mój artykuł o różnicy między zmiennymi klasowymi a zmiennymi BY w SAS skupił się na procedurach analitycznych SAS. Instrukcja BY jest jednak przydatna również w kroku danych SAS, gdzie służy do scalania zestawów danych i analizy danych na poziomie grupy. W przypadku użycia instrukcji BY w kroku dane krok dane tworzy dwie tymczasowe zmienne wskaźnika dla każdej zmiennej w instrukcji BY. Nazwy tych zmiennych są pierwsze.zmienna i ostatnia.zmienna, gdzie zmienna jest nazwą zmiennej w instrukcji BY. Na przykład, jeśli używasz instrukcji przez Seks, nazwy zmiennych wskaźnika są pierwsze.Seks i ostatnia.Seks.
ten artykuł podaje kilka przykładów użycia pierwszego.zmienna i ostatnia.zmienny wskaźnik zmienny do analizy grupy w kroku danych SAS.Pierwszy przykład pokazuje, jak obliczyć liczby i skumulowane kwoty dla każdej grupy. Drugi przykład pokazuje, jak obliczyć czas między pierwszą a ostatnią wizytą pacjenta w klinice, a także zmianę mierzonej ilości między pierwszą a ostatnią wizytą.przetwarzanie według grup na etapie danych jest podstawową operacją, która należy do zestawu narzędzi każdego programisty SAS.
użyj najpierw. i ostatni. zmienne do określenia wielkości grup
pierwszy przykład wykorzystuje dane z szarfy.Zestaw danych serca, który zawiera dane dla 5209 pacjentów w badaniu medycznym chorób serca. Dane są dystrybuowane za pomocą SAS. Następujący krok danych wyodrębnia zmienne Smoking_Status i Weight i sortuje dane według zmiennej Smoking_Status:
proc sort data=Sashelp.Heart (keep=Smoking_Status Weight) out=Heart; by Smoking_Status; run;
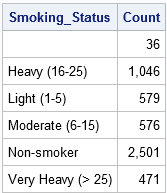
ponieważ dane są sortowane według zmiennej Smoking_Status, możesz użyć pierwszej.Smoking_Status i LAST.Smoking_Status zmienne tymczasowe do zliczania liczby obserwacji na każdym poziomie zmiennej Smoking_Status. (PROC FREQ oblicza te same informacje, ale nie wymaga posortowanych danych.) Podczas używania instrukcji by Smoking_Status, krok danych automatycznie tworzy pierwszy.Smoking_Status i LAST.Zmienne wskaźnika Smoking_Status. Jak sama nazwa wskazuje, pierwszy.Zmienna Smoking_Status ma wartość 1 dla pierwszej obserwacji w każdej grupie, a wartość 0 w przeciwnym razie.(Bardziej poprawnie, wartość wynosi 1 dla pierwszego rekordu i dla rekordów, dla których zmienna Smoking_Status jest inna niż dla poprzedniego rekordu.) Podobnie, ostatni.Zmienna wskaźnikowa Smoking_Status ma wartość 1 dla ostatniej obserwacji w każdej grupie I 0 w przeciwnym razie.
następujący krok danych definiuje zmienną o nazwie Count i inicjalizuje Count = 0 Na początku każdej z grup. Dla każdej obserwacji w grupie BY zmienna Count jest zwiększana o 1. Po odczytaniu ostatniego rekordu w każdej grupie, rekord ten jest zapisywany do zestawu danych Count.
Data Count; set Heart; / * dane są sortowane według Smoking_Status * / przez Smoking_Status; / * automatycznie tworzy zmienne wskaźnikowe * / if FIRST.Smoking_Status then Count = 0; / * zainicjalizuj liczenie na początku każdej grupy * / Count + 1; / * liczenie przyrostów dla każdego rekordu * / jeśli ostatni.Smoking_Status; / * wypisuje tylko ostatni rekord każdej grupy */run; proc print data=Count noobs; format Count przecinek10.; var Smoking_Status Count; run;
ta sama technika umożliwia gromadzenie wartości zmiennej w grupie. Na przykład można zgromadzić całkowitą masę wszystkich pacjentów w każdej grupie palących, korzystając z następujących stwierdzeń:
jeśli pierwszy.Smoking_Status then cumWt = 0; cumWt + Waga;
ta sama technika może być wykorzystana do gromadzenia przychodów z różnych źródeł, takich jak działy, sklepy lub regiony.
