Mein Artikel über den Unterschied zwischen Klassenvariablen und BY-Variablen in SAS konzentrierte sich auf SAS-Analyseverfahren. Die BY-Anweisung ist jedoch auch im SAS-Datenschritt nützlich, wo sie zum Zusammenführen von Datensätzen und zum Analysieren von Daten auf Gruppenebene verwendet wird. Wenn Sie die BY-Anweisung im Datenschritt verwenden, erstellt der Datenschritt zwei temporäre Indikatorvariablen für jede Variable in der BY-Anweisung. Die Namen dieser Variablen stehen an ERSTER Stelle.variabel und ZULETZT.variable, wobei variable der Name einer Variablen in der BY-Anweisung ist. Wenn Sie beispielsweise die Anweisung NACH Geschlecht verwenden, stehen die Namen der Indikatorvariablen an ERSTER Stelle.Sex und ZULETZT.Sex.
Dieser Artikel enthält einige Beispiele für die Verwendung des ERSTEN.variabel und ZULETZT.variable indicatorvariables für die Gruppenanalyse im SAS-Datenschritt.Das erste Beispiel zeigt, wie Zählungen und kumulierte Beträge für jede Gruppe berechnet werden. Das zweite Beispiel zeigt, wie die Zeit zwischen dem ersten und dem letzten Besuch eines Patienten in einer Klinik sowie die Änderung einer Messgröße zwischen dem ersten und dem letzten Besuch berechnet werden.Die gruppenbezogene Verarbeitung im Datenschritt ist eine grundlegende Operation, die in die Toolbox jedes SAS-Programmierers gehört.
ZUERST verwenden. und ZULETZT. variablen zu finden zählen die Größe der Gruppen
Das erste Beispiel verwendet Daten aus der Sashelp.Herz-Datensatz, der Daten für 5.209 Patienten in einer medizinischen Studie zu Herzerkrankungen enthält. Die Daten werden mit SAS verteilt. Der folgende Datenschritt extrahiert die Variablen Smoking_Status und Weight und sortiert die Daten nach der Variablen Smoking_Status:
proc Daten sortieren =Sashelp.Herz (keep = Smoking_Status Gewicht) out = Herz; durch Smoking_Status;lauf;
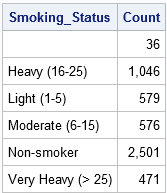
Da die Daten nach der Variablen Smoking_Status sortiert sind, können Sie die ERSTE verwenden.Smoking_Status und LAST.Smoking_Status temporäre Variablen zum Zählen der Anzahl der Beobachtungen in jeder Ebene der Variablen Smoking_Status. (PROC FREQ berechnet dieselben Informationen, benötigt jedoch keine sortierten Daten.)Wenn Sie die BY Smoking_Status-Anweisung verwenden, erstellt der Datenschritt automatisch den ERSTEN.Smoking_Status und LAST.Smoking_Status Indikatorvariablen. Wie der Name schon sagt, der ERSTE.Die Variable Smoking_Status hat für die erste Beobachtung in jeder BY-Gruppe den Wert 1 und ansonsten den Wert 0.(Korrekter ist der Wert 1 für den ersten Datensatz und für Datensätze, für die die Variable Smoking_Status anders ist als für den vorherigen Datensatz.) In ähnlicher Weise die LETZTE.Die Indikatorvariable Smoking_Status hat den Wert 1 für die letzte Beobachtung in jeder BY-Gruppe und ansonsten 0.
Der folgende Datenschritt definiert eine Variable mit dem Namen Count und initialisiert Count=0 am Anfang jeder BY-Gruppe. Für jede Beobachtung in der BY-Gruppe wird die Count-Variable um 1 erhöht. Wenn der letzte Datensatz in jeder BY-Gruppe gelesen wird, wird dieser Datensatz in den Zähldatensatz geschrieben.
data Count; set Heart; /* die Daten werden nach Smoking_Status sortiert */ NACH Smoking_Status; /* erstellt automatisch Indikatorvariablen */ wenn ZUERST.Smoking_Status then Count = 0; /* Initialisieren Sie die Anzahl zu Beginn jeder Gruppe */ Count + 1; /* Erhöhen Sie die Anzahl für jeden Datensatz */ wenn ZULETZT.Smoking_Status; /* gibt nur den letzten Datensatz von jeder Gruppe aus */run; proc print data=Count noobs; format Count comma10.; var Smoking_Status Count;ausführen;
Mit derselben Technik können Sie Werte einer Variablen innerhalb einer Gruppe akkumulieren. Sie können beispielsweise das Gesamtgewicht aller Patienten in jeder Rauchgruppe mithilfe der folgenden Anweisungen akkumulieren:
wenn ZUERST.Smoking_Status dann cumWt = 0; cumWt + Gewicht;
Dieselbe Technik kann verwendet werden, um Einnahmen aus verschiedenen Quellen wie Abteilungen, Geschäften oder Regionen zu sammeln.
