mijn artikel over het verschil tussen klasse variabelen en door variabelen in SAS gericht op SAS analytische procedures. De BY-verklaring is echter ook nuttig in de SAS-gegevensstap, waar het wordt gebruikt om datasets samen te voegen en gegevens op groepsniveau te analyseren. Wanneer u de BY statement in de DATA stap, de data stap maakt twee tijdelijke indicator variabelen voor elke variabele in de BY statement. De namen van deze variabelen zijn de eerste.variabel en laatste.variabele, waarbij variabele is de naam van een variabele in de door statement. Bijvoorbeeld, als u de verklaring per geslacht gebruikt, dan zijn de namen van de indicatorvariabelen eerst.Seks en laatste.Sex.
dit artikel geeft verschillende voorbeelden van het gebruik van het eerste.variabel en laatste.variabele indicatorvariables voor groepsanalyse in de SAS-gegevensstap.Het eerste voorbeeld laat zien hoe tellingen en cumulatieve bedragen voor elke groep te berekenen. Het tweede voorbeeld laat zien hoe de tijd tussen het eerste en laatste bezoek van een patiënt aan een kliniek wordt berekend, evenals de verandering in een gemeten hoeveelheid tussen het eerste en laatste bezoek.
eerst gebruiken. en als laatste. variabelen om de grootte van groepen
te vinden het eerste voorbeeld gebruikt gegevens uit de Sashelp.Hartgegevenset, die gegevens bevat voor 5.209 patiënten in een medisch onderzoek naar hartziekten. De gegevens worden verspreid met SAS. De volgende GEGEVENSSTAP extraheert de Smoking_Status en gewicht variabelen en sorteert de gegevens door de Smoking_Status variabele:
proc sorteer data=Sashelp.Heart (keep=Smoking_Status Weight) out = Heart; by Smoking_Status; run;
omdat de gegevens gesorteerd zijn op de Smoking_Status variabele, kun je de eerste gebruiken.Smoking_Status en laatste.Smoking_Status tijdelijke variabelen om het aantal waarnemingen in elk niveau van de Smoking_Status variabele te tellen. (PROC FREQ berekent dezelfde informatie, maar vereist geen gesorteerde gegevens.) Wanneer u gebruik maakt van de door Smoking_Status statement, de data stap maakt automatisch de eerste.Smoking_Status en laatste.Smoking_Status indicator variabelen. Zoals de naam al aangeeft, de eerste.Smoking_Status variabele heeft de waarde 1 voor de eerste waarneming in elke groep en de waarde 0 anders.(Beter gezegd, de waarde is 1 Voor het eerste record en voor records waarvoor de Smoking_Status variabele anders is dan voor het vorige record.) Ook de laatste.Smoking_Status indicator variabele heeft de waarde 1 voor de laatste waarneming in elke groep en 0 anders.
de volgende GEGEVENSSTAP definieert een variabele met de naam Count en initialiseert Count = 0 aan het begin van elke groep. Voor elke waarneming in de per groep wordt de Count variabele met 1 verhoogd. Wanneer de laatste record in elke per groep wordt gelezen, wordt die record geschreven naar de Count data set.
data Count; set Heart; / * data worden gesorteerd op Smoking_Status * / door Smoking_Status; / * maakt automatisch indicator vars * / als eerste.Smoking_Status dan Count = 0; / * initialiseer telling aan het begin van elke groep * / Count + 1; / * increment Count voor elke record * / als laatste.Smoking_Status; / * alleen de laatste record van elke groep uitvoeren * / run; proc print data = Count noobs; format Count komma10.; var Smoking_Status Count; run;
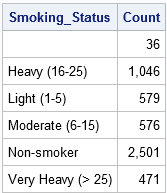
te tellen met dezelfde techniek kunt u waarden van een variabele binnen een groep verzamelen. U kunt bijvoorbeeld het totale gewicht van alle patiënten in elke rookgroep ophopen met behulp van de volgende verklaringen:
als eerste.Smoking_Status dan cumWt = 0; cumWt + gewicht;
deze zelfde techniek kan worden gebruikt om inkomsten uit verschillende bronnen, zoals afdelingen, winkels, of regio ‘ s accumuleren.
