In un mondo pieno di nuovi strumenti e diversi ambienti di sviluppo, è praticamente una necessità per qualsiasi sviluppatore o ingegnere di imparare alcuni comandi di base sysadmin. Comandi e pacchetti specifici possono aiutare gli sviluppatori a organizzare, risolvere i problemi e ottimizzare le loro applicazioni e, quando le cose vanno male, fornire preziose informazioni di triage agli operatori e agli amministratori di sistema.
Se sei un nuovo sviluppatore o vuoi gestire la tua applicazione, i seguenti 20 comandi di amministratore di sistema di base possono aiutarti a capire meglio le tue applicazioni. Possono anche aiutare a descrivere i problemi agli amministratori di sistema che risolvono il motivo per cui un’applicazione potrebbe funzionare localmente ma non su un host remoto. Questi comandi si applicano agli ambienti di sviluppo Linux, ai contenitori, alle macchine virtuali (VM) e al bare metal.
curl
curl trasferisce un URL. Utilizzare questo comando per testare l’endpoint di un’applicazione o la connettività a un endpoint del servizio upstream. curl può essere utile per determinare se l’applicazione può raggiungere un altro servizio, ad esempio un database, o verificare se il servizio è sano.
Ad esempio, immagina che la tua applicazione generi un errore HTTP 500 che indica che non può raggiungere un database MongoDB:
$ curl -I -s myapplication:5000
HTTP/1.0 500 INTERNAL SERVER ERROR
L’opzione-I mostra le informazioni dell’intestazione e l’opzione-s silenzia il corpo della risposta. Controllo dell’endpoint del database dal desktop locale:
$ curl -I -s database:27017
HTTP/1.0 200 OK
Quindi quale potrebbe essere il problema? Controlla se la tua applicazione può raggiungere altri posti oltre al database dall’host dell’applicazione:
$ curl -I -s https://opensource.com
HTTP/1.1 200 OK
Sembra che vada bene. Ora prova a raggiungere il database dall’host dell’applicazione. L’applicazione utilizza il nome host del database, quindi provalo prima:
$ curl database:27017
curl: (6) Couldn't resolve host 'database'
Ciò indica che l’applicazione non può risolvere il database perché l’URL del database non è disponibile o l’host (contenitore o VM) non dispone di un nameserver che può utilizzare per risolvere il nome host.
python-m json.tool / jq
Dopo aver emesso curl, l’output della chiamata API potrebbe essere difficile da leggere. A volte, si desidera stampare in modo carino l’output JSON per trovare una voce specifica. Python ha una libreria JSON integrata che può aiutare con questo. Si utilizza python-m json.strumento per indentare e organizzare il JSON. Per utilizzare il modulo JSON di Python, convogliare l’output di un file JSON nel json python-M.comando strumento.
$ cat test.json
{"title":"Person","type":"object","properties":{"firstName":{"type":"string"},"lastName":{"type":"string"},"age":{"description":"Age in years","type":"integer","minimum":0}},"required":}
Per utilizzare la libreria Python, convogliare l’output a Python con l’opzione-m (module).
$ cat test.json | python -m json.tool
{
"properties": {
"age": {
"description": "Age in years",
"minimum": 0,
"type": "integer"
},
"firstName": {
"type": "string"
},
"lastName": {
"type": "string"
}
},
"required": ,
"title": "Person",
"type": "object"
}
Per un’analisi JSON più avanzata, è possibile installare jq. jq fornisce alcune opzioni che estraggono valori specifici dall’input JSON. Per pretty-print come il modulo Python sopra, applica semplicemente jq all’output.
$ cat test.json | jq
{
"title": "Person",
"type": "object",
"properties": {
"firstName": {
"type": "string"
},
"lastName": {
"type": "string"
},
"age": {
"description": "Age in years",
"type": "integer",
"minimum": 0
}
},
"required":
}
ls
ls elenca i file in una directory. Gli amministratori di sistema e gli sviluppatori emettono questo comando abbastanza spesso. Nello spazio contenitore, questo comando può aiutare a determinare la directory e i file dell’immagine contenitore. Oltre a cercare i tuoi file, ls può aiutarti a esaminare le tue autorizzazioni. Nell’esempio seguente, non è possibile eseguire myapp a causa di un problema di autorizzazioni. Quando controlli le autorizzazioni usando ls-l, ti rendi conto che le autorizzazioni non hanno una “x” in-rw-r r r., che sono solo in lettura e scrittura.
