Bioinformatica omvat de integratie van computers, softwaretools en databases in een poging om biologische kwesties aan te pakken. De benaderingen van de bio-informatica worden vaak gebruikt voor belangrijke initiatieven die grote gegevensreeksen produceren. Twee belangrijke grootschalige activiteiten die bio-informatica gebruiken zijn genomica en proteomica. De Genomica verwijst naar de analyse van genomen. Een genoom kan als volledige reeks opeenvolgingen van DNA worden gedacht die voor het erfelijke materiaal codeert dat van generatie aan generatie wordt doorgegeven. Deze opeenvolgingen van DNA omvatten alle genen (de functionele en fysieke eenheid van erfelijkheid die van ouder aan nakomelingen wordt overgegaan) en afschriften (de kopieën van RNA die de eerste stap in het decoderen van de genetische informatie zijn) binnen het genoom wordt inbegrepen. Aldus, verwijst de Genomica naar het rangschikken en analyse van al deze genomic entiteiten, met inbegrip van genen en afschriften, in een organisme. Proteomics, anderzijds, verwijst naar de analyse van de volledige reeks proteã NEN of proteome. Naast genomica en proteomica, zijn er veel meer gebieden van biologie waar Bioinformatica wordt toegepast (i.e., metabolomics, transcriptomics). Elk van deze belangrijke gebieden in Bioinformatica beoogt complexe biologische systemen te begrijpen. Veel wetenschappers verwijzen vandaag naar de volgende golf in de bio-informatica als systeembiologie, een aanpak om nieuwe en complexe biologische vraagstukken aan te pakken. De systeembiologie impliceert de integratie van genomics, proteomics, en Bioinformatica informatie om een gehele systeemmening van een biologische entiteit tot stand te brengen.
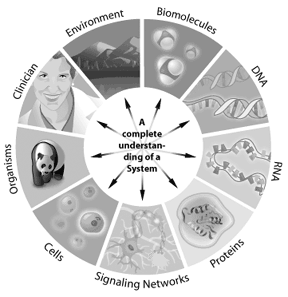
bijvoorbeeld, hoe een signaalweg in een cel werkt, kan worden aangepakt door middel van systeembiologie. De genen betrokken bij de weg, hoe zij op elkaar inwerken, en hoe wijzigingen de resultaten stroomafwaarts veranderen, kunnen allen worden gemodelleerd gebruikend systeembiologie. Om het even welk systeem waar de informatie digitaal kan worden vertegenwoordigd biedt een potentiële toepassing voor Bioinformatica aan. Zo kan de bio-informatica van enige cellen op gehele ecosystemen worden toegepast. Door de volledige “onderdelenlijsten” in een genoom te begrijpen, krijgen de wetenschappers een beter begrip van complexe biologische systemen. Het begrijpen van de interactie die tussen elk van deze delen in een genoom of proteome voorkomen vertegenwoordigt het volgende niveau van ingewikkeldheid in het systeem. Door deze benaderingen, heeft de bioinformatica het potentieel om zeer belangrijke inzichten in ons begrip en modellering van aan te bieden hoe specifieke menselijke ziekten of gezonde Staten zich manifesteren. Het begin van de bio-informatica kan worden teruggevoerd op Margaret Dayhoff in 1968 en haar verzameling van eiwitsequenties bekend als de Atlas of Protein Sequence and Structure. Één van de vroege significante experimenten in Bioinformatica was de toepassing van een opeenvolgings gelijkenis het zoeken programma aan de identificatie van de oorsprong van een viraal gen. In deze studie, gebruikten wetenschappers een van de eerste sequentie gelijkenis zoeken computerprogramma ‘ s (genaamd FASTP), om te bepalen dat de inhoud van v-sis, een kanker-veroorzakende virale sequentie, waren het meest vergelijkbaar met de goed gekarakteriseerde cellulaire PDGF gen. Dit verrassende resultaat leverde belangrijke mechanistische inzichten op voor biologen die werken aan hoe deze virale sequentie kanker veroorzaakt. Vanaf deze eerste eerste toepassing van computers op de biologie, is het gebied van de bio-informatica geëxplodeerd. De groei van bio-informatica is parallel aan de ontwikkeling van DNA die technologie rangschikken. Net zoals de ontwikkeling van de microscoop eind 1600 de biologische wetenschappen revolutioneerde door Anton van Leeuwenhoek voor het eerst naar cellen te laten kijken, heeft DNA-sequencingtechnologie een revolutie teweeggebracht op het gebied van de bioinformatica. De snelle groei van Bioinformatica kan door de groei van de opeenvolgingen van DNA worden geïllustreerd die in het openbare register van nucleotideopvolgingen genoemd GenBank worden vervat.
