My article about the difference between CLASS variables and BY variables in SAS focused on SAS analytical procedures. No entanto, a declaração por também é útil no passo de dados SAS onde é usado para fundir conjuntos de dados e analisar dados ao nível do grupo. Quando você usa a declaração por na etapa de dados, a etapa de dados cria duas variáveis indicadoras temporárias para cada variável na declaração por. Os nomes destas variáveis são os primeiros.variável e última.variável, em que variável é o nome de uma variável na instrução BY. Por exemplo, se você usar a declaração por sexo, então os nomes das variáveis indicadoras são primeiro.Sexo e último.Sexo.
este artigo dá vários exemplos de Utilização do primeiro.variável e última.variáveis indicadoras variáveis para análise por grupo na fase de dados do SAS.O primeiro exemplo mostra como calcular contagens e quantias cumulativas para cada grupo. O segundo exemplo mostra como calcular o tempo entre a primeira e a última visita de um paciente a uma clínica, bem como a mudança na quantidade medida entre a primeira e a última visita.o processamento por grupo na etapa de dados é uma operação fundamental que pertence a cada caixa de ferramentas do programador SAS.
utilizar primeiro. e por último. variáveis para encontrar a contagem do tamanho dos grupos
o primeiro exemplo usa dados do Sashelp.Conjunto de dados cardíacos, que contém dados para 5209 doentes num estudo médico de doença cardíaca. Os dados são distribuídos com SAS. A seguinte etapa de dados extrai as variáveis Smoking_Status e peso e ordena os dados pela variável Smoking_Status:
proc sort data=Sashelp.Heart (keep=Smoking_ Status Weight) out = Heart; by Smoking_ Status; run;
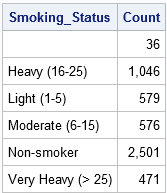
como os dados são classificados pela variável Smoking_Status, você pode usar o primeiro.Smoking_Status e último.Smoking_status variáveis temporárias para contar o número de observações em cada nível da variável Smoking_Status. (PROC FREQ calcula a mesma informação, mas não requer dados ordenados.)Quando você usa a instrução BY Smoking_Status, o passo de dados cria automaticamente o primeiro.Smoking_Status e último.Variáveis indicadoras Smoking_Status. Como o seu nome indica, o primeiro.A variável Smoking_Status tem o valor 1 para a primeira observação em cada grupo e o valor 0 de outra forma.(Mais corretamente, o valor é 1 para o primeiro registro e para os registros para os quais a variável Smoking_Status é diferente do que era para o registro anterior.) Similarmente, o último.A variável indicador Smoking_Status tem o valor 1 para a última observação em cada grupo e 0 de outra forma.
a seguinte etapa de dados define uma variável chamada contagem e inicializa a contagem=0 no início de cada grupo. Para cada observação no grupo por, a variável contagem é incrementada por 1. Quando o último registro em cada grupo é lido, esse registro é escrito para o conjunto de dados de contagem.
Contagem de dados; definir o coração; / * os dados são ordenados por Smoking_ status */ por Smoking_ Status; / * cria automaticamente os vars indicadores */ if primeiro.Smoking_ status em seguida, contar = 0; / * inicializar a contagem no início de cada por grupo */ Contagem + 1; /* contagem incremental para cada registro */ se último.Smoking_ status; / * obtém apenas o último registo de cada grupo */run; proc print data=Count noobs; format Count comma 10.; var Smoking_ Status Count;run;
A mesma técnica permite acumular valores de uma variável dentro de um grupo. Por exemplo, você pode acumular o peso total de todos os pacientes em cada grupo fumante usando as seguintes indicações:
se primeiro.Smoking_ status then cumWt = 0; cumWt + Weight;
esta mesma técnica pode ser usada para acumular receitas de várias fontes, tais como departamentos, lojas ou regiões.