$ ./myapp
bash: ./myapp: Permission denied
$ ls -l myapp
-rw-r--r--. 1 root root 33 Jul 21 18:36 myapp
tail
tail visualizza l’ultima parte di un file. Di solito non è necessario ogni riga di registro per risolvere i problemi. Invece, vuoi controllare cosa dicono i tuoi registri sulla richiesta più recente alla tua applicazione. Ad esempio, è possibile utilizzare tail per verificare cosa succede nei log quando si effettua una richiesta al server HTTP Apache.
example_tail.png
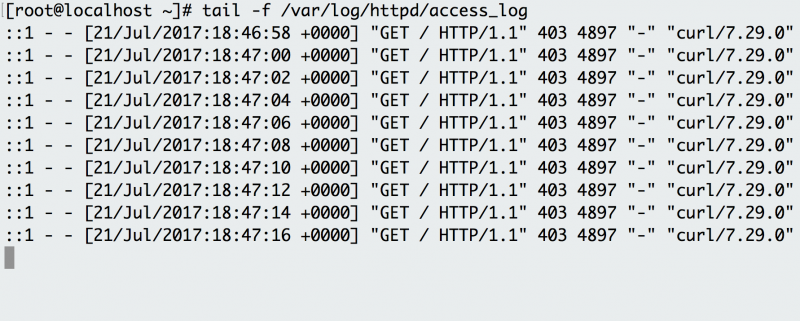
Usa tail-f per seguire i registri HTTP di Apache e vedere le richieste man mano che accadono.
L’opzione-f indica l’opzione” segui”, che emette le righe di registro mentre vengono scritte nel file. L’esempio ha uno script in background che accede all’endpoint ogni pochi secondi e il registro registra la richiesta. Invece di seguire il log in tempo reale, puoi anche usare tail per vedere le ultime 100 righe del file con l’opzione-n.
$ tail -n 100 /var/log/httpd/access_logcat
cat concatena e stampa i file. È possibile emettere cat per controllare il contenuto del file delle dipendenze o per confermare la versione dell’applicazione che è già stata creata localmente.
$ cat requirements.txt
flask
flask_pymongo
L’esempio sopra controlla se l’applicazione Python Flask ha Flask elencato come dipendenza.
grep
grep cerca modelli di file. Se stai cercando un modello specifico nell’output di un altro comando, grep evidenzia le linee rilevanti. Utilizzare questo comando per la ricerca di file di registro, processi specifici e altro ancora. Se vuoi vedere se Apache Tomcat si avvia, potresti essere sopraffatto dal numero di linee. Collegando l’output al comando grep, si isolano le righe che indicano l’avvio del server.
$ cat tomcat.log | grep org.apache.catalina.startup.Catalina.start
01-Jul-2017 18:03:47.542 INFO org.apache.catalina.startup.Catalina.start Server startup in 681 ms
ps
Il comando ps, parte del pacchetto procps-ng che fornisce comandi utili per indagare sugli ID dei processi, mostra lo stato di un processo in esecuzione. Utilizzare questo comando per determinare un’applicazione in esecuzione o confermare un processo previsto. Ad esempio, se si desidera verificare la presenza di un server Web Tomcat in esecuzione, si utilizza ps con le sue opzioni per ottenere l’ID di processo di Tomcat.
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 2 18:55 ? 00:00:02 /docker-java-home/jre/bi
root 59 0 0 18:55 pts/0 00:00:00 /bin/sh
root 75 59 0 18:57 pts/0 00:00:00 ps -ef
Per una leggibilità ancora maggiore, utilizzare ps e collegarlo a grep.
$ ps -ef | grep tomcat
root 1 0 1 18:55 ? 00:00:02 /docker-java-home/jre/bi
env
env consente di impostare o stampare le variabili di ambiente. Durante la risoluzione dei problemi, è possibile che sia utile verificare se la variabile di ambiente errata impedisce l’avvio dell’applicazione. Nell’esempio seguente, questo comando viene utilizzato per controllare le variabili di ambiente impostate sull’host dell’applicazione.
