můj článek o rozdílu mezi proměnnými třídy a proměnnými v SAS se zaměřil na analytické postupy SAS. Příkaz BY je však také užitečný v datovém kroku SAS, kde se používá ke sloučení datových sad a analýze dat na úrovni skupiny. Při použití příkazu BY v datovém kroku vytvoří datový krok dvě proměnné dočasného indikátoru pro každou proměnnou v příkazu BY. Názvy těchto proměnných jsou první.proměnná a poslední.proměnná, kde proměnná je název proměnné ve příkazu BY. Pokud například použijete příkaz podle pohlaví, jsou nejprve názvy proměnných indikátorů.Sex a poslední.Sex.
tento článek uvádí několik příkladů použití prvního.proměnná a poslední.variable indicatorvariables pro analýzu podle skupin v datovém kroku SAS.První příklad ukazuje, jak vypočítat počty a kumulativní částky pro každou skupinu. Druhý příklad ukazuje, jak vypočítat čas mezi první a poslední návštěvy pacienta na klinice, stejně jako změny v měřené množství mezi první a poslední návštěvou.-Skupina zpracování DAT krok je zásadní operaci, která patří v každé SAS programmer ‚ s tool box.
použijte jako první. a poslední. proměnné k nalezení počítají velikost skupin
první příklad používá data z Sashelp.Soubor údajů o srdci, který obsahuje údaje o 5 209 pacientech v lékařské studii srdečních chorob. Data jsou distribuována s SAS. Následující datový krok extrahuje proměnné Smoking_Status a Weight a třídí data proměnnou Smoking_Status:
proc třídit data=Sashelp.Heart (keep=Smoking_Status Weight) out=Heart; by Smoking_Status; run;
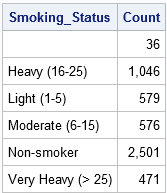
protože jsou data seřazena podle proměnné Smoking_Status, můžete použít první.Smoking_Status a poslední.Smoking_Status dočasné proměnné pro počítání počtu pozorování v každé úrovni proměnné Smoking_Status. (PROC FREQ počítá stejné informace, ale nevyžaduje tříděná data.) Pokud použijete příkaz by Smoking_Status, datový krok automaticky vytvoří první.Smoking_Status a poslední.Smoking_Status indikátor proměnné. Jak název napovídá, první.Proměnná Smoking_Status má hodnotu 1 pro první pozorování v každé skupině a hodnotu 0 jinak.(Přesněji, hodnota je 1 pro první záznam a pro záznamy, pro které je proměnná Smoking_Status Jiná než pro předchozí záznam.) Podobně Poslední.Proměnná indikátoru Smoking_Status má hodnotu 1 pro poslední pozorování v každé skupině A 0 jinak.
následující datový krok definuje proměnnou s názvem Count a inicializuje Count=0 na začátku každé skupiny. Pro každé pozorování ve skupině podle je proměnná počtu zvýšena o 1. Když je přečten poslední záznam v každé skupině, tento záznam je zapsán do datové sady Count.
počet dat; nastavit srdce; / * data jsou řazena podle Smoking_Status * / podle Smoking_Status; / * automaticky vytvoří indikátor vars * / if FIRST.Smoking_Status pak Count = 0; / * inicializovat počet na začátku každé skupiny * / Count + 1; / * počet přírůstků pro každý záznam */ pokud je poslední.Smoking_Status; / * výstup pouze poslední záznam každého ze skupin * / run; proc print data=Count noobs; formát Počet čárka10.; var Smoking_Status Count; běh;
stejná technika umožňuje hromadit hodnoty proměnné ve skupině. Například můžete akumulovat celkovou hmotnost všech pacientů v každé Kuřácké skupině pomocí následujících příkazů:
pokud první.Smoking_Status pak cumWt = 0; cumWt + hmotnost;
stejnou techniku lze použít k akumulaci příjmů z různých zdrojů, jako jsou oddělení, obchody nebo regiony.
