min artikkel om forskjellen MELLOM KLASSEVARIABLER og variabler i SAS fokuserte PÅ SAS analytiske prosedyrer. BY-setningen er imidlertid også nyttig i SAS-datatrinnet der DEN brukes til å slå sammen datasett og analysere data på gruppenivå. NÅR DU bruker BY-setningen I datatrinnet, oppretter datatrinnet to midlertidige indikatorvariabler for hver variabel I by-setningen. Navnene på disse variablene ER FØRST.variabelt OG SIST.variabel, hvor variabel er navnet på en variabel I BY-setningen. For eksempel, hvis du bruker uttalelsen Etter Kjønn, er navnene PÅ indikatorvariablene FØRST.Sex OG SIST.Sex.
Denne artikkelen gir flere eksempler på bruk AV DEN FØRSTE.variabelt OG SIST.variable indikatorvariabler FOR gruppeanalyse i SAS-datatrinnet.Det første eksemplet viser hvordan du beregner antall og kumulative beløp FOR hver gruppe. Det andre eksemplet viser hvordan man beregner tiden mellom første og siste besøk av en pasient til en klinikk, samt endringen i en målt mengde mellom første og siste besøk.GRUPPEBEHANDLING i datatrinnet er en grunnleggende operasjon som tilhører HVER SAS programmers verktøykasse.
Bruk FØRST. OG SIST. variabler for å finne telle størrelsen på grupper
det første eksemplet bruker data fra Sashelp.Heart data set, som inneholder data for 5209 pasienter i en medisinsk studie av hjertesykdom. Dataene distribueres med SAS. Følgende datatrinn trekker Ut Variablene Smoking_Status og Vekt og sorterer dataene etter Variabelen Smoking_Status:
proc sorter data=Sashelp.Hjerte (hold=Smoking_Status Vekt) ut=Hjerte; Ved Smoking_Status; kjør;
fordi dataene er sortert Etter Smoking_Status-variabelen, kan DU bruke DEN FØRSTE.Smoking_Status OG SISTE.Smoking_Status midlertidige variabler for å telle antall observasjoner i hvert nivå Av Smoking_Status variabelen. (PROC FREQ beregner den samme informasjonen, men krever ikke sorterte data.)NÅR du bruker by Smoking_Status-setningen, oppretter datatrinnet automatisk DEN FØRSTE.Smoking_Status OG SISTE.Smoking_Status indikator variabler. Som navnet antyder, DEN FØRSTE.Smoking_Status-variabelen har verdien 1 for den første observasjonen i hver GRUPPE OG verdien 0 ellers.(Mer korrekt er verdien 1 for den første posten og for poster der Smoking_Status-variabelen er annerledes enn den var for den forrige posten.) Tilsvarende, DEN SISTE.Smoking_Status indikatorvariabel har verdien 1 for den siste observasjonen I hver GRUPPE OG 0 ellers.
FØLGENDE datatrinn definerer en variabel kalt Antall og initialiserer Antall=0 i begynnelsen AV hver GRUPPE. For hver observasjon I ETTER-gruppen økes tellevariabelen med 1. Når den siste posten i hver GRUPPE leses, skrives denne posten til telledatasettet.
data Teller; sett Hjerte; /* data er sortert Etter Smoking_Status * / Av Smoking_Status; / * oppretter automatisk indikator vars * / hvis FØRST.Smoking_Status Da Count = 0; / * initialiser Teller i begynnelsen av hver av gruppe * / Count + 1; / * økning Teller for hver post * / hvis SIST.Smoking_Status; / * output bare den siste posten av hver av gruppe * / run; proc print data=Count noobs; format Count comma10.; Var Smoking_Status Count; kjør;
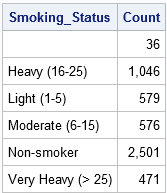
med samme teknikk kan du akkumulere verdier for en variabel i en gruppe. For eksempel kan du samle totalvekten til alle pasienter i hver røykegruppe ved å bruke følgende uttalelser:
hvis FØRST.Smoking_Status deretter cumWt = 0; cumWt + Vekt;
den samme teknikken kan brukes til å samle inntekter fra ulike kilder, for eksempel avdelinger, butikker eller regioner.
