バイオインフォマティクスは、生物学的な問題に対処するための努力で、コンピュータ、ソフトウェアツール、およびデータベースの統合を含みます。 バイオインフォマティクスアプローチは、大規模なデータセットを生成する主要な取り組みによく使用されます。 バイオインフォマティクスを使用する二つの重要な大規模な活動は、ゲノミクスとプロテオミクスです。 ゲノミクスは、ゲノムの分析を指します。 ゲノムは、世代から世代に渡される遺伝性物質をコードするDNA配列の完全なセットと考えることができます。 これらのDNA配列には、ゲノム内に含まれるすべての遺伝子(親から子孫に渡される遺伝の機能的および物理的単位)および転写物(遺伝情報を解読する したがって、ゲノミクスは、生物における遺伝子および転写物を含むこれらのゲノム実体のすべての配列決定および分析を指す。 プロテオミクスは、一方では、蛋白質またはプロテオームの完全なセットの分析を示します。 ゲノミクスやプロテオミクスに加えて、バイオインフォマティクスが適用されている生物学のより多くの分野があります(i.e.、metabolomics、transcriptomics)。 バイオインフォマティクスにおけるこれらの重要な分野のそれぞれは、複雑な生物学的システムを理解することを目的としています。
今日の多くの科学者は、バイオインフォマティクスの次の波をシステム生物学、新しい複雑な生物学的問題に取り組むためのアプローチと呼んでいます。 システム生物学は、生物学的実体のシステム全体のビューを作成するために、ゲノミクス、プロテオミクス、およびバイオインフォマティクス情報の統合を
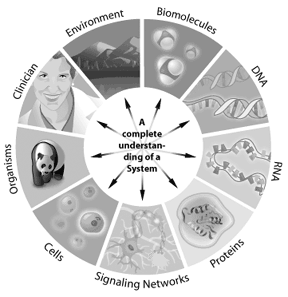
例えば、シグナル伝達経路が細胞内でどのように機能するかは、システム生物学を通じて対処することができます。 経路に関与する遺伝子、それらがどのように相互作用するか、および改変が下流の結果をどのように変化させるかは、すべてシステム生物学を使用 情報をデジタル的に表現できるシステムは、バイオインフォマティクスへの潜在的な応用を提供します。 したがって、バイオインフォマティクスは、単一の細胞から生態系全体に適用することができます。 ゲノム内の完全な”パーツリスト”を理解することによって、科学者は複雑な生物学的システムのより良い理解を得ています。 ゲノムまたはプロテオーム内のこれらの部分のすべての間で起こる相互作用を理解することは、システムの次のレベルの複雑さを表します。 これらのアプローチを通じて、バイオインフォマティクスは、特定の人間の病気や健康状態がどのように現れているかを理解し、モデル化するための鍵となる洞察を提供する可能性を秘めています。
バイオインフォマティクスの始まりは、1968年のMargaret Dayhoffと、Atlas of Protein Sequence and Structureとして知られるタンパク質配列のコレクションにさかのぼることができます。 バイオインフォマティクスにおける初期の重要な実験の一つは、ウイルス遺伝子の起源の同定に配列類似性探索プログラムの適用であった。 この研究では、科学者は、癌を引き起こすウイルス配列であるv-sisの内容が、よく特徴付けられた細胞PDGF遺伝子に最も類似していることを決定するため この驚くべき結果は、このウイルス配列がどのように癌を引き起こすかに取り組んでいる生物学者に重要な機序的洞察を提供した。 コンピュータの生物学へのこの最初の最初の応用から、バイオインフォマティクスの分野は爆発しました。 バイオインフォマティクスの成長は、DNAシークエンシング技術の開発と並行しています。 1600年代後半の顕微鏡の開発がAnton Van Leeuwenhoekが初めて細胞を見ることを可能にすることによって生物科学に革命をもたらしたのと同じように、DNAシークエンシ バイオインフォマティクスの急速な成長は、GenBankと呼ばれるヌクレオチド配列の公開リポジトリに含まれるDNA配列の成長によって説明することがで
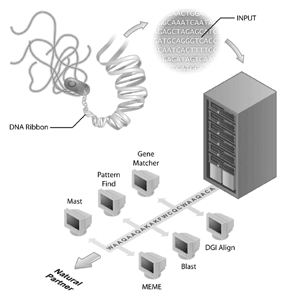
ゲノム配列決定プロジェクトは、多くのバイオインフォマティクスの取り組みの旗艦となっています。 ヒトゲノムシークエンシングプロジェクトは、成功したゲノムシークエンシングプロジェクトの一例ですが、他の多くのゲノムも配列決定されており、配列決定されています。 実際には、配列決定される最初のゲノムは、ウイルスのものであった(すなわち、、ファージMS2)および細菌、Haemophilus influenzae Rdのゲノムは、公共の配列データバンクに寄託される自由な生きている生物の最初のゲノムである。 この成果は、ヒトゲノムの完成よりも少ないファンファーレで受信されたが、それは他のゲノムの配列決定は、今日のバイオインフォマティクスのための重要なステップであることが明らかになってきています。 しかし、ゲノム配列自体は限られた情報を持っています。 ゲノム情報を解釈するためには、配列の比較分析を行う必要があり、これらの分析のための重要な試薬は、公的にアクセス可能な配列データベースである。 生物学者が関心のある配列に関する情報を取得している配列のデータベース(GenBankなど)がなければ、ゲノムシーケンスプロジェクトから得られた豊富な情報の多くは利用できないだろう。
