Bioinformatikk innebærer integrering av datamaskiner, programvareverktøy og databaser i et forsøk på å løse biologiske spørsmål. Bioinformatikk tilnærminger brukes ofte til store tiltak som genererer store datasett. To viktige storskala aktiviteter som bruker bioinformatikk er genomikk og proteomikk. Genomikk refererer til analysen av genomer. Et genom kan betraktes som det komplette settet AV DNA-sekvenser som koder for arvelig materiale som overføres fra generasjon til generasjon. DISSE DNA-sekvensene inkluderer alle genene (den funksjonelle og fysiske enheten av arvelighet som går fra foreldre til avkom) og transkripsjoner (RNA-kopiene som er det første trinnet i dekoding av genetisk informasjon) inkludert i genomet. Således refererer genomikk til sekvensering og analyse av alle disse genomiske enhetene, inkludert gener og transkripsjoner, i en organisme. Proteomikk, derimot, refererer til analysen av hele settet av proteiner eller proteom. I tillegg til genomikk og proteomikk er det mange flere områder av biologi der bioinformatikk blir brukt (dvs.e., metabolomikk, transkriptomikk). Hvert av disse viktige områdene i bioinformatikk tar sikte på å forstå komplekse biologiske systemer.
Mange forskere i dag refererer til den neste bølgen i bioinformatikk som systembiologi, en tilnærming til å takle nye og komplekse biologiske spørsmål. Systembiologi innebærer integrering av genomikk, proteomikk og bioinformatikkinformasjon for å skape et helt systemvisning av en biologisk enhet.
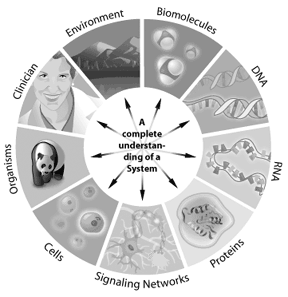
for eksempel kan hvordan en signalvei fungerer i en celle løses gjennom systembiologi. Genene som er involvert i banen, hvordan de samhandler, og hvordan modifikasjoner endrer resultatene nedstrøms, kan alle modelleres ved hjelp av systembiologi. Ethvert system der informasjonen kan representeres digitalt, gir en potensiell søknad om bioinformatikk. Dermed kan bioinformatikk brukes fra enkeltceller til hele økosystemer. Ved å forstå de komplette «dellister» i et genom, får forskere en bedre forståelse av komplekse biologiske systemer. Å forstå samspillet som oppstår mellom alle disse delene i et genom eller proteom representerer neste nivå av kompleksitet i systemet. Gjennom disse tilnærmingene har bioinformatikk potensial til å tilby nøkkelinnsikt i vår forståelse og modellering av hvordan spesifikke menneskelige sykdommer eller sunne tilstander manifesterer seg.
begynnelsen av bioinformatikk kan spores tilbake Til Margaret Dayhoff i 1968 og hennes samling av proteinsekvenser kjent som Atlas Of Protein Sequence and Structure. En av de tidlige betydelige eksperimenter i bioinformatikk var anvendelsen av en sekvens likhet søker program til identifisering av opprinnelsen til en viral gen. I denne studien brukte forskere en av de første sekvenslikhetssøkende dataprogrammene (KALT FASTP), for å fastslå at innholdet i v-sis, en kreftfremkallende viral sekvens, var mest lik det godt karakteriserte CELLULÆRE PDGF-genet. Dette overraskende resultatet ga viktig mekanistisk innsikt for biologer som arbeider med hvordan denne virale sekvensen forårsaker kreft. Fra denne første innledende applikasjonen av datamaskiner til biologi har feltet bioinformatikk eksplodert. Veksten av bioinformatikk er parallell med utviklingen AV DNA-sekvenseringsteknologi. PÅ samme måte som utviklingen av mikroskopet på slutten av 1600-tallet revolusjonerte biologiske vitenskaper ved å la Anton Van Leeuwenhoek se på celler for første gang, HAR DNA-sekvenseringsteknologi revolusjonert feltet bioinformatikk. Den raske veksten av bioinformatikk kan illustreres ved veksten AV DNA-sekvenser som finnes i det offentlige depotet av nukleotidsekvenser kalt GenBank.
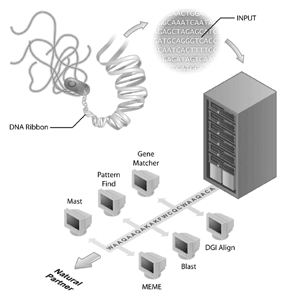
Genomsekvenseringsprosjekter har blitt flaggskipene til mange bioinformatikkinitiativer. Human genome sequencing project er et eksempel på et vellykket genomsekvenseringsprosjekt, men mange andre genomer har også blitt sekvensert og blir sekvensert. Faktisk var de første genomene som ble sekvensert av virus (dvs . MS2) og bakterier, med genomet Av Haemophilus influenzae Rd som det første genomet av en fri levende organisme som skal deponeres i de offentlige sekvensdatabankene. Denne prestasjonen ble mottatt med mindre fanfare enn ferdigstillelsen av det menneskelige genomet, men det blir klart at sekvensering av andre genomer er et viktig skritt for bioinformatikk i dag. Imidlertid har genomsekvensen i seg selv begrenset informasjon. For å tolke genomisk informasjon må komparativ analyse av sekvenser gjøres, og et viktig reagens for disse analysene er de offentlig tilgjengelige sekvensdatabasene. Uten databasene av sekvenser( Som GenBank), der biologer har fanget informasjon om deres interessesekvens, ville mye av den rike informasjonen fra genomsekvenseringsprosjekter ikke være tilgjengelig.