utilizar primeiro. e por último. variáveis para calcular a duração do tratamento
outro uso comum do primeiro.variável e última.variáveis indicadoras variáveis são para determinar o tempo entre a primeira visita de um paciente e sua última visita. Considere a seguinte etapa de dados, que define as datas e pesos para quatro pacientes do sexo masculino que visitaram uma clínica como parte de um programa de perda de peso:
doentes tratados;data de informação7.; formato Data data7. PatientID Z4.;input id do paciente Data de Peso @@;datalines;1021 04Jan16 302 1042 06Jan16 2851053 07Jan16 325 1063 11Jan16 2911053 01Feb16 299 1021 01Feb16 2881063 09Feb16 283 1042 16Feb16 2791021 07Mar16 280 1063 09Mar16 2721042 28Mar16 272 1021 04Apr16 2731063 20Apr16 270 1053 28Apr16 2891053 13May16 295 1063 31May16 269;
Para esses dados, você pode classificar por o ID do paciente e a data da visita. Após a triagem, o primeiro registro de cada paciente contém a primeira visita à clínica e o último registro contém a última visita. Você pode subtrair o peso do paciente para estas datas para determinar o quanto o paciente ganhou ou perdeu durante o ensaio. Você também pode usar a função INTCK para calcular o tempo decorrido entre as visitas. Se você quiser medir o tempo em dias, você pode simplesmente subtrair as datas, mas a função INTCK permite que você compute a duração em termos de anos, meses, semanas e outras unidades de tempo.
proc sort data = pacientes; por Data Patientida; executar; peso dos dados; definir pacientes; por PatientID; manter o peso inicial da data de início; / * reter os valores iniciais */ if primeiro.PatientID então faça; data de início = Data; peso de início = Peso; / * recordar os valores iniciais */ end; se for o último.Id do paciente, em seguida, fazer; endDate = Data; endWeight = Peso; elapsedDays = intck('dia', startDate endDate); /* tempo decorrido (em dias) */ emagrecimento = startWeight - endWeight; /* perda de peso */ AvgWeightLoss = emagrecimento / elapsedDays; /* média de perda de peso por dia */ saída; /* saída apenas o último registro em cada grupo */ end;run; proc print noobs; var id do paciente elapsedDays startWeight endWeight de emagrecimento AvgWeightLoss;executar;
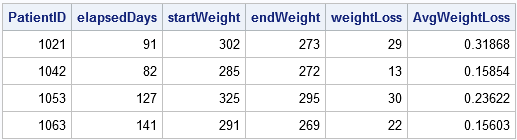
o conjunto de dados de saída resume as actividades de cada doente na clínica, incluindo a sua perda média de peso e a duração do seu tratamento.
alguns programadores pensam que o primeiro.variável e última.variáveis indicadoras variáveis exigem que os dados sejam ordenados, mas isso não é verdade. As variáveis temporárias são criadas sempre que você usa uma declaração por em um passo de dados. Você pode usar a opção NOTSORTED na instrução BY para processar registros, independentemente da ordem de ordenação.
resumo
em resumo, O BY statement na etapa de dados cria automaticamente duas variáveis indicadoras. Você pode usar as variáveis para determinar o primeiro e último registro em cada grupo. Tipicamente o primeiro.indicador variável é usado para inicializar estatísticas sumárias e para lembrar os valores iniciais de medição.passado.indicador variável é usado para produzir o resultado dos cálculos, que muitas vezes inclui estatísticas descritivas simples, tais como uma soma, diferença, valores máximos, mínimos ou médios.
o processamento por grupo na etapa de dados é um tópico comum que é apresentado em conferências da SAS. Alguns autores usam FIRST.BY e LAST.BY como o nome das variáveis indicadoras. Para leitura adicional, eu recomendo o artigo” o poder da declaração de BY ” (Choate e Dunn, 2007). A SAS também fornece várias amostras sobre o processamento por grupo na fase de dados do SAS, incluindo o seguinte::
- transportar valores não em falta para um grupo por grupo
- utilização por grupos para transpor dados de longo para Largo
- seleccionar um número especificado de observações no topo de cada grupo por grupo
Marcas A Iniciar programação SAS