Mi artículo sobre la diferencia entre las variables de CLASE y POR variables en SAS se centró en los procedimientos analíticos de SAS. Sin embargo, la instrucción BY también es útil en el paso de DATOS SAS, donde se utiliza para combinar conjuntos de datos y analizar datos a nivel de grupo. Cuando se utiliza la instrucción BY en el paso de DATOS, el paso de datos crea dos variables indicadoras temporales para cada variable de la instrucción BY. Los nombres de estas variables son LOS PRIMEROS.variable y ÚLTIMA.variable, donde variable es el nombre de una variable en la declaración. Por ejemplo, si utiliza la instrucción POR sexo, los nombres de las variables del indicador son LOS PRIMEROS.Sexo y ÚLTIMO.Sexo.
Este artículo ofrece varios ejemplos de uso del PRIMERO.variable y ÚLTIMA.variables indicadoras de variables para el análisis POR grupos en el paso de DATOS SAS.El primer ejemplo muestra cómo calcular los recuentos y las cantidades acumuladas para cada grupo. El segundo ejemplo muestra cómo calcular el tiempo entre la primera y la última visita de un paciente a una clínica, así como el cambio en una cantidad medida entre la primera y la última visita.El procesamiento por grupos en el paso de DATOS es una operación fundamental que pertenece a la caja de herramientas de cada programador SAS.
Usar PRIMERO. y EL ÚLTIMO. variables para buscar contar el tamaño de los grupos
El primer ejemplo utiliza datos del Sashelp.Conjunto de datos cardiacos, que contiene datos de 5.209 pacientes en un estudio médico de enfermedades cardiacas. Los datos se distribuyen con SAS. El siguiente paso de DATOS extrae las variables Smoking_Status y Weight y ordena los datos por la variable Smoking_Status:
proc sort data=Sashelp.Corazón (keep=Smoking_Status Weight) out = Corazón; por Smoking_Status;ejecutar;
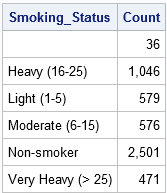
Debido a que los datos están ordenados por la variable Smoking_Status, puede usar la PRIMERA.Estado de humo y ÚLTIMO.Variables temporales Smoking_Status para contar el número de observaciones en cada nivel de la variable Smoking_Status. (PROC FREQ calcula la misma información, pero no requiere datos ordenados.)Cuando se utiliza la instrucción BY Smoking_Status, el paso DATA crea automáticamente la PRIMERA.Estado de humo y ÚLTIMO.Variables indicadoras Smoking_Status. Como su nombre lo indica, el PRIMERO.La variable Smoking_Status tiene el valor 1 para la primera observación en cada grupo y el valor 0 en caso contrario.(Más correctamente, el valor es 1 para el primer registro y para registros para los que la variable Smoking_Status es diferente de lo que era para el registro anterior. Del mismo modo, el ÚLTIMO.La variable indicadora Smoking_Status tiene el valor 1 para la última observación de cada grupo y 0 de lo contrario.
El siguiente paso de DATOS define una variable llamada Count e inicializa Count=0 al principio de cada grupo POR grupo. Para cada observación en el grupo POR, la variable Count se incrementa en 1. Cuando se lee el último registro de cada grupo POR, ese registro se escribe en el conjunto de datos de Recuento.
recuento de datos; establecer corazón; / * los datos se ordenan por estado de humo * / POR Estado de humo; / * crea automáticamente vars de indicadores * / si es EL PRIMERO.Smoking_Status luego Count = 0; / * inicializar el Recuento al principio de cada grupo * / Count + 1; / * incremento de recuento para cada registro * / si ES EL ÚLTIMO.Smoking_Status; / * muestra solo el último registro de cada grupo * / ejecutar; datos de impresión proc = Contar noobs; coma de recuento de formato 10.; ejecutar; ejecutar la cuenta de estado de humo;
La misma técnica le permite acumular valores de una variable dentro de un grupo. Por ejemplo, puede acumular el peso total de todos los pacientes de cada grupo de fumadores utilizando las siguientes declaraciones:
si PRIMERO.Smoking_Status luego cumWt = 0; cumWt + Peso;
Esta misma técnica se puede usar para acumular ingresos de varias fuentes, como departamentos, tiendas o regiones.