Bruk FØRST. OG SIST. variabler for å beregne behandlingsvarighet
En annen vanlig bruk av DEN FØRSTE.variabelt OG SIST.variable indikatorvariabler er å bestemme hvor lang tid mellom pasientens første besøk og hans siste besøk. Vurder FØLGENDE data trinn, som definerer datoer og vekter for fire mannlige pasienter som besøkte en klinikk som en del av et vekttap program:
Data Pasienter;informat Dato date7.; format Dato date7. PatientID Z4.;input PatientID Dato Vekt @@;datalinjer;1021 04Jan16 302 1042 06Jan16 2851053 07Jan16 325 1063 11jan16 2911053 01Feb16 299 1021 01Feb16 2881063 09Feb16 283 1042 16Feb16 2791021 07mar16 280 1063 09mar16 2721042 28mar16 272 1021 04apr16 2731063 20apr16 270 1053 28apr16 2891053 13mai16 295 1063 31mai16 269;
for disse dataene kan du sortere etter pasient-ID og dato for besøk. Etter sortering inneholder den første posten for hver pasient det første besøket i klinikken, og den siste posten inneholder det siste besøket. Du kan trekke pasientens vekt for disse datoene for å finne ut hvor mye pasienten fått eller tapt under rettssaken. DU kan også bruke INTCK-funksjonen til å beregne medgått tid mellom besøkene. HVIS du vil måle tid i dager, kan du bare trekke datoene, MEN INTCK-funksjonen lar deg beregne varighet når det gjelder år, måneder, uker og andre tidsenheter.
proc sorter data=Pasienter; Etter PatientID Dato; løp; data vekttap; sett Pasienter; etter PatientID; behold startdato startvekt; / * BEHOLD startverdiene * / if FØRST.PatientID deretter gjøre; startDate = Dato; startWeight = Vekt; / * husk de opprinnelige verdiene * / end; HVIS SIST.PatientID da gjøre; endDate = Dato; endWeight = Vekt; elapsedDays = intck('dag', startdato, sluttdato); /* medgått tid (i dager) */ vekttap = startvekt - endWeight; /* vekttap */ AvgWeightLoss = vekttap / elapsedDays; /* gjennomsnittlig vekttap per dag */ utgang; /* utgang bare den siste posten i hver gruppe */ end;kjøre; proc print noobs; var PatientID elapsedDays startvekt endvekt vekttap avgweightloss;kjøre;
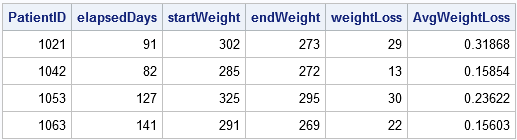
utgangsdatasettet oppsummerer hver pasients aktiviteter på klinikken, inkludert hans gjennomsnittlige vekttap og varigheten av behandlingen.
noen programmerere tror AT DEN FØRSTE.variabelt OG SIST.variable indikatorvariabler krever at dataene sorteres, men det er ikke sant. De midlertidige variablene opprettes når DU bruker EN BY-setning i et datatrinn. DU kan bruke ALTERNATIVET NOTSORTED PÅ by-setningen til å behandle poster uavhengig av sorteringsrekkefølgen.
Sammendrag
i sammendrag oppretter BY-setningen i datatrinnet automatisk to indikatorvariabler. Du kan bruke variablene til å bestemme den første og siste posten I hver GRUPPE. Typisk DEN FØRSTE.variabel indikator brukes til å initialisere sammendragsstatistikk og å huske de opprinnelige måleverdiene.DEN SISTE.variabel indikator brukes til å skrive ut resultatet av beregningene, som ofte inkluderer enkel beskrivende statistikk som en sum, forskjell, maksimum, minimum eller gjennomsnittsverdier.
gruppebehandling i datatrinnet er et vanlig tema som presenteres på SAS-konferanser. Noen forfattere bruker FIRST.BY og LAST.BY som navnet på indikatorvariablene. For videre lesing anbefaler jeg papiret «THE Power OF THE By Statement» (Choate og Dunn, 2007). SAS gir også flere eksempler PÅ GRUPPEBEHANDLING i SAS-datatrinnet, inkludert følgende:
- Bære ikke-manglende verdier ned EN BY-Gruppe
- Bruk av grupper til å transponere data fra lang til bred
- Velg et spesifisert antall observasjoner fra toppen av HVER BY-Gruppe
Tagger Komme I GANG SAS Programmering