Il mio articolo sulla differenza tra variabili di CLASSE e variabili in SAS si è concentrato sulle procedure analitiche SAS. Tuttavia, l’istruzione BY è utile anche nella fase DATI SAS in cui viene utilizzata per unire set di dati e per analizzare i dati a livello di gruppo. Quando si utilizza l’istruzione BY nel passaggio DATI, il passaggio DATI crea due variabili indicatore temporanee per ciascuna variabile nell’istruzione BY. I nomi di queste variabili sono i PRIMI.variabile e ULTIMO.variabile, dove variabile è il nome di una variabile nell’istruzione BY. Ad esempio, se si utilizza l’istruzione PER Sesso, i nomi delle variabili dell’indicatore sono i PRIMI.Sesso e ULTIMO.Sesso.
Questo articolo fornisce diversi esempi di utilizzo del PRIMO.variabile e ULTIMO.variabile indicatorvariables per l’analisi per gruppo nella fase DATI SAS.Il primo esempio mostra come calcolare i conteggi e gli importi cumulativi per ciascun gruppo. Il secondo esempio mostra come calcolare il tempo tra la prima e l’ultima visita di un paziente in una clinica, così come la variazione di una quantità misurata tra la prima e l’ultima visita.L’elaborazione per gruppo nella fase dei DATI è un’operazione fondamentale che appartiene alla cassetta degli attrezzi di ogni programmatore SAS.
Utilizzare PRIMA. e ULTIMO. le variabili per trovare contano la dimensione dei gruppi
Il primo esempio utilizza i dati del Sashelp.Set di dati cardiaci, che contiene dati per 5.209 pazienti in uno studio medico sulle malattie cardiache. I dati sono distribuiti con SAS. Il seguente passaggio DATI estrae le variabili Smoking_Status e Weight e ordina i dati in base alla variabile Smoking_Status:
proc ordina dati=Sashelp.Cuore (mantenere=peso Smoking_Status) out = Cuore; da Smoking_Status; eseguire;
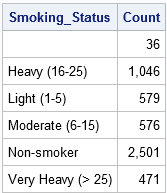
Poiché i dati sono ordinati in base alla variabile Smoking_Status, è possibile utilizzare il PRIMO.Smoking_Status e ULTIMO.Variabili temporanee Smoking_Status per contare il numero di osservazioni in ogni livello della variabile Smoking_Status. (PROC FREQ calcola le stesse informazioni, ma non richiede dati ordinati.) Quando si utilizza l’istruzione BY Smoking_Status, il passaggio DATI crea automaticamente il PRIMO.Smoking_Status e ULTIMO.Variabili dell’indicatore Smoking_Status. Come suggerisce il nome, il PRIMO.La variabile Smoking_Status ha il valore 1 per la prima osservazione in ciascun gruppo e il valore 0 in caso contrario.(Più correttamente, il valore è 1 per il primo record e per i record per i quali la variabile Smoking_Status è diversa rispetto al record precedente.) Allo stesso modo, l’ULTIMO.La variabile dell’indicatore Smoking_Status ha il valore 1 per l’ultima osservazione in ciascun gruppo e 0 in caso contrario.
Il seguente passaggio DATI definisce una variabile denominata Count e inizializza Count = 0 all’inizio di ciascuna PER gruppo. Per ogni osservazione nel gruppo BY, la variabile Count viene incrementata di 1. Quando viene letto l’ultimo record in ciascun gruppo PER, tale record viene scritto nel set di dati Count.
conteggio dati; imposta cuore; / * i dati sono ordinati per Smoking_Status * / DA Smoking_Status; / * crea automaticamente indicatore vars * / se PRIMA.Smoking_Status quindi Count = 0; / * inizializza il conteggio all'inizio di ogni gruppo */ Count + 1; / * incrementa il conteggio per ogni record * / se ULTIMO.Smoking_Status; / * output solo l'ultimo record di ciascuno PER gruppo * / run; proc print data = Count noobs; format Count comma10.; var Smoking_Status Count; esegui;
La stessa tecnica consente di accumulare valori di una variabile all’interno di un gruppo. Ad esempio, è possibile accumulare il peso totale di tutti i pazienti in ciascun gruppo di fumatori utilizzando le seguenti dichiarazioni:
se PRIMA.Smoking_Status poi cumWt = 0; cumWt + Peso;
Questa stessa tecnica può essere utilizzata per accumulare entrate da varie fonti, come dipartimenti, negozi o regioni.