$ env
PYTHON_PIP_VERSION=9.0.1
HOME=/root
DB_NAME=test
PATH=/usr/local/bin:/usr/local/sbin
LANG=C.UTF-8
PYTHON_VERSION=3.4.6
PWD=/
DB_URI=mongodb://database:27017/test
Si noti che l’applicazione utilizza Python e dispone di variabili di ambiente per connettersi a un database MongoDB.
top
top visualizza e aggiorna le informazioni di processo ordinate. Utilizzare questo strumento di monitoraggio per determinare quali processi sono in esecuzione e quanta memoria e CPU consumano. Un caso comune si verifica quando si esegue un’applicazione e muore un minuto dopo. Innanzitutto, si controlla l’errore di ritorno dell’applicazione, che è un errore di memoria.
$ tail myapp.log
Traceback (most recent call last):
MemoryError
La tua applicazione è davvero esaurita? Per confermare, utilizzare top per determinare la quantità di CPU e memoria consumata dall’applicazione. Quando si emette top, si nota un’applicazione Python che utilizza la maggior parte della CPU, con il suo utilizzo della memoria in salita, e si sospetta che sia la propria applicazione. Mentre viene eseguito, si preme il tasto” C ” per vedere il comando completo e il reverse-engineer se il processo è l’applicazione. Risulta essere la tua applicazione ad alta intensità di memoria (memeater.py). Quando l’applicazione ha esaurito la memoria, il sistema lo uccide con un errore out-of-memory (OOM).
example_top.png
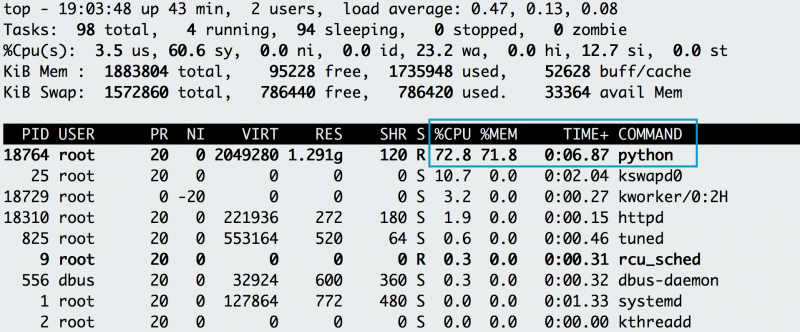
L’utilizzo della memoria e della CPU dell’applicazione aumenta, finendo per essere OOM-ucciso.
example_topwithc.png

Premendo il tasto “C”, è possibile vedere il comando completo che ha avviato l’applicazione.
Oltre a controllare la propria applicazione, è possibile utilizzare top per eseguire il debug di altri processi che utilizzano CPU o memoria.
netstat
netstat mostra lo stato della rete. Questo comando mostra le porte di rete in uso e le relative connessioni in entrata. Tuttavia, netstat non viene out-of-the-box su Linux. Se è necessario installarlo, lo si può trovare nel pacchetto net-tools. Come sviluppatore che sperimenta localmente o spinge un’applicazione a un host, potresti ricevere un errore che indica che una porta è già allocata o che un indirizzo è già in uso. L’utilizzo di netstat con opzioni di protocollo, processo e porta dimostra che il server HTTP Apache utilizza già la porta 80 sull’host sottostante.
example_netstat.png
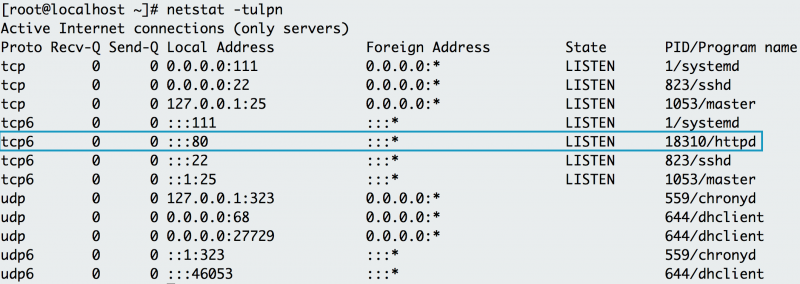
L’utilizzo di netstat-tulpn mostra che Apache utilizza già la porta 80 su questa macchina.