użyj najpierw. i ostatni. zmienne do obliczania czasu trwania leczenia
kolejne powszechne zastosowanie pierwszego.zmienna i ostatnia.zmienne wskaźnikowe mają na celu określenie czasu między pierwszą a ostatnią wizytą pacjenta. Rozważ następujący krok danych, który określa daty i wagi dla czterech pacjentów płci męskiej, którzy odwiedzili klinikę w ramach programu odchudzania:
dane pacjenci;Data informacji7.; format Data date7. PatientID Z4.;input PatientID data waga @@;datalines;1021 04Jan16 302 1042 06Jan16 2851053 07Jan16 325 1063 11Jan16 2911053 01feb16 299 1021 01Feb16 2881063 09Feb16 283 1042 16Feb16 2791021 07Mar16 280 1063 09mar16 2721042 28mar16 272 1021 04apr16 2731063 20apr16 270 1053 28apr16 2891053 13maj16 295 1063 31maj16 269;
w przypadku tych danych można sortować według identyfikatora pacjenta i daty wizyty. Po sortowaniu pierwszy zapis dla każdego pacjenta zawiera pierwszą wizytę w klinice, a ostatni zapis zawiera ostatnią wizytę. Możesz odjąć wagę pacjenta dla tych dat, aby określić, ile pacjent zyskał lub stracił podczas badania. Możesz również użyć funkcji INTCK, aby obliczyć upływ czasu między wizytami. Jeśli chcesz mierzyć czas w dniach, możesz po prostu odjąć daty, ale funkcja INTCK umożliwia obliczenie czasu trwania w kategoriach lat, miesięcy, tygodni i innych jednostek czasu.
proc sort data=Patients; by PatientID Date;run; data weightLoss; set Patients; BY PatientID; retain startDate startWeight; / * RETAIN the starting values * / if FIRST.PatientID następnie zrobić; startDate = Date; startWeight = Weight; / * zapamiętaj wartości początkowe */ end; jeśli ostatnia.PatientID then do; endDate = Date; endWeight = Weight; elapsedDays = intck('day', startDate, endDate); /* upłynął czas (w dniach) */ weightLoss = startWeight - endWeight; /* utrata wagi */ AvgWeightLoss = weightLoss / elapsedDays; /* średnia utrata masy ciała na dzień */ wyjście; /* wyjście tylko ostatni rekord w każdej grupie */ end;run; proc print noobs; var PatientID elapsedDays startweight endweight weightloss avgweightloss;Run;
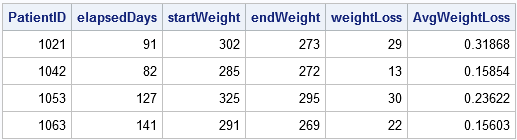
zestaw danych wyjściowych podsumowuje czynności każdego pacjenta w klinice, w tym jego średnią utratę wagi i czas trwania leczenia.
niektórzy programiści uważają, że pierwszy.zmienna i ostatnia.zmienne wskaźnikowe wymagają sortowania danych, ale nie jest to prawdą. Zmienne tymczasowe są tworzone za każdym razem, gdy używasz instrukcji BY w kroku danych. Możesz użyć opcji NOTSORTED w instrukcji BY do przetwarzania rekordów niezależnie od kolejności sortowania.
podsumowanie
w podsumowaniu Instrukcja BY w kroku dane automatycznie tworzy dwie zmienne wskaźnika. Możesz użyć zmiennych do określenia pierwszego i ostatniego rekordu w każdej grupie. Zazwyczaj pierwszy.wskaźnik zmiennej służy do inicjalizacji statystyk podsumowania i zapamiętywania początkowych wartości pomiaru.Ostatni.wskaźnik zmienny służy do wyprowadzania wyniku obliczeń, który często zawiera proste statystyki opisowe, takie jak suma, różnica, maksymalne, minimalne lub średnie wartości.
przetwarzanie przez grupy w kroku danych jest częstym tematem, który jest prezentowany na konferencjach SAS. Niektórzy autorzy wykorzystują FIRST.BY oraz LAST.BY jako nazwa zmiennych wskaźnikowych. Do dalszej lektury polecam artykuł „the Power of The by Statement” (Choate and Dunn, 2007). SAS udostępnia również kilka próbek dotyczących przetwarzania grupowego na etapie danych SAS, w tym następujące:
- Przenieś brakujące wartości w dół a według grupy
- użyj grup do transpozycji danych z długich na szerokie
- wybierz określoną liczbę obserwacji z góry każdej grupy
Tagi pierwsze kroki Programowanie SAS