顕微鏡の開発が細胞生物学の発見を予感させたのと同じように、情報技術や分子生物学の新しい発見がバイオインフォマティクスの発見を予感させている。 実際には、バイオインフォマティクスの分野の重要な部分は、バイオインフォマティクスの科学が非常に速いペースで進行することを可能にする新 コンピュータ側では、インターネット、新しいソフトウェア開発、新しいアルゴリズム、およびコンピュータクラスタ技術の開発により、バイオインフォマティクスは効率的に分析できるデータ量の点で大きな飛躍を遂げています。 実験室側では、DNAシークエンシング、遺伝子発現の連続分析(SAGE)、マイクロアレイ、新しい質量分析化学などの新しい技術や方法は、科学者が信じられないほど バイオインフォマティクスは、科学者がゲノミクスやプロテオミクスの取り組みを通じて生成された大量のデータに対処することを可能にするプラ 多くの点で、バイオインフォマティクスは、大規模なデータに科学的方法を適用するためのツールを提供し、多くの新しい、異なるタイプの生物学的問
バイオインフォマティクスという言葉は、科学で非常に人気のある”話題”の言葉になっています。 それは未知の領域の全く新しい世界に飛び込む可能性を保持しているので、多くの科学者は、バイオインフォマティクスは刺激的な見つけます。 バイオインフォマティクスは、新しい科学であり、潜在的に多くの関連する生物学的発見につながる可能性のある新しい考え方です。 技術はバイオインフォマティクスを可能にしますが、バイオインフォマティクスはまだ生物学につい 生物学的な質問は、すべてのバイオインフォマティクス実験を駆動します。 重要な生物学的問題は、バイオインフォマティクスによって対処することができ、ヒト疾患の遺伝子型-表現型の接続を理解し、タンパク質の関係を機能させるための構造を理解し、生物学的ネットワークを理解することが含まれます。 Bioinformaticiansは頻繁にこれらの興味深い生物的質問に答えるのに必要な試薬が存在しないことが分る。 したがって、バイオインフォマティシャンの仕事の大部分は、質問をするプロセスの一環としてツールと技術を構築することです。 多くの人にとって、バイオインフォマティクスは、科学者がバイオインフォマティクス研究のための試薬の開発に生物学とコンピュータスキルの両方を適用することができるため、非常に人気があります。 多くの科学者は、バイオインフォマティクスは、人間の健康と社会に利益をもたらす大きな可能性を秘めた科学的質問の刺激的な新しい領域である
バイオインフォマティクスの未来は統合です。 例えば、臨床データやゲノムデータなどの多種多様なデータソースを統合することで、病気の症状を使用して遺伝的変異を予測したり、その逆を予測したりすることができるようになります。 地図、気象システムなどのGISデータと作物の健康状態や遺伝子型データを統合することで、農業実験の成功した結果を予測することができます。 バイオインフォマティクスの研究のもう一つの将来の分野は、大規模な比較ゲノミクスです。 例えば、ゲノムの10方向の比較を行うことができるツールの開発は、バイオインフォマティクスのこの分野での発見率を前進させるでしょう。 これらの線に沿って、複雑なシステムの完全なネットワークのモデリングと可視化は、例えば、システム(または細胞)が薬物にどのように反応するかを予 技術的な課題のセットは、バイオインフォマティクスに直面しており、高速なコンピュータ、ディスクストレージスペースの技術的進歩、および帯域幅の増加によ これは、バイオインフォマティクスが研究の最前線に移動するにつれて変化していますが、専門知識のこの遅れは、研究コミュニティにおけるバイオインフォマティクスの知識の本当のギャップにつながっています。 最後に、バイオインフォマティクスの将来の重要な研究課題は、遺伝子発現パターンやタンパク質ネットワークなどの複雑な生物学的観察を計算的に比較 バイオインフォマティクスは、生物学的観測をコンピュータが理解するモデルに変換することです。 生物学は非常に複雑になる可能性があるため、これは非常に困難な作業です。 このような行動、心電図、およびコンピュータ可読形式に作物の健康などの表現型データをデジタル化する方法のこの問題は、将来のバイオインフォマ
(この記事は、UbcバイオインフォマティクスセンターのFrancis Ouelletteディレクターとのインタビューに基づいています)