ip
Se l’indirizzo ip non funziona sul tuo host, deve essere installato con il pacchetto iproute2. L’indirizzo del sottocomando (o solo ip a in breve) mostra le interfacce e gli indirizzi IP dell’host dell’applicazione. Si utilizza l’indirizzo IP per verificare l’indirizzo IP del contenitore o dell’host. Ad esempio, quando il contenitore è collegato a due reti, l’indirizzo ip può mostrare quale interfaccia si connette a quale rete. Per un semplice controllo, è sempre possibile utilizzare il comando indirizzo IP per ottenere l’indirizzo IP dell’host. L’esempio seguente mostra che il contenitore del livello Web ha un indirizzo IP di 172.17.0.2 sull’interfaccia eth0.
$ ip address show eth0
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether d4:3b:04:9e:b2:c2 brd ff:ff:ff:ff:ff:ff
inet 10.1.1.3/27 brd 10.1.1.31 scope global dynamic noprefixroute eth0
valid_lft 52072sec preferred_lft 52072sec
lsof
lsof elenca i file aperti associati all’applicazione. Su alcune immagini di macchine Linux, è necessario installare lsof con il pacchetto lsof. In Linux, quasi ogni interazione con il sistema viene trattata come un file. Di conseguenza, se l’applicazione scrive in un file o apre una connessione di rete, lsof rifletterà tale interazione come file. Simile a netstat, è possibile utilizzare lsof per verificare la presenza di porte di ascolto. Ad esempio, se si desidera verificare se la porta 80 è in uso, si utilizza lsof per verificare quale processo lo sta utilizzando. Sotto, puoi vedere che httpd (Apache) ascolta sulla porta 80. È anche possibile utilizzare lsof per controllare l’ID del processo di httpd, esaminando dove risiede il binario del server web (/usr/sbin / httpd).
example_lsof.png
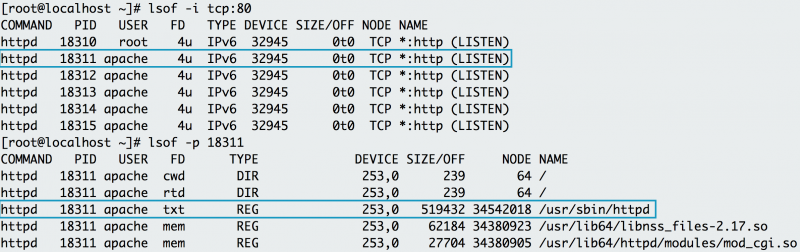
Lsof mostra che httpd è in ascolto sulla porta 80. L’esame dell’ID processo di httpd mostra anche tutti i file di cui httpd ha bisogno per essere eseguito.
Il nome del file aperto nell’elenco dei file aperti aiuta a individuare l’origine del processo, in particolare Apache.
df
È possibile utilizzare df (display free disk space) per risolvere i problemi di spazio su disco. Quando si esegue l’applicazione su un orchestrator contenitore, è possibile che venga visualizzato un messaggio di errore che segnala una mancanza di spazio libero sull’host contenitore. Mentre lo spazio su disco deve essere gestito e ottimizzato da un amministratore di sistema, è possibile utilizzare df per capire lo spazio esistente in una directory e confermare se si è effettivamente fuori dallo spazio.
$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 7.7G 0 7.7G 0% /dev
/dev/mapper/RHEL-Root 50G 16G 35G 31% /
/dev/nvme0n1p2 3.0G 246M 2.8G 9% /boot
/dev/mapper/RHEL-Home 100G 88G 13G 88% /home
/dev/nvme0n1p1 200M 9.4M 191M 5% /boot/efi
/dev/sdb1 114G 55G 54G 51% /run/media/tux/red
L’opzione-h stampa le informazioni in formato leggibile. Per impostazione predefinita, come nell’esempio, df fornisce risultati per tutto nella directory principale, ma puoi anche limitare i risultati fornendo una directory come parte del tuo comando (come df-h /home).
du
Per recuperare informazioni più dettagliate su quali file utilizzano lo spazio su disco in una directory, è possibile utilizzare il comando du. Se si desidera scoprire quale registro occupa più spazio nella directory / var / log, ad esempio, è possibile utilizzare du con l’opzione-h (human-readable) e l’opzione-s per la dimensione totale.
