min artikel om skillnaden mellan KLASSVARIABLER och av variabler i SAS fokuserade på SAS analytiska procedurer. BY-uttalandet är dock också användbart i SAS-DATASTEGET där det används för att slå samman datamängder och analysera data på gruppnivå. När du använder by-satsen i DATASTEGET skapas två temporära indikatorvariabler för varje variabel i By-satsen i datasteget. Namnen på dessa variabler är först.variabel och sista.variabel, där variabel är namnet på en variabel i BY-satsen. Om du till exempel använder uttalandet efter kön, är namnen på indikatorvariablerna först.Sex och sist.Sex.
den här artikeln ger flera exempel på att använda den första.variabel och sista.variabel indikatorvariabler för analys per grupp i SAS-DATASTEGET.Det första exemplet visar hur man beräknar räkningar och kumulativa belopp för varje grupp. Det andra exemplet visar hur man beräknar tiden mellan patientens första och sista besök på en klinik, liksom förändringen i en uppmätt mängd mellan det första och sista besöket.gruppbehandling i DATASTEGET är en grundläggande operation som hör hemma i varje SAS-programmerares verktygslåda.
använd först. och sist. variabler för att hitta räkna storleken på grupper
det första exemplet använder data från Sashelp.Heart data set, som innehåller data för 5 209 patienter i en medicinsk studie av hjärtsjukdom. Uppgifterna distribueras med SAS. Följande DATASTEG extraherar variablerna Smoking_Status och vikt och sorterar data med variabeln Smoking_Status:
proc sortera data=Sashelp.Hjärta (håll = Smoking_Status Vikt) ut=hjärta; genom Smoking_Status; springa;
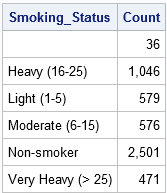
eftersom data sorteras efter variabeln Smoking_Status kan du använda den första.Smoking_Status och sista.Smoking_Status temporära variabler för att räkna antalet observationer i varje nivå av smoking_status variabeln. (PROC FREQ beräknar samma information, men kräver inte sorterade data.) När du använder uttrycket BY Smoking_Status skapas automatiskt det första steget i datasteget.Smoking_Status och sista.Smoking_status indikatorvariabler. Som namnet antyder, den första.Smoking_Status variabel har värdet 1 för den första observationen i varje grupp och värdet 0 annars.(Mer korrekt är värdet 1 för den första posten och för poster för vilka smoking_status-variabeln är annorlunda än för den tidigare posten.) På samma sätt, den sista.Smoking_Status indikatorvariabel har värdet 1 för den sista observationen i varje grupp och 0 annars.
följande DATASTEG definierar en variabel med namnet Count och initierar Count=0 i början av varje grupp. För varje observation i gruppen per ökas räknarvariabeln med 1. När den sista posten i varje grupp läses skrivs den posten till Räknedatauppsättningen.
data Count; set Heart; / * data sorteras efter Smoking_Status * / genom Smoking_Status; / * skapar automatiskt indikator vars * / om först.Smoking_Status sedan räkna = 0; / * initiera räkna i början av varje grupp * / räkna + 1; / * inkrement räkna för varje post */ om sist.Smoking_Status; / * utgång endast den sista posten i varje grupp * / kör; proc utskriftsdata=räkna noobs; format räkna comma10.;var Smoking_Status räkna; springa;
med samma teknik kan du samla värden för en variabel i en grupp. Till exempel kan du samla den totala vikten av alla patienter i varje rökgrupp genom att använda följande uttalanden:
om först.Smoking_Status sedan cumWt = 0; cumWt + vikt;
samma teknik kan användas för att samla intäkter från olika källor, till exempel avdelningar, butiker eller regioner.