ZUERST verwenden. und ZULETZT. variablen zur Berechnung der Behandlungsdauer
Eine weitere häufige Verwendung der ERSTEN.variabel und ZULETZT.variable Indikatorvariablen bestimmen die Zeitspanne zwischen dem ersten Besuch eines Patienten und seinem letzten Besuch. Betrachten Sie den folgenden Datenschritt, Hier werden die Daten und Gewichte für vier männliche Patienten definiert, die im Rahmen eines Gewichtsverlustprogramms eine Klinik besucht haben:
daten Patienten;informat Datum date7.;format Datum date7. Patientennummer Z4.;eingabe Patiententid Datum Gewicht @@;Datenlinien;1021 04Jan16 302 1042 06Jan16 2851053 07Jan16 325 1063 11Jan16 2911053 01Feb16 299 1021 01Feb16 2881063 09Feb16 283 1042 16Feb16 2791021 07Mar16 280 1063 09Mar16 2721042 28Mar16 272 1021 04Apr16 2731063 20Apr16 270 1053 28Apr16 2891053 13Mai16 295 1063 31Mai16 269;
Für diese Daten können Sie nach der Patienten-ID und nach dem Datum des Besuchs sortieren. Nach dem Sortieren enthält der erste Datensatz für jeden Patienten den ersten Besuch in der Klinik und der letzte Datensatz den letzten Besuch. Sie können das Gewicht des Patienten für diese Daten subtrahieren, um zu bestimmen, wie viel der Patient während der Studie gewonnen oder verloren hat. Sie können auch die INTCK-Funktion verwenden, um die verstrichene Zeit zwischen den Besuchen zu berechnen. Wenn Sie die Zeit in Tagen messen möchten, können Sie die Daten einfach subtrahieren, aber mit der Funktion INTCK können Sie die Dauer in Jahren, Monaten, Wochen und anderen Zeiteinheiten berechnen.
proc sort data=Patients; by PatientID Date;run; data weightLoss; set Patients; BY PatientID; retain StartDate startWeight; /* BEHALTEN SIE die Startwerte bei */ wenn ZUERST.PatientID dann tun; StartDate = Datum; startWeight = Gewicht; /* Merken Sie sich die Anfangswerte */ Ende; wenn ZULETZT.PatientID then do; EndDate = Date; endWeight = Weight; elapsedDays = intck('day', StartDate, EndDate); /* verstrichene Zeit (in Tagen) */ weightLoss = startWeight - endWeight; /* Gewichtsverlust */ AvgWeightLoss = Gewichtsverlust / elapsedDays; /* durchschnittlicher Gewichtsverlust pro Tag */ output; /* Ausgabe nur des letzten Datensatzes in jeder Gruppe */ end;run; proc print noobs; var PatientID elapsedDays startWeight endWeight Gewichtverlust Avggewichtverlust; Lauf;
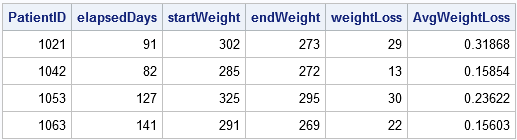
Der Ausgabedatensatz fasst die Aktivitäten jedes Patienten in der Klinik zusammen, einschließlich seines durchschnittlichen Gewichtsverlusts und der Dauer seiner Behandlung.
Einige Programmierer denken, dass die ERSTE.variabel und ZULETZT.variable Indikatorvariablen erfordern, dass die Daten sortiert werden, aber das ist nicht wahr. Die temporären Variablen werden immer dann erstellt, wenn Sie eine BY-Anweisung in einem Datenschritt verwenden. Sie können die Option NOTSORTED in der BY-Anweisung verwenden, um Datensätze unabhängig von der Sortierreihenfolge zu verarbeiten.
Zusammenfassung
Zusammenfassend erstellt die BY-Anweisung im Datenschritt automatisch zwei Indikatorvariablen. Sie können die Variablen verwenden, um den ersten und letzten Datensatz in jeder Gruppe zu bestimmen. Typischerweise der ERSTE.variable Indikator wird verwendet, um zusammenfassende Statistiken zu initialisieren und die Anfangswerte der Messung zu erinnern.Der LETZTE.Variablenindikator wird verwendet, um das Ergebnis der Berechnungen auszugeben, das häufig einfache deskriptive Statistiken wie eine Summe, eine Differenz, ein Maximum, ein Minimum oder einen Durchschnittswert enthält.
Die gruppenbezogene Verarbeitung im Datenschritt ist ein häufiges Thema, das auf SAS-Konferenzen vorgestellt wird. Einige Autoren verwenden FIRST.BY und LAST.BY als Name der Indikatorvariablen. Zur weiteren Lektüre empfehle ich das Papier „The Power of the BY Statement“ (Choate und Dunn, 2007). SAS bietet auch mehrere Beispiele für die gruppenbezogene Verarbeitung im SAS-Datenschritt, einschließlich der folgenden:
- Nicht fehlende Werte in eine BY-Gruppe übertragen
- Nach Gruppen verwenden, um Daten von long nach wide zu transponieren
- Wählen Sie eine bestimmte Anzahl von Beobachtungen oben in jeder BY-Gruppe aus
Tags Erste Schritte mit der SAS-Programmierung