použijte jako první. a poslední. proměnné pro výpočet trvání léčby
další běžné použití prvního.proměnná a poslední.proměnné proměnné indikátoru určují dobu mezi první návštěvou pacienta a jeho poslední návštěvou. Zvažte následující ÚDAJE krok, který definuje data a váhy pro čtyři mužské pacientů, kteří navštívili kliniku jako součást programu hubnutí:
data Pacientů;informat Datum date7.; formát Datum date7. PatientID Z4.;vstupní PatientID Datum Váhu @@;datalines;1021 04Jan16 302 1042 06Jan16 2851053 07Jan16 325 1063 11Jan16 2911053 01Feb16 299 1021 01Feb16 2881063 09Feb16 283 1042 16Feb16 2791021 07Mar16 280 1063 09Mar16 2721042 28Mar16 272 1021 04Apr16 2731063 20Apr16 270 1053 28Apr16 2891053 13May16 295 1063 31May16 269;
Pro tyto údaje, můžete řadit podle ID pacienta a datem návštěvy. Po třídění obsahuje první záznam pro každého pacienta první návštěvu kliniky a poslední záznam obsahuje poslední návštěvu. Můžete odečíst hmotnost pacienta pro tato data a určit, kolik pacient během studie získal nebo ztratil. Funkci INTCK můžete také použít k výpočtu uplynulého času mezi návštěvami. Pokud chcete měřit čas ve dnech, můžete jednoduše odečíst Data, ale funkce INTCK umožňuje vypočítat trvání z hlediska let, měsíců, týdnů a dalších časových jednotek.
proc sort data=pacienti; podle data PatientID; běh; ztráta dat; nastavit pacienty; podle PatientID; zachovat počáteční datum počáteční hmotnost; / * zachovat počáteční hodnoty * / pokud je první.PatientID pak dělat; startDate = Date; startWeight = Weight; / * zapamatujte si počáteční hodnoty * / end; pokud Poslední.PatientID pak dělat; koncové datum = Datum; endWeight = Hmotnost; elapsedDays = intck ("den", počátečnídatum, endDate); /* uplynulý čas (ve dnech) */ weightLoss = startWeight - endWeight; /* hubnutí */ AvgWeightLoss = weightLoss / elapsedDays; /* průměrná ztráta hmotnosti za den */ output; /* výstup pouze poslední záznam v každé skupině */ end;run; proc print noobs; var PatientID elapsedDays startWeight endWeight weightLoss AvgWeightLoss;spustit;
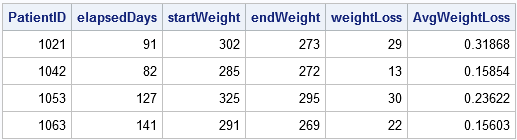
soubor výstupních dat shrnuje aktivity každého pacienta na klinice, včetně jeho průměrného úbytku hmotnosti a trvání léčby.
někteří programátoři si myslí, že první.proměnná a poslední.proměnné ukazatele proměnných vyžadují, aby byla data tříděna, ale to není pravda. Dočasné proměnné se vytvoří vždy, když použijete příkaz BY v datovém kroku. Pro zpracování záznamů bez ohledu na pořadí řazení můžete použít volbu NOTSORTED v příkazu BY.
shrnutí
v souhrnu příkaz BY v datovém kroku automaticky vytvoří dvě proměnné indikátoru. Proměnné můžete použít k určení prvního a posledního záznamu v každé skupině. Typicky první.proměnný indikátor se používá k inicializaci souhrnných statistik a zapamatování počátečních hodnot měření.Poslední.proměnný indikátor se používá k výstupu výsledku výpočtů, které často obsahují jednoduché popisné statistiky, jako je součet, rozdíl, maximální, minimální nebo průměrné hodnoty.
zpracování podle skupin v datovém kroku je běžným tématem, které je prezentováno na konferencích SAS. Někteří autoři používají FIRST.BY a LAST.BY jako název proměnných indikátoru. Pro další čtení doporučuji článek “ the Power of the by Statement „(Choate and Dunn, 2007). SAS také poskytuje několik vzorků o zpracování podle skupin v datovém kroku SAS, včetně následujících:
- Nosit non-chybějící hodnoty dolů OD Skupiny
- Použití skupiny provést data z dlouhé široké
- Vyberte určitý počet pozorování z vrcholu každý BY-Group
Značky začínáme SAS Programování