på samme måte utviklingen i mikroskopi bebudet funn i cellebiologi, nye funn i informasjonsteknologi og molekylærbiologi er bebudet funn i bioinformatikk. Faktisk er en viktig del av feltet bioinformatikk utviklingen av ny teknologi som gjør det mulig for vitenskapen om bioinformatikk å fortsette i et veldig raskt tempo. På datasiden Har Internett, ny programvareutvikling, nye algoritmer og utvikling av dataklyngeteknologi gjort det mulig for bioinformatikk å gjøre store sprang når det gjelder mengden data som kan analyseres effektivt. På laboratoriesiden har nye teknologier og metoder som DNA-sekvensering, seriell analyse av genuttrykk (SAGE), mikroarrays og nye massespektrometri kjemikalier utviklet seg i et like blærende tempo som gjør det mulig for forskere å produsere data for analyser med en utrolig hastighet. Bioinformatikk gir både plattformteknologier som gjør det mulig for forskere å håndtere de store mengdene data som produseres gjennom genomikk og proteomikkinitiativer, samt tilnærmingen til å tolke disse dataene. På mange måter gir bioinformatikk verktøyene for å anvende vitenskapelig metode til storskala data og bør ses som en vitenskapelig tilnærming for å stille mange nye og forskjellige typer biologiske spørsmål.
ordet bioinformatikk har blitt et veldig populært «buzz» ord i vitenskapen. Mange forskere finner bioinformatikk spennende fordi det har potensial til å dykke inn i en helt ny verden av ukjent territorium. Bioinformatikk er en ny vitenskap og en ny måte å tenke på som potensielt kan føre til mange relevante biologiske funn. Selv om teknologi muliggjør bioinformatikk, er bioinformatikk fortsatt veldig mye om biologi. Biologiske spørsmål kjøre alle bioinformatikk eksperimenter. Viktige biologiske spørsmål kan tas opp av bioinformatikk og inkluderer forståelse av genotype-fenotypeforbindelsen for menneskelig sykdom, forståelse av struktur for å fungere relasjoner for proteiner og forståelse av biologiske nettverk. Bioinformatikere finner ofte at reagensene som er nødvendige for å svare på disse interessante biologiske spørsmålene, ikke eksisterer. Dermed er en stor del av en bioinformatikers jobb å bygge verktøy og teknologier som en del av prosessen med å stille spørsmålet. For mange er bioinformatikk veldig populært fordi forskere kan bruke både biologi og datakompetanse til å utvikle reagenser for bioinformatikkforskning. Mange forskere finner at bioinformatikk er et spennende nytt territorium av vitenskapelig spørsmål med stort potensial til fordel for menneskers helse og samfunn.
fremtiden for bioinformatikk er integrasjon. For eksempel vil integrering av et bredt spekter av datakilder som kliniske og genomiske data tillate oss å bruke sykdomssymptomer for å forutsi genetiske mutasjoner og omvendt. Integrasjonen AV GIS-data, for eksempel kart, værsystemer, med avlingshelse og genotypedata, vil tillate oss å forutsi vellykkede resultater av landbrukseksperimenter. Et annet fremtidig forskningsområde innen bioinformatikk er storskala komparativ genomikk. For eksempel, utvikling av verktøy som kan gjøre 10-veis sammenligninger av genomer vil presse frem oppdagelsen rate i dette feltet av bioinformatikk. Langs disse linjene kan modellering og visualisering av fulle nettverk av komplekse systemer brukes i fremtiden for å forutsi hvordan systemet (eller cellen) reagerer, for eksempel på et stoff. Et teknisk sett med utfordringer står overfor bioinformatikk og blir adressert av raskere datamaskiner, teknologiske fremskritt innen diskplass og økt båndbredde, men langt en av de største hindrene for bioinformatikk i dag, er det lille antallet forskere på feltet. Dette endrer seg som bioinformatikk beveger seg til forkant av forskning, men dette etterslep i kompetanse har ført til reelle hull i kunnskap om bioinformatikk i forskningsmiljøet. Til slutt vil et sentralt forskningsspørsmål for fremtiden for bioinformatikk være hvordan man beregningsmessig sammenligner komplekse biologiske observasjoner, for eksempel genuttrykksmønstre og proteinnettverk. Bioinformatikk handler om å konvertere biologiske observasjoner til en modell som en datamaskin vil forstå. Dette er en svært utfordrende oppgave siden biologi kan være svært komplisert. Dette problemet med å digitalisere fenotypiske data som atferd, elektrokardiogrammer og beskjære helse til en datamaskinlesbar form gir spennende utfordringer for fremtidige bioinformatikere.
(denne artikkelen er basert på et intervju Med Francis Ouellette, Direktør FOR UBC Bioinformatics Centre)