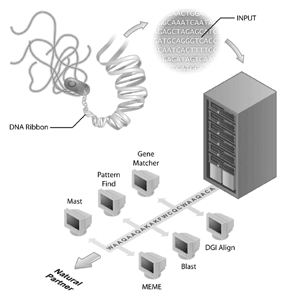
Genome sequencing projecten zijn uitgegroeid tot de vlaggenschepen van vele Bioinformatica initiatieven. Het menselijke genoom die project rangschikken is een voorbeeld van een succesvol genoom rangschikkend project maar vele andere genomen zijn ook gerangschikt en worden gerangschikt. In feite, waren de eerste te rangschikken genomen van virussen (d.w.z., de faag MS2) en bacteriën, waarbij het genoom van Haemophilus influenzae Rd het eerste genoom van een vrij levend organisme is dat in de openbare sequentiedatabanken wordt gedeponeerd. Deze verwezenlijking werd ontvangen met minder fanfare dan de voltooiing van het menselijke genoom maar het wordt duidelijk dat het rangschikken van andere genomen vandaag een belangrijke stap voor Bioinformatica is. Nochtans, heeft de genoomopeenvolging door zelf beperkte informatie. Om genomische informatie te interpreteren, moet de vergelijkende analyse van opeenvolgingen worden gedaan en een belangrijk reagens voor deze analyses zijn de publiek toegankelijke opeenvolgingsdatabases. Zonder de gegevensbestanden van opeenvolgingen( zoals GenBank), waarin biologen informatie over hun opeenvolging van belang hebben gevangen, zou veel van de rijke die informatie uit genoom wordt verkregen die projecten rangschikken niet beschikbaar zijn.Op dezelfde manier als de ontwikkelingen in de microscopie de ontdekkingen in de celbiologie voorafschaduwden, zijn nieuwe ontdekkingen in de informatietechnologie en de moleculaire biologie de voorlopers van ontdekkingen in de bio-informatica. In feite, is een belangrijk deel van het gebied van Bioinformatica de ontwikkeling van nieuwe technologie die de wetenschap van Bioinformatica toestaat om in een zeer snel tempo te gaan. Aan de computerkant hebben het Internet, Nieuwe softwareontwikkelingen, nieuwe algoritmen, en de ontwikkeling van computerclustertechnologie bioinformatica in staat gesteld om grote sprongen te maken in termen van de hoeveelheid gegevens die efficiënt kan worden geanalyseerd. Aan de kant van het laboratorium, hebben de nieuwe technologieën en methodes zoals het rangschikken van DNA, periodieke analyse van genuitdrukking (salie), microarrays, en nieuwe massaspectrometrie chemistries zich in een even blaarterend tempo ontwikkeld die wetenschappers toelaten om gegevens voor analyses aan een ongelooflijk tarief te produceren. De bioinformatica verstrekt zowel de platformtechnologieën die wetenschappers toelaten om de grote hoeveelheden gegevens te behandelen die door genomics en proteomics initiatieven evenals de benadering worden geproduceerd om deze gegevens te interpreteren. Op vele manieren, verstrekt de bioinformatica de hulpmiddelen voor het toepassen van wetenschappelijke methode op gegevens op grote schaal en zou als een wetenschappelijke benadering moeten worden gezien om vele nieuwe en verschillende soorten biologische vragen te stellen.