Usar PRIMERO. y EL ÚLTIMO. variables para calcular la duración del tratamiento
Otro uso común del PRIMERO.variable y ÚLTIMA.variables indicadoras variables es determinar el tiempo transcurrido entre la primera visita de un paciente y su última visita. Considere el siguiente paso de DATOS, que define las fechas y pesos de cuatro pacientes varones que visitaron una clínica como parte de un programa de pérdida de peso:
datos Pacientes;fecha de información7.;formato de la Fecha de la fecha7. Paciente Z4.;peso de la fecha del paciente de entrada @@;líneas de datos;1021 04Jan16 302 1042 06Jan16 2851053 07Jan16 325 1063 11Jan16 2911053 01Feb16 299 1021 01Feb16 2881063 09Feb16 283 1042 16Feb16 2791021 07Mar16 280 1063 09Mar16 2721042 28Mar16 272 1021 04Apr16 2731063 20Apr16 270 1053 28Apr16 2891053 13May16 295 1063 31May16 269;
Para estos datos, puede ordenar por la identificación del paciente y por la fecha de la visita. Después de la clasificación, el primer registro de cada paciente contiene la primera visita a la clínica y el último registro contiene la última visita. Puede restar el peso del paciente para estas fechas para determinar cuánto ganó o perdió el paciente durante el ensayo. También puede utilizar la función INTCK para calcular el tiempo transcurrido entre visitas. Si desea medir el tiempo en días, simplemente puede restar las fechas, pero la función INTCK le permite calcular la duración en términos de años, meses, semanas y otras unidades de tiempo.
proc ordenar datos = Pacientes; por Fecha del paciente;ejecutar; pérdida de peso de los datos; establecer Pacientes; POR Paciente; conservar el peso inicial de la fecha de inicio; /* CONSERVAR los valores iniciales */ si ES EL PRIMERO.El identificador del paciente, a continuación, hacer; Fecha de inicio = Fecha; Peso de inicio = Peso; / * recuerde los valores iniciales * / fin; si ES EL ÚLTIMO.PatientID luego hacer; Fecha final = Fecha; Peso final = Peso; elapsedDays = intck('día', Fecha de inicio, fecha final); /* tiempo transcurrido (en días) */ Pérdida de peso = Peso inicial - Peso final; /* pérdida de peso */ Pérdida de peso media = pérdida de peso / elapsedDays; /* pérdida de peso promedio por día */ salida; /* salida solo del último registro en cada grupo */ fin;ejecución; noobs de impresión proc; var PatientID elapsedDays Peso inicial Pérdida de peso de peso final Pérdida de peso media;correr;
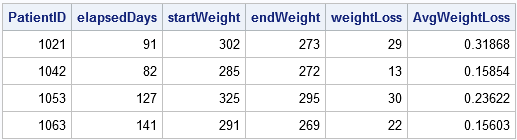
El conjunto de datos de salida resume las actividades de cada paciente en la clínica, incluida su pérdida de peso promedio y la duración de su tratamiento.
Algunos programadores piensan que el PRIMERO.variable y ÚLTIMA.las variables de indicador de variables requieren que los datos se ordenen, pero eso no es cierto. Las variables temporales se crean cada vez que se utiliza una instrucción BY en un paso de DATOS. Puede usar la opción NOTSORTED de la instrucción BY para procesar registros independientemente del orden de clasificación.
Summary
En resumen, la instrucción BY en el paso DATA crea automáticamente dos variables indicadoras. Puede usar las variables para determinar el primer y el último registro de cada grupo. Típicamente el PRIMERO.indicador variable se utiliza para inicializar estadísticas de resumen y para recordar los valores iniciales de medición.El ÚLTIMO.el indicador variable se utiliza para generar el resultado de los cálculos, que a menudo incluye estadísticas descriptivas simples como una suma, diferencia, valores máximos, mínimos o promedio.
El procesamiento por grupos en el paso de DATOS es un tema común que se presenta en las conferencias SAS. Algunos autores usan FIRST.BY y LAST.BY como el nombre de las variables indicadoras. Para más información, recomiendo el artículo «El poder de la Declaración BY» (Choate y Dunn, 2007). SAS también proporciona varios ejemplos sobre el procesamiento por grupos en el paso de DATOS SAS, incluidos los siguientes:
- Llevar valores no faltantes a un Grupo POR
- Usar POR grupos para transponer datos de largo a ancho
- Seleccionar un número especificado de observaciones de la parte superior de cada Grupo por
Etiquetas Introducción a la programación SAS