Utilizzare PRIMA. e ULTIMO. variabili per calcolare la durata del trattamento
Un altro uso comune del PRIMO.variabile e ULTIMO.variabili indicatrici variabili è quello di determinare il periodo di tempo tra la prima visita di un paziente e la sua ultima visita. Considera il seguente passaggio di DATI, che definisce le date e i pesi per quattro pazienti maschi che hanno visitato una clinica come parte di un programma di perdita di peso:
dati Pazienti;informat Data date7.; formato Data date7. PatientID Z4.l'ingresso ;PatientID Data Peso @@;datalines;1021 04Jan16 302 1042 06Jan16 2851053 07Jan16 325 1063 11Jan16 2911053 01Feb16 299 1021 01Feb16 2881063 09Feb16 283 1042 16Feb16 2791021 07Mar16 280 1063 09Mar16 2721042 28Mar16 272 1021 04Apr16 2731063 20Apr16 270 1053 28Apr16 2891053 13May16 295 1063 31May16 269;
Per questi dati, è possibile ordinare l’ID del paziente e la data della visita. Dopo l’ordinamento, il primo record per ogni paziente contiene la prima visita alla clinica e l’ultimo record contiene l’ultima visita. È possibile sottrarre il peso del paziente per queste date per determinare quanto il paziente ha guadagnato o perso durante lo studio. È inoltre possibile utilizzare la funzione INTCK per calcolare il tempo trascorso tra le visite. Se si desidera misurare il tempo in giorni, è sufficiente sottrarre le date, ma la funzione INTCK consente di calcolare la durata in termini di anni, mesi, settimane e altre unità di tempo.
proc sort data = Patients; by PatientID Date; run; data weightLoss; set Patients; BY PatientID; mantieni startDate startWeight; / * MANTIENI i valori iniziali */ se PRIMA.PatientID poi fare; startDate = Date; startWeight = Weight; / * ricorda i valori iniziali * / end; if LAST.PatientID quindi fare; data = Data; endWeight = Peso; elapsedDays = intck('giorno', datainizio, datafine); /* intervallo di tempo (in giorni) */ strana soluzione dimagrante = startWeight - endWeight; /* perdita di peso */ AvgWeightLoss = strana soluzione dimagrante / elapsedDays; /* valore medio di perdita di peso al giorno */ uscita; /* uscita solo l'ultimo record in ogni gruppo */ end;run; proc print niubbi; var PatientID elapsedDays startWeight endWeight strana soluzione dimagrante AvgWeightLoss;eseguire;
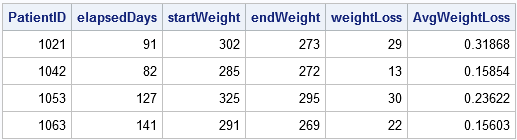
Il set di dati di output riassume le attività di ciascun paziente presso la clinica, compresa la sua perdita di peso media e la durata del suo trattamento.
Alcuni programmatori pensano che il PRIMO.variabile e ULTIMO.le variabili dell’indicatore variabile richiedono che i dati siano ordinati, ma non è vero. Le variabili temporanee vengono create ogni volta che si utilizza un’istruzione BY in un passaggio DATI. È possibile utilizzare l’opzione NOTSORTED sull’istruzione BY per elaborare i record indipendentemente dall’ordinamento.
Riepilogo
In riepilogo, l’istruzione BY nella fase DATI crea automaticamente due variabili indicatore. È possibile utilizzare le variabili per determinare il primo e l’ultimo record in ciascun gruppo. In genere il PRIMO.l’indicatore variabile viene utilizzato per inizializzare le statistiche di riepilogo e per ricordare i valori iniziali della misurazione.L’ULTIMO.l’indicatore variabile viene utilizzato per produrre il risultato dei calcoli, che spesso include semplici statistiche descrittive come una somma, una differenza, valori massimi, minimi o medi.
L’elaborazione per gruppo nella fase dei DATI è un argomento comune che viene presentato alle conferenze SAS. Alcuni autori usano FIRST.BY e LAST.BY come il nome delle variabili dell’indicatore. Per ulteriori letture, raccomando il documento “The Power of the BY Statement” (Choate e Dunn, 2007). SAS fornisce anche diversi esempi sull’elaborazione PER gruppo nella fase DATI SAS, tra cui quanto segue:
- Trasporta i valori non mancanti in un gruppo
- Usa i gruppi per trasporre i dati da lunghi a larghi
- Seleziona un numero specificato di osservazioni dalla parte superiore di ciascun gruppo
Tag Per iniziare la programmazione SAS