weight;/*初期値を覚えています*/end;最後の場合。PatientID then do;endDate=Date;endWeight=Weight;elapsedDays=intck('day',startDate,endDate);/*経過時間(日単位)*/weightLoss=startWeight-endWeight;/*減量*/AvgWeightLoss=weightLoss/elapsedDays;/*一日あたりの平均減量*/output;/*各グループの最後のレコードのみを出力*/end;run;proc print noobs;var PatientID elapsedDays startWeight endWeight weightLoss avgweightloss;実行;
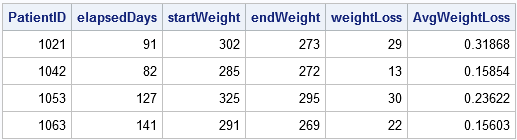
出力データセットは、彼の平均体重減少と彼の治療期間を含む診療所での各患者の活動を要約します。
いくつかのプログラマは、最初のと思います。変数と最後。変数インジケーター変数では、データをソートする必要がありますが、それは当てはまりません。 一時変数は、DATAステップでBY文を使用するたびに作成されます。 BYステートメントでNOTSORTEDオプションを使用すると、並べ替え順序に関係なくレコードを処理できます。
Summary
summaryでは、DATAステップのBYステートメントにより、2つのインジケーター変数が自動的に作成されます。 変数を使用して、グループごとに各レコードの最初と最後のレコードを決定できます。 典型的には最初のものです。変数インジケータは、要約統計を初期化し、測定の初期値を記憶するために使用されます。最後。変数インジケータは、多くの場合、このような合計、差、最大値、最小値、または平均値などの単純な記述統計を含む計算の結果を出力するために使用されます。
DATAステップでのグループ別処理は、SAS会議で提示される一般的なトピックです。 いくつかの著者が使用しますFIRST.BY とLAST.BY 指標変数の名前として。 さらに読むために、私は論文”THE Power of THE By Statement”(Choate and Dunn、2007)をお勧めします。 また、SASでは、SAS DATAステップでのグループ別処理に関するいくつかのサンプルも提供しています。:
- 欠損値以外の値をグループ別に搬送する
- グループ別に使用して、データをlongからwideに転置する
- 各グループ別の先頭から指定した数の観測値を選択する
タグはじめにSASプログラミング