bioinformatika zahrnuje integraci počítačů, softwarových nástrojů a databází ve snaze řešit biologické otázky. Bioinformatika přístupy jsou často používány pro velké iniciativy, které generují velké datové sady. Dvě důležité rozsáhlé činnosti, které používají bioinformatiku, jsou genomika a proteomika. Genomika se týká analýzy genomů. Genom lze považovat za kompletní sadu sekvencí DNA, které kódují dědičný materiál, který se předává z generace na generaci. Tyto sekvence DNA obsahuje všechny geny (funkční a fyzikální jednotka dědičnosti předán z rodičů na potomky) a transkriptů (RNA kopií, které jsou prvním krokem při dekódování genetické informace) zahrnuty v rámci genomu. Genomika tedy označuje sekvenování a analýzu všech těchto genomických entit, včetně genů a transkriptů, v organismu. Proteomika se na druhé straně týká analýzy kompletní sady proteinů nebo proteomu. Kromě genomiky a proteomiky existuje mnoho dalších oblastí biologie, kde se bioinformatika aplikuje (i .e., metabolomika, transkriptomika). Každá z těchto důležitých oblastí v bioinformatice si klade za cíl porozumět komplexním biologickým systémům.
mnoho vědců dnes označuje další vlnu v bioinformatice jako systémovou biologii, přístup k řešení nových a složitých biologických otázek. Systémová biologie zahrnuje integraci informací o genomice, proteomice a bioinformatice, aby se vytvořil celý systémový pohled na biologickou entitu.
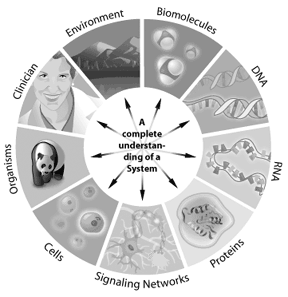
například, jak funguje signální dráha v buňce, lze řešit prostřednictvím systémové biologie. Geny zapojené do dráhy, jak interagují, a jak modifikace mění výsledky po proudu, vše lze modelovat pomocí systémové biologie. Jakýkoli systém, kde lze informace digitálně reprezentovat, nabízí potenciální aplikaci pro bioinformatiku. Bioinformatika tak může být aplikována z jednotlivých buněk na celé ekosystémy. Pochopením úplných „seznamů částí“ v genomu získávají vědci lepší porozumění složitým biologickým systémům. Pochopení interakcí, ke kterým dochází mezi všemi těmito částmi v genomu nebo proteomu, představuje další úroveň složitosti v systému. Prostřednictvím těchto přístupů, bioinformatika má potenciál nabídnout klíčové poznatky o našem porozumění a modelování toho, jak se projevují konkrétní lidské nemoci nebo zdravé stavy.
Počátek bioinformatiky lze vysledovat až k Margaret Dayhoffové v roce 1968 a její sbírce proteinových sekvencí známých jako Atlas proteinové sekvence a struktury. Jedním z prvních významných experimentů v bioinformatice byla aplikace programu Vyhledávání podobnosti sekvencí k identifikaci původu virového genu. V této studii vědci použili jeden z prvních sekvenční podobnost vyhledávání počítačové programy (tzv. FASTP), aby se zjistilo, že obsah v-sis, způsobující rakovinu virové sekvence, jsou většinou podobné dobře charakterizovaných buněčných PDGF gen. Tento překvapivý výsledek poskytl důležité mechanistické poznatky biologům pracujícím na tom, jak tato virová sekvence způsobuje rakovinu. Od této první počáteční aplikace počítačů do biologie explodovala oblast bioinformatiky. Růst bioinformatiky je paralelní s vývojem technologie sekvenování DNA. Stejným způsobem, že vývoj mikroskopu v pozdní 1600 revoluci biologických věd tím, Anton Van Leeuwenhoek se podívat na buňky poprvé, sekvenování DNA technologie revoluci v oblasti bioinformatiky. Rychlý růst bioinformatiky lze ilustrovat růstem DNA sekvencí obsažených ve veřejném úložišti nukleotidových sekvencí zvaných GenBank.
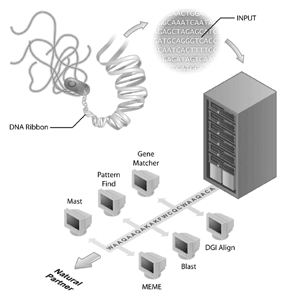
projekty sekvenování genomu se staly vlajkovými loděmi mnoha bioinformatických iniciativ. Lidského genomu sekvenování projekt je příkladem úspěšné sekvenování genomu projektu, ale mnoho dalších genomů byly také sekvenovány a jsou sekvenovány. Ve skutečnosti byly první genomy, které měly být sekvenovány, viry (tj., fág MS2) a bakterií, přičemž genom Haemophilus influenzae Rd je prvním genomem volně žijícího organismu, který má být uložen do databází veřejných sekvencí. Tento úspěch byl přijat s menšími fanfárami než dokončení lidského genomu, ale je jasné, že sekvenování dalších genomů je důležitým krokem pro bioinformatika dnes. Sekvence genomu sama o sobě má však omezené informace. Interpretovat genomické informace, je třeba provést srovnávací analýzu sekvencí a důležitým činidlem pro tyto analýzy jsou veřejně přístupné databáze sekvencí. Bez databází sekvencí (jako GenBank), v němž biologové zachytil informaci o jejich sekvenci zájem, hodně z bohaté informace získané z projektů sekvenování genomu by neměl být k dispozici.