$ du -sh /var/log/*
1.8M /var/log/anaconda
384K /var/log/audit
4.0K /var/log/boot.log
0 /var/log/chrony
4.0K /var/log/cron
4.0K /var/log/maillog
64K /var/log/messages
L’esempio precedente rivela che la directory più grande in /var/log deve essere /var/log/audit. È possibile utilizzare du in combinazione con df per determinare cosa utilizza lo spazio su disco sull’host dell’applicazione.
id
Per controllare l’utente che esegue l’applicazione, utilizzare il comando id per restituire l’identità dell’utente. L’esempio seguente utilizza Vagrant per testare l’applicazione e isolare il suo ambiente di sviluppo. Dopo aver effettuato l’accesso alla casella Vagrant, se si tenta di installare Apache HTTP Server (una dipendenza), il sistema afferma che non è possibile eseguire il comando come root. Per controllare l’utente e il gruppo, emettere il comando id e notare che si sta eseguendo come utente “vagrant” nel gruppo “vagrant”.
$ dnf -y install httpd
Loaded plugins: fastestmirror
You need to be root to perform this command.
$ id
uid=1000(vagrant) gid=1000(vagrant) groups=1000(vagrant) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
Per correggere ciò, è necessario eseguire il comando come superutente, che fornisce privilegi elevati.
chmod
Quando si esegue il binario dell’applicazione per la prima volta sul proprio host, è possibile ricevere il messaggio di errore “permesso negato.”Come si vede nell’esempio per ls, è possibile controllare le autorizzazioni del binario dell’applicazione.
$ ls -l
total 4
-rw-rw-r--. 1 vagrant vagrant 34 Jul 11 02:17 test.sh
Questo dimostra che non si dispone di diritti di esecuzione (nessuna “x”) per eseguire il binario. chmod può correggere le autorizzazioni per consentire all’utente di eseguire il binario.
$ chmod +x test.sh
$ ls -l
total 4
-rwxrwxr-x. 1 vagrant vagrant 34 Jul 11 02:17 test.sh
Come mostrato nell’esempio, questo aggiorna le autorizzazioni con i diritti di esecuzione. Ora, quando si tenta di eseguire il file binario, l’applicazione non genera un errore di autorizzazione negato. Chmod può essere utile quando si carica un binario in un contenitore. Assicura che il tuo contenitore abbia le autorizzazioni corrette per eseguire il tuo binario.
dig / nslookup
Un Domain Name server (DNS) aiuta a risolvere un URL di un set di server di applicazioni. Tuttavia, è possibile che un URL non venga risolto, il che causa un problema di connettività per l’applicazione. Ad esempio, si tenta di accedere al database nell’URL mydatabase dall’host dell’applicazione. Invece, si riceve un errore “impossibile risolvere”. Per risolvere i problemi, si tenta di utilizzare dig (DNS lookup utility) o nslookup (query Internet name server) per capire perché l’applicazione non riesce a risolvere il database.
$ nslookup mydatabase
Server: 10.0.2.3
Address: 10.0.2.3#53
** server can't find mydatabase: NXDOMAIN
L’uso di nslookup mostra che mydatabase non può essere risolto. Cercando di risolvere con dig produce lo stesso risultato.
$ dig mydatabase
; <<>> DiG 9.9.4-RedHat-9.9.4-50.el7_3.1 <<>> mydatabase
;; global options: +cmd
;; connection timed out; no servers could be reached
Questi errori potrebbero essere causati da molti problemi diversi. Se non riesci a eseguire il debug della causa principale, contatta il tuo amministratore di sistema per ulteriori indagini. Per i test locali, questo problema potrebbe indicare che i server dei nomi dell’host non sono configurati in modo appropriato. Per utilizzare questi comandi, è necessario installare il pacchetto BIND Utilities.
firewall-cmd
Tradizionalmente, i firewall sono stati configurati su Linux con il comando iptables, e mentre mantiene la sua ubiquità in realtà è stato in gran parte sostituito da nftables. Un front-end amichevole per nftables, e quello che viene fornito con molte distribuzioni di default, è firewall-cmd. Questo comando consente di impostare le regole che regolano il traffico di rete, sia in uscita che in entrata, consentito dal computer. Queste regole possono essere raggruppate in zone, in modo da poter passare rapidamente e facilmente da un set di regole a un altro, a seconda delle esigenze.
