Mon article sur la différence entre les variables de CLASSE et PAR variables dans SAS s’est concentré sur les procédures analytiques SAS. Cependant, l’instruction BY est également utile dans l’étape de DONNÉES SAS où elle est utilisée pour fusionner des ensembles de données et analyser des données au niveau du groupe. Lorsque vous utilisez l’instruction BY dans l’étape DONNÉES, l’étape DONNÉES crée deux variables d’indicateur temporaires pour chaque variable de l’instruction BY. Les noms de ces variables sont les PREMIERS.variable et DERNIÈRE.variable, où variable est le nom d’une variable dans l’instruction BY. Par exemple, si vous utilisez l’énoncé PAR sexe, les noms des variables indicatrices sont les PREMIERS.Sexe et DERNIER.Sexe.
Cet article donne plusieurs exemples d’utilisation du PREMIER.variable et DERNIÈRE.variable indicateurvariables pour l’analyse PAR groupe dans l’étape de DONNÉES SAS.Le premier exemple montre comment calculer les nombres et les montants cumulatifs pour chaque groupe. Le deuxième exemple montre comment calculer le temps entre la première et la dernière visite d’un patient dans une clinique, ainsi que le changement d’une quantité mesurée entre la première et la dernière visite.Le traitement PAR groupe dans l’étape des DONNÉES est une opération fondamentale qui appartient à la boîte à outils de chaque programmeur SAS.
Utilisez D’ABORD. et ENFIN. variables pour trouver count la taille des groupes
Le premier exemple utilise les données de la ceinture.Ensemble de données cardiaques, qui contient des données pour 5 209 patients dans une étude médicale sur les maladies cardiaques. Les données sont distribuées avec SAS. L’étape de DONNÉES suivante extrait les variables Smoking_Status et Weight et trie les données par la variable Smoking_Status:
données de tri proc = Aide à la ceinture.Cœur (garder = Poids du statut de fumée) = Cœur; par le statut de fumée; exécuter;
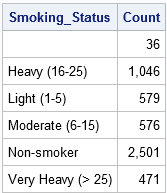
Étant donné que les données sont triées par la variable Smoking_Status, vous pouvez utiliser la PREMIÈRE.Smoking_Status et DERNIER.Variables temporaires Smoking_Status pour compter le nombre d’observations dans chaque niveau de la variable Smoking_Status. (PROC FREQ calcule les mêmes informations, mais ne nécessite pas de données triées.) Lorsque vous utilisez l’instruction BY Smoking_Status, l’étape DATA crée automatiquement la PREMIÈRE.Smoking_Status et DERNIER.Variables de l’indicateur Smoking_Status. Comme son nom l’indique, le PREMIER.La variable Smoking_Status a la valeur 1 pour la première observation dans chaque groupe et la valeur 0 sinon.(Plus correctement, la valeur est 1 pour le premier enregistrement et pour les enregistrements pour lesquels la variable Smoking_Status est différente de celle de l’enregistrement précédent.) De même, le DERNIER.La variable indicateur Smoking_Status a la valeur 1 pour la dernière observation dans chaque groupe et 0 sinon.
L’étape de DONNÉES suivante définit une variable nommée Count et initialise Count=0 au début de chaque groupe BY. Pour chaque observation du groupe BY, la variable Count est incrémentée de 1. Lorsque le dernier enregistrement de chaque groupe BY est lu, cet enregistrement est écrit dans l’ensemble de données de comptage.
nombre de données; définir le cœur; /* les données sont triées par Smoking_Status * / PAR Smoking_Status; /* crée automatiquement des variables d'indicateur */ si D'ABORD.Smoking_Status alors Count = 0; /* initialiser le nombre au début de chaque groupe * / Count + 1; /* incrémenter le nombre pour chaque enregistrement * / si LE DERNIER.Smoking_Status; /* affiche uniquement le dernier enregistrement de chaque groupe */run; proc print data = Count noobs; formater le nombre de virgules 10.; var Nombre d'états de fumée; exécuter;
La même technique vous permet d’accumuler les valeurs d’une variable au sein d’un groupe. Par exemple, vous pouvez accumuler le poids total de tous les patients de chaque groupe de fumeurs en utilisant les déclarations suivantes:
si D'ABORD.État de la fumée alors cumWt = 0; cumWt + Poids;
Cette même technique peut être utilisée pour accumuler des revenus provenant de diverses sources, telles que des départements, des magasins ou des régions.