använd först. och sist. variabler för att beräkna behandlingstiden
en annan vanlig användning av den första.variabel och sista.variabla indikatorvariabler är att bestämma längden på tiden mellan patientens första besök och hans senaste besök. Tänk på följande datasteg, som definierar datum och vikter för fyra manliga patienter som besökte en klinik som en del av ett viktminskningsprogram:
data patienter;informat datum date7.; formatera datum date7. Patient Z4.;input patienttid datum vikt @@;datalinjer;1021 04Jan16 302 1042 06Jan16 2851053 07Jan16 325 1063 11Jan16 2911053 01Feb16 299 1021 01Feb16 2881063 09Feb16 283 1042 16Feb16 2791021 07mar16 280 1063 09mar16 2721042 28mar16 272 1021 04apr16 2731063 20apr16 270 1053 28apr16 2891053 13maj16 295 1063 31maj16 269;
för dessa uppgifter kan du sortera efter patient-ID och datum för besöket. Efter sortering innehåller den första posten för varje patient det första besöket på kliniken och den sista posten innehåller det senaste besöket. Du kan subtrahera patientens vikt för dessa datum för att bestämma hur mycket patienten fick eller förlorade under försöket. Du kan också använda INTCK-funktionen för att beräkna förfluten tid mellan besök. Om du vill mäta tid i dagar kan du helt enkelt subtrahera datumen, men INTCK-funktionen gör att du kan beräkna varaktighet i termer av år, månader, veckor och andra tidsenheter.
proc sortera data=patienter; efter Patientdatum; kör; data viktminskning; Ställ in patienter; efter patienttid; behåll startdatum startvikt; / * behåll startvärdena * / om först.PatientID gör sedan; startdatum = datum; startvikt = vikt; / * kom ihåg de ursprungliga värdena * / end; om sist.PatientID gör sedan; endDate = datum; endWeight = vikt; elapsedDays = intck('day', startDate, endDate); /* förfluten tid (i dagar) */ weightLoss = startvikt - endvikt; /* viktminskning */ AvgWeightLoss = weightLoss / elapsedDays; /* genomsnittlig viktminskning per dag */ output; /* utgång endast den sista posten i varje grupp */ end;kör; proc print noobs; var Patient elapsedDays startvikt endvikt weightLoss avgweightloss;springa;
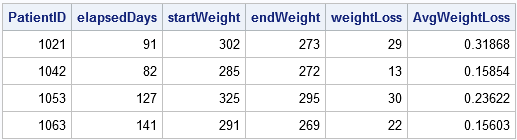
utdatasatsen sammanfattar varje patients aktiviteter på kliniken, inklusive hans genomsnittliga viktminskning och behandlingens varaktighet.
vissa programmerare tror att den första.variabel och sista.variabla indikatorvariabler kräver att data sorteras, men det är inte sant. De tillfälliga variablerna skapas när du använder en BY-sats i ett datasteg. Du kan använda alternativet NOTSORTED I BY-satsen för att bearbeta poster oavsett sorteringsordning.
sammanfattning
Sammanfattningsvis skapar by-satsen i datasteget automatiskt två indikatorvariabler. Du kan använda variablerna för att bestämma den första och sista posten i varje grupp. Typiskt den första.variabel indikator används för att initiera sammanfattande statistik och att komma ihåg de initiala mätvärdena.Den sista.variabel indikator används för att mata ut resultatet av beräkningarna, som ofta innehåller enkla beskrivande statistik såsom en summa, skillnad, maximum, minimum, eller medelvärden.
gruppbearbetning i datasteget är ett vanligt ämne som presenteras på SAS konferenser. Vissa författare använder FIRST.BY och LAST.BY som namnet på indikatorvariablerna. För vidare läsning rekommenderar jag papperet ”The Power of The by Statement” (Choate and Dunn, 2007). SAS tillhandahåller också flera prover om gruppbearbetning i SAS DATA step, inklusive följande:
- bär icke-saknade värden ner en grupp
- använd av grupper för att införliva data från lång till bred
- Välj ett angivet antal observationer från toppen av varje grupp
taggar komma igång SAS programmering