La sintassi del comando è semplice. Usi il comando e un certo numero di opzioni, tutte denominate in modi che ti aiutano a costruire quasi una frase leggibile dall’uomo. Ad esempio, per vedere in quale zona ti trovi attualmente:
$ sudo firewall-cmd --get-active-zones``
corp
interfaces: ens0
dmz
interfaces: ens1
In questo esempio, il computer dispone di due dispositivi di rete e uno viene assegnato alla zona corp, mentre l’altro viene assegnato alla zona dmz.
Per vedere ciò che ogni zona consente, è possibile utilizzare l’opzione --list-all :
$ sudo firewall-cmd --zone corp --list-all
corp
target: default
interfaces: ens0
services: cockpit dhcpv6-client ssh
ports:
protocols:
Aggiungere servizi è altrettanto semplice:
$ sudo firewall-cmd --add-service http --permanent
$ sudo firewall-cmd --reload
Interagire con firewall-cmd è progettato per essere intuitivo, e ha una vasta collezione di servizi predifined, oltre alla possibilità di scrivere regole nft direttamente. Una volta che si inizia a utilizzare firewall-cmd, è possibile scaricare il nostro cheat sheet firewall-cmd per aiutarvi a ricordare le sue opzioni più importanti.
sestatus
Di solito si trova SELinux (un modulo di sicurezza Linux) applicato su un host di applicazioni gestito da un’azienda. SELinux fornisce l’accesso con privilegi minimi ai processi in esecuzione sull’host, impedendo ai processi potenzialmente dannosi di accedere a file importanti sul sistema. In alcune situazioni, un’applicazione deve accedere a un file specifico ma potrebbe generare un errore. Per verificare se SELinux blocca l’applicazione, utilizzare tail e grep per cercare un messaggio “negato” nella registrazione /var/log/audit. Altrimenti, puoi controllare se la casella ha SELinux abilitato usando sestatus.
$ sestatus
SELinux status: enabled
SELinuxfs mount: /sys/fs/selinux
SELinux root directory: /etc/selinux
Loaded policy name: targeted
Current mode: enforcing
Mode from config file: enforcing
Policy MLS status: enabled
Policy deny_unknown status: allowed
Max kernel policy version: 28
L’output sopra indica che l’host dell’applicazione ha SELinux abilitato. Nel tuo ambiente di sviluppo locale, puoi aggiornare SELinux per essere più permissivo. Se hai bisogno di aiuto con un host remoto, il tuo amministratore di sistema può aiutarti a determinare la migliore pratica per consentire all’applicazione di accedere al file di cui ha bisogno. Se interagisci frequentemente con SELinux, scarica il nostro cheat sheet di SELinux per una rapida consultazione.
cronologia
Quando emetti così tanti comandi per il test e il debug, potresti dimenticare quelli utili! Ogni shell ha una variante del comando history. Mostra la cronologia dei comandi che hai emesso dall’inizio della sessione. È possibile utilizzare la cronologia per registrare i comandi utilizzati per risolvere i problemi dell’applicazione. Ad esempio, quando si emette la cronologia nel corso di questo articolo, mostra i vari comandi sperimentati e appresi.
$ history
1 clear
2 df -h
3 du
Cosa succede se si desidera eseguire un comando nella cronologia precedente, ma non si desidera ridigitarlo? Usa ! prima che il numero di comando per ri-eseguire.
example_history.png

Aggiunta ! prima che il numero di comando che si desidera eseguire emette di nuovo il comando.
I comandi di base possono migliorare l’esperienza di risoluzione dei problemi quando si determina il motivo per cui l’applicazione funziona in un ambiente di sviluppo, ma forse non in un altro. Molti amministratori di sistema sfruttano questi comandi per eseguire il debug dei problemi con i sistemi. La comprensione di alcuni di questi utili comandi per la risoluzione dei problemi può aiutarti a comunicare con gli amministratori di sistema e a risolvere i problemi con l’applicazione.
Questo articolo è stato originariamente pubblicato nel luglio 2017 ed è stato aggiornato dall’editore.