eerst gebruiken. en als laatste. variabelen om de behandelingsduur
te berekenen.variabel en laatste.variabele indicator variabelen is om de lengte van de tijd te bepalen tussen het eerste bezoek van een patiënt en zijn laatste bezoek. Overweeg de volgende GEGEVENSSTAP, die de data en gewichten definieert voor vier mannelijke patiënten die een kliniek bezochten als onderdeel van een gewichtsverlies programma:
gegevens patiënten;informatie Datum datum 7.; format Date date7. Patiënt Z4.;input PatientID Datum Gewicht @@;datalijnen;1021 04Jan16 302 1042 06Jan16 2851053 07Jan16 325 1063 11Jan16 2911053 01Feb16 1021 299 01Feb16 2881063 09Feb16 283 1042 16Feb16 2791021 07Mar16 280 1063 09Mar16 2721042 28Mar16 272 1021 04Apr16 2731063 20Apr16 270 1053 28Apr16 2891053 13May16 295 1063 31May16 269;
Voor deze gegevens, kunt u sorteren door de patiënt-ID en de datum van het bezoek. Na het sorteren bevat de eerste opname voor elke patiënt het eerste bezoek aan de kliniek en de laatste opname Het Laatste bezoek. U kunt het gewicht van de patiënt Aftrekken voor deze data om te bepalen hoeveel de patiënt gewonnen of verloren tijdens het onderzoek. U kunt ook de INTCK-functie gebruiken om de verstreken tijd tussen bezoeken te berekenen. Als u de tijd in dagen wilt meten, kunt u eenvoudig de datums Aftrekken, maar met de INTCK-functie kunt u de duur berekenen in termen van jaren, maanden, weken en andere tijdseenheden.
proc sortage data = Patients; by PatientID Date; run; data weightLoss; set Patients; BY PatientID; retain startDate startWeight; / * RETAIN the start values * / if FIRST.PatientID dan doen; startDate = Date; startWeight = Weight; / * onthoud de beginwaarden * / end; als laatste.PatientID do; endDate = Date; endWeight = Weight; elapsedDays = intck('day', startdatum, einddatum); /* verstreken tijd (in dagen) */ weightLoss = startgewicht - eindgewicht; /* weight loss */ AvgWeightLoss = weightLoss / elapsedDays; /* gemiddeld gewichtsverlies per dag */ output; /* output alleen de laatste record in elke groep */ end;run; proc print noobs; var PatientID elapsedDays startgewicht eindgewicht gewichtsverlies;loop;
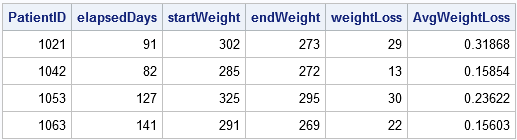
te berekenen de outputgegevensreeks geeft een overzicht van de activiteiten van elke patiënt in de kliniek, inclusief zijn gemiddeld gewichtsverlies en de duur van zijn behandeling.
sommige programmeurs denken dat de eerste.variabel en laatste.variabele indicator variabelen vereisen dat de gegevens worden gesorteerd, maar dat is niet waar. De tijdelijke variabelen worden gemaakt wanneer u een By-statement gebruikt in een GEGEVENSSTAP. U kunt de optie niet gesorteerd op het statement gebruiken om records te verwerken, ongeacht de sorteervolgorde.
samenvatting
samengevat worden in de GEGEVENSSTAP automatisch twee indicatorvariabelen aangemaakt. U kunt de variabelen gebruiken om de eerste en laatste record in elke groep te bepalen. Typisch de eerste.variabele indicator wordt gebruikt om samenvattende statistieken te initialiseren en om de initiële waarden van de meting te onthouden.De laatste.variabele indicator wordt gebruikt om het resultaat van de berekeningen, die vaak eenvoudige beschrijvende statistieken zoals een som, verschil, maximum, minimum, of gemiddelde waarden.
verwerking per groep in de GEGEVENSSTAP is een veelvoorkomend onderwerp dat op SAS-conferenties wordt gepresenteerd. Sommige auteurs gebruiken FIRST.BY en LAST.BY als de naam van de indicator variabelen. Voor verdere lezing beveel ik het artikel “the Power of the BY Statement” aan (Choate And Dunn, 2007). SAS biedt ook verschillende voorbeelden over de verwerking per groep in de SAS-gegevensstap, waaronder de volgende:
- niet-ontbrekende waarden een per groep
- gebruik door groepen om gegevens van lang naar breed te transponeren
- selecteer een bepaald aantal waarnemingen boven aan elke per groep
Tags aan de slag Sas-programmering