stejně tak vývoj v mikroskopii předznamenal objevy v buněčné biologii, nové objevy v informačních technologiích a molekulární biologii jsou předzvěstí objevů v bioinformatice. Ve skutečnosti je důležitou součástí oblasti bioinformatiky vývoj nových technologií, které umožňují vědě o bioinformatice postupovat velmi rychlým tempem. Na straně počítače, Internet, nový software, vývoj nových algoritmů a vývoj počítačového clusteru technologie umožnila bioinformatika, aby se velké skoky, pokud jde o množství dat, které může být efektivně analyzovány. Na laboratorní straně, nové technologie a metody, jako je např. sekvenování DNA, sériové analýzy genové exprese (SAGE), microarrays, a nové hmotnostní spektrometrie chemie vyvinuli v neméně puchýřů tempo umožňuje vědci k výrobě dat pro analýzy neuvěřitelnou rychlostí. Bioinformatika poskytuje jak platformové technologie, které vědcům umožňují vypořádat se s velkým množstvím dat produkovaných prostřednictvím iniciativ genomiky a proteomiky,tak s přístupem k interpretaci těchto údajů. V mnoha ohledech, bioinformatika poskytuje nástroje pro uplatňování vědecké metody, aby ve velkém měřítku dat a měl by být viděn jako vědecký přístup se ptám mnoho nových a různých typů biologických otázek.
slovo bioinformatika se ve vědě stalo velmi populárním „buzzovým“ slovem. Mnoho vědců považuje bioinformatiku za vzrušující, protože má potenciál ponořit se do zcela nového světa nezmapovaného území. Bioinformatika je nová věda a nový způsob myšlení, který by mohl potenciálně vést k mnoha relevantním biologickým objevům. Ačkoli technologie umožňuje bioinformatiku, bioinformatika je stále velmi o biologii. Biologické otázky řídí všechny bioinformatické experimenty. Důležité biologické otázky mohou být řešeny tím, bioinformatika a zahrnují porozumění genotyp-fenotyp připojení pro lidské nemoci, pochopení struktury, funkce, vztahy pro proteiny, a pochopení biologických sítí. Bioinformatici často zjistí, že činidla nezbytná k zodpovězení těchto zajímavých biologických otázek neexistují. Velká část práce bioinformatika je tedy budování nástrojů a technologií jako součást procesu kladení otázky. Pro mnohé je bioinformatika velmi populární, protože vědci mohou aplikovat jak své biologické, tak počítačové dovednosti na vývoj činidel pro výzkum bioinformatiky. Mnoho vědců zjišťuje, že bioinformatika je vzrušujícím novým územím vědeckého dotazování s velkým potenciálem pro lidské zdraví a společnost.
budoucnost bioinformatiky je integrace. Například, integraci různých zdrojů údajů, jako jsou klinické a genomických dat nám umožní použít příznaky onemocnění předvídat, genetické mutace a naopak. Integrace dat GIS, jako jsou mapy, meteorologické systémy, s údaji o zdraví plodin a genotypu, nám umožní předvídat úspěšné výsledky zemědělských experimentů. Další budoucí oblastí výzkumu v bioinformatice je rozsáhlá srovnávací genomika. Například, vývoj nástrojů, které mohou dělat 10-způsob srovnání genomů bude tlačit dopředu objev sazba v této oblasti bioinformatiky. V tomto směru by modelování a vizualizace plných sítí komplexních systémů mohly být v budoucnu použity k předpovědi toho, jak systém (nebo buňka) reaguje například na lék. Technické problémy tváře bioinformatika a je řešeno prostřednictvím rychlejší počítače, technologický pokrok v úložný prostor na disku, a větší šířku pásma, ale zdaleka jeden z největších překážek, kterým čelí bioinformatika dnes, je malý počet výzkumných pracovníků v oboru. To se mění, protože bioinformatika se pohybuje do popředí výzkumu, ale toto zpoždění v odborných znalostech vedlo ke skutečným mezerám ve znalostech bioinformatiky ve výzkumné komunitě. A konečně, klíčovou výzkumnou otázkou pro budoucnost bioinformatiky bude, jak výpočetně porovnat komplexní biologická pozorování, jako jsou vzorce genové exprese a proteinové sítě. Bioinformatika je o přeměně biologických pozorování na model, kterému počítač porozumí. To je velmi náročný úkol, protože biologie může být velmi složitá. Tento problém, jak digitalizovat fenotypová data, jako je chování, elektrokardiogramy a zdraví plodin, do počítačově čitelné formy, nabízí vzrušující výzvy pro budoucí bioinformatiky.
(Tento článek je založen na rozhovoru s Francisem Ouellette, Ředitel UBC Bioinformatiky Centra)