Utilisez D’ABORD. et ENFIN. variables pour calculer la durée du traitement
Une autre utilisation courante de la PREMIÈRE.variable et DERNIÈRE.l’indicateur variable variables sert à déterminer la durée entre la première visite d’un patient et sa dernière visite. Considérez l’étape de DONNÉES suivante, qui définit les dates et les poids de quatre patients de sexe masculin qui ont visité une clinique dans le cadre d’un programme de perte de poids:
données Patients;date d'information7.; format Date date7. Patient Z4.1021 04Jan16 302 1042 06Jan16 2851053 07Jan16 325 1063 11Jan16 2911053 01Feb16 299 1021 01Feb16 2881063 09Feb16 283 1042 16Feb16 2791021 07Mar16 280 1063 09Mar16 2721042 28Mar16 272 1021 04Avr16 2731063 20Avr16 270 1053 28Avr16 2891053 13Mai16 295 1063 31Mai16 269;
Pour ces données, vous pouvez trier par l’identifiant du patient et par la date de visite. Après le tri, le premier dossier de chaque patient contient la première visite à la clinique et le dernier dossier contient la dernière visite. Vous pouvez soustraire le poids du patient pour ces dates afin de déterminer combien le patient a gagné ou perdu pendant l’essai. Vous pouvez également utiliser la fonction INTCK pour calculer le temps écoulé entre les visites. Si vous souhaitez mesurer le temps en jours, vous pouvez simplement soustraire les dates, mais la fonction INTCK vous permet de calculer la durée en termes d’années, de mois, de semaines et d’autres unités de temps.
proc sort data = Patients; par Date du patient; exécuter; Perte de poids des données; définir les patients; PAR PatientID; conserver la date de début Poids de départ; /* CONSERVER les valeurs de départ * / si D'ABORD.PatientID alors faire; startDate = Date; startWeight = Weight; /* rappelez-vous les valeurs initiales * / end; si DERNIER.PatientID puis faire; endDate = Date; endWeight = Poids; elapsedDays = intck('day', startDate, endDate); /* temps écoulé (en jours) * / weightLoss = startWeight - endWeight; /* perte de poids * / AvgWeightLoss = weightLoss /elapsedDays; /* perte de poids moyenne par jour */ sortie; /* sortie uniquement le dernier enregistrement de chaque groupe * / end; run; proc print noobs; var PatientID elapsedDays startWeight Poids final Perte de poids moyenne Perte de poids; courir;
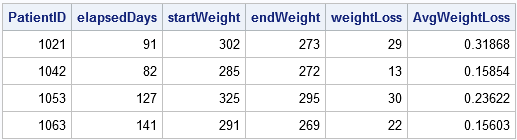
L’ensemble de données de sortie résume les activités de chaque patient à la clinique, y compris sa perte de poids moyenne et la durée de son traitement.
Certains programmeurs pensent que le PREMIER.variable et DERNIÈRE.les variables d’indicateur de variable exigent que les données soient triées, mais ce n’est pas vrai. Les variables temporaires sont créées chaque fois que vous utilisez une instruction BY dans une étape de DONNÉES. Vous pouvez utiliser l’option NOTSORTED de l’instruction BY pour traiter les enregistrements quel que soit l’ordre de tri.
Summary
En résumé, l’instruction BY de l’étape DONNÉES crée automatiquement deux variables indicatrices. Vous pouvez utiliser les variables pour déterminer le premier et le dernier enregistrement de chaque groupe. Typiquement le PREMIER.l’indicateur variable est utilisé pour initialiser des statistiques sommaires et pour mémoriser les valeurs initiales de mesure.Le DERNIER.l’indicateur variable est utilisé pour produire le résultat des calculs, qui comprend souvent des statistiques descriptives simples telles qu’une somme, une différence, des valeurs maximales, minimales ou moyennes.
Le traitement par groupe à l’étape des DONNÉES est un sujet courant présenté lors des conférences SAS. Certains auteurs utilisent FIRST.BY et LAST.BY comme nom des variables indicatrices. Pour une lecture plus approfondie, je recommande l’article « The Power of the BY Statement » (Choate et Dunn, 2007). SAS fournit également plusieurs exemples de traitement PAR groupe dans l’étape de DONNÉES SAS, notamment les suivants:
- Transporter les valeurs non manquantes dans un Groupe PAR
- Utiliser PAR groupes pour transposer les données de long en large
- Sélectionnez un nombre spécifié d’observations en haut de chaque groupe PAR
Balises Mise en route de la programmation SAS