het woord Bioinformatica is een zeer populair “buzz” woord in de wetenschap geworden. Veel wetenschappers vinden bio-informatica spannend omdat het de potentie heeft om te duiken in een hele nieuwe wereld van onbekend terrein. De bio-informatica is een nieuwe wetenschap en een nieuwe manier van denken die potentieel tot vele relevante biologische ontdekkingen zou kunnen leiden. Hoewel de technologie bio-informatica toelaat, gaat de bio-informatica nog steeds zeer over biologie. Biologische vragen drijven alle Bioinformatica experimenten aan. De belangrijke biologische vragen kunnen door Bioinformatica worden aangepakt en omvatten het begrijpen van de genotype-fenotype verbinding voor menselijke ziekte, het begrijpen van structuur om verhoudingen voor proteã nen te functioneren, en het begrijpen van biologische netwerken. Bioinformatici vinden vaak dat de reagentia die nodig zijn om deze interessante biologische vragen te beantwoorden niet bestaan. Aldus, bouwt een groot deel van de baan van een bioinformaticus hulpmiddelen en technologieën als deel van het proces om de vraag te stellen. Voor velen, is de bio-informatica zeer populair omdat de wetenschappers zowel hun biologie als computervaardigheden op het ontwikkelen van reagentia voor bio-informaticaonderzoek kunnen toepassen. Vele wetenschappers vinden dat de bio-informatica een opwindend nieuw gebied van wetenschappelijke vraagstelling met groot potentieel is om de menselijke gezondheid en de samenleving ten goede te komen.
de toekomst van de bio-informatica is integratie. Bijvoorbeeld, de integratie van een grote verscheidenheid van gegevensbronnen zoals klinische en genomische gegevens zal ons toelaten om ziektesymptomen te gebruiken om genetische veranderingen te voorspellen en vice versa. De integratie van GIS-gegevens, zoals kaarten, weersystemen, met gegevens over gewasgezondheid en genotype, zal ons in staat stellen om succesvolle resultaten van landbouwexperimenten te voorspellen. Een ander toekomstig gebied van onderzoek in bio-informatica is vergelijkende genomica op grote schaal. Bijvoorbeeld, zal de ontwikkeling van hulpmiddelen die 10-maniervergelijkingen van genomen kunnen doen het ontdekkingstarief op dit gebied van Bioinformatica vooruit duwen. Langs deze lijnen, kan de modellering en visualisatie van volledige netwerken van complexe systemen in de toekomst worden gebruikt om te voorspellen hoe het systeem (of cel) reageert, op een medicijn, bijvoorbeeld. Een technische reeks uitdagingen wordt geconfronteerd met bio-informatica en wordt aangepakt door snellere computers, technologische vooruitgang in schijfopslag, en verhoogde bandbreedte, maar veruit een van de grootste hindernissen geconfronteerd met bio-informatica vandaag, is het kleine aantal onderzoekers in het veld. Dit verandert aangezien bio-informatica zich aan het voorfront van onderzoek beweegt maar deze vertraging in deskundigheid heeft tot echte hiaten in de kennis van bio-informatica in de onderzoeksgemeenschap geleid. Tot slot zal een belangrijke onderzoeksvraag voor de toekomst van de bio-informatica zijn hoe complexe biologische observaties, zoals genexpressiepatronen en eiwitnetwerken, computationeel kunnen worden vergeleken. Bio-informatica gaat over het omzetten van biologische observaties naar een model dat een computer zal begrijpen. Dit is een zeer uitdagende taak aangezien biologie zeer complex kan zijn. Dit probleem van het digitaliseren van fenotypische gegevens zoals gedrag, elektrocardiogrammen en gewasgezondheid in een computer leesbare vorm biedt spannende uitdagingen voor toekomstige bioinformatici.
(dit artikel is gebaseerd op een interview met Francis Ouellette, directeur van het UBC